Database Principles
2 Relation Schema
-
关系型数据库的结构
关系(relation):表
元组(tuple):行
属性(attribute):列
域(domin):对于关系的每个属性,都存在一个允许取值的集合
关系的所有属性的域都是原子的,被看作是不可再分的单元
关系模式(relation schema):对于关系结构的抽象描述,由属性序列和各属性对应域组成
关系实例(relation instance):一个关系的特定实例
-
关系型数据库码(key)的分类
一个关系中没有两个元组在所有属性值上都相等
超码(super key):一个或多个属性的集合,可以唯一标识一个元组
候选码(candidate key) :最小超码,不包括无关紧要的属性
主码(primary key):用来在一个关系中区分不同元组的候选码
外码(primay key):一个关系模式 r1 可能在它的属性中包括另一个关系模式 r2 的主码,r1 称为外码依赖的参照关系,r2 称为外码依赖的被参照关系
参照性关系(referential integrity constraint):要求在参照关系中任意元组在特定属性上的取值必然等于被参照关系中某个元素在特定属性上的取值
-
关系查询语言
过程性语言:用户指导系统对数据库执行一系列操作以计算出结果,例如关系代数
非过程性语言:只需描述信息不用给出获取信息的具体方法,例如关系演算TRC、域关系演算DRC、SQL
-
关系代数运算的基本操作
-
选择(select) $\sigma$
查询满足给定条件的元组(从行的角度)

-
投影(project) $\Pi$
选出若干属性列组成新的关系(从列的角度)
投影之后会取消重复的行

-
并(union) $\cup$
先并再去重
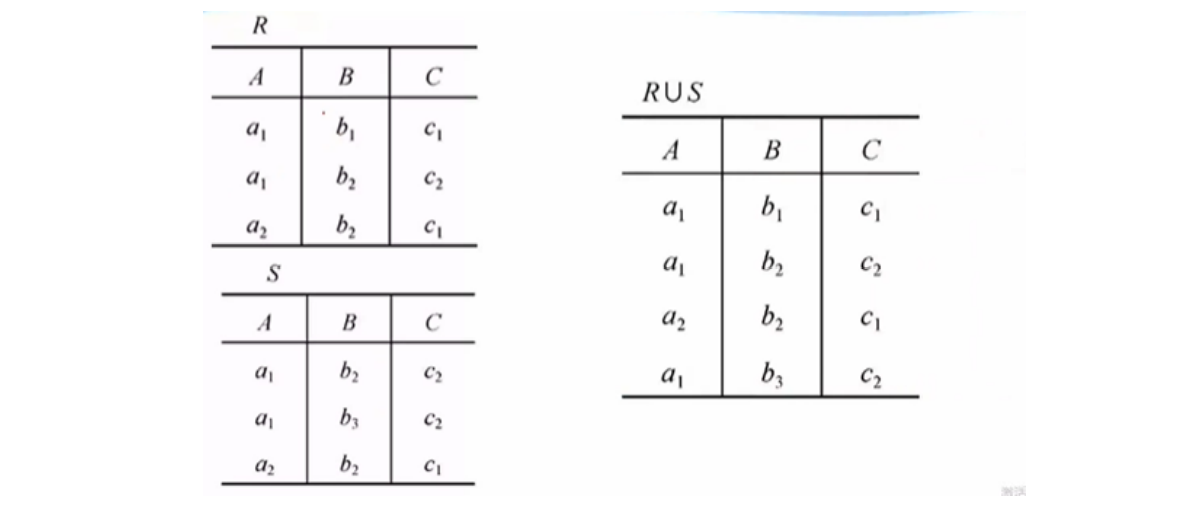
-
交(set intersection) $\cap$
两个表都有的元组

-
差(set difference) -
R 有但 S 没有的关系元组

-
笛卡尔积(Cartesian product) ×

-
自然连接(natural join) $\bowtie$
从两个关系的笛卡尔积中,基于两个关系模式中都出现的属性上的相等性进行选择,最后去掉重复的列

-
除(division) ÷
保留R中满足S的,而且R中列要去掉S的列

-
改名(rename) $\rho$
$\rho _{x(A1,A2,…An)}(E)$
返回表达式E的结果,并赋给它名字x,同时将各属性更名为A1,A2,…An
例子:找出大学里的最高工资

-
赋值(assignment) ←

对于关系代数查询而言,赋值必须是赋给一个临时关系变量,对永久关系的赋值形成了对数据库的修改。
注意:赋值运算不能增强关系代数的表达能力,但是可以使复杂查询的表达变得简单
- 扩展的关系运算
-
广义投影 (Generalized Projection)

-
聚集 (Aggregate Functions) $\mathcal{G}$

-
内连接/外连接
内连接(Inner Join):两个关系做自然连接时,连接的结果时满足条件的元组保留下来,不满足条件的元组被舍弃了
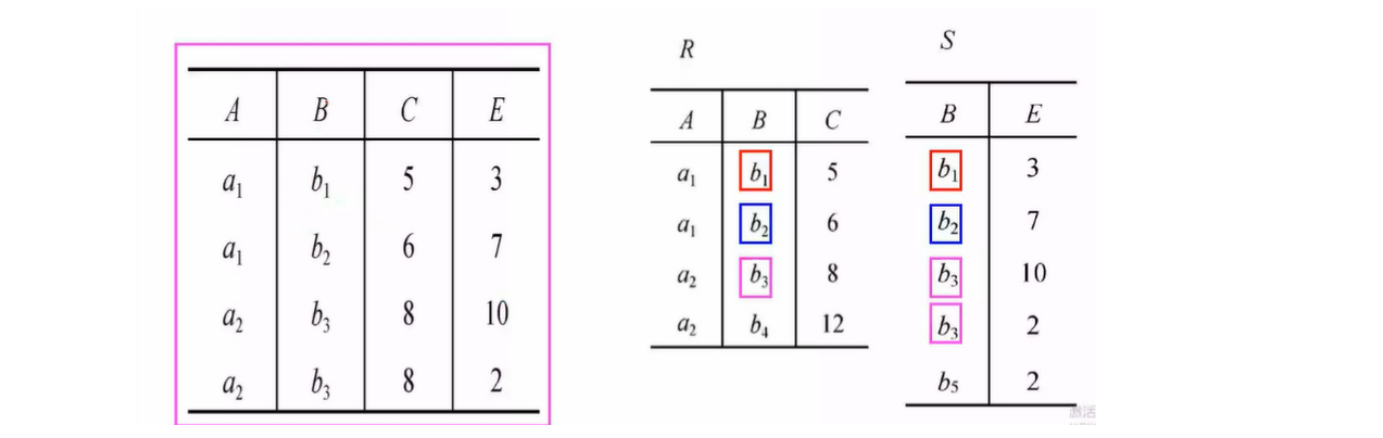
外连接(Outer Join):如果把舍弃的元组也保留再结果关系中,而在其他属性上填null,叫做外连接
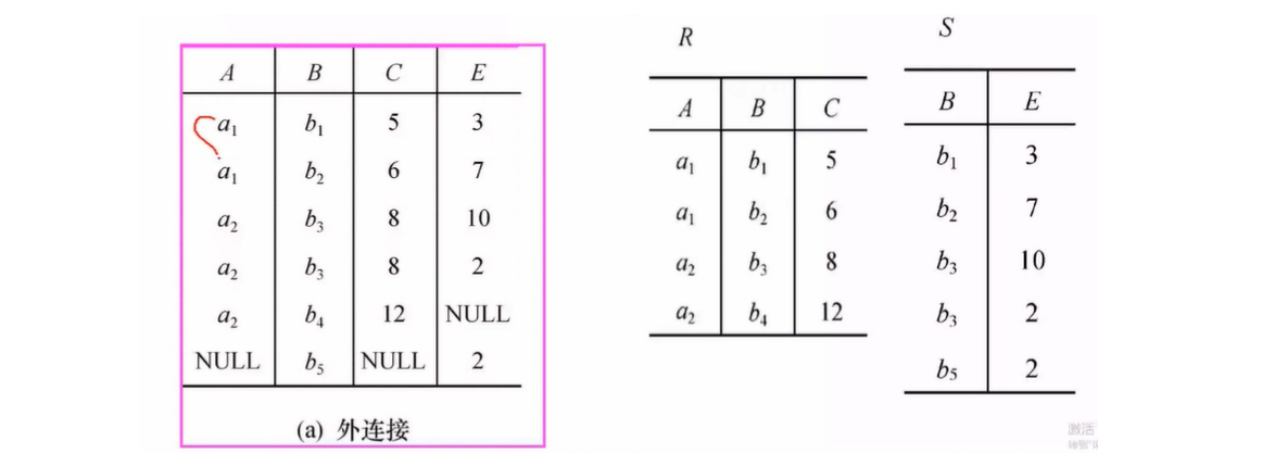
外连接分为左外连接和右外连接
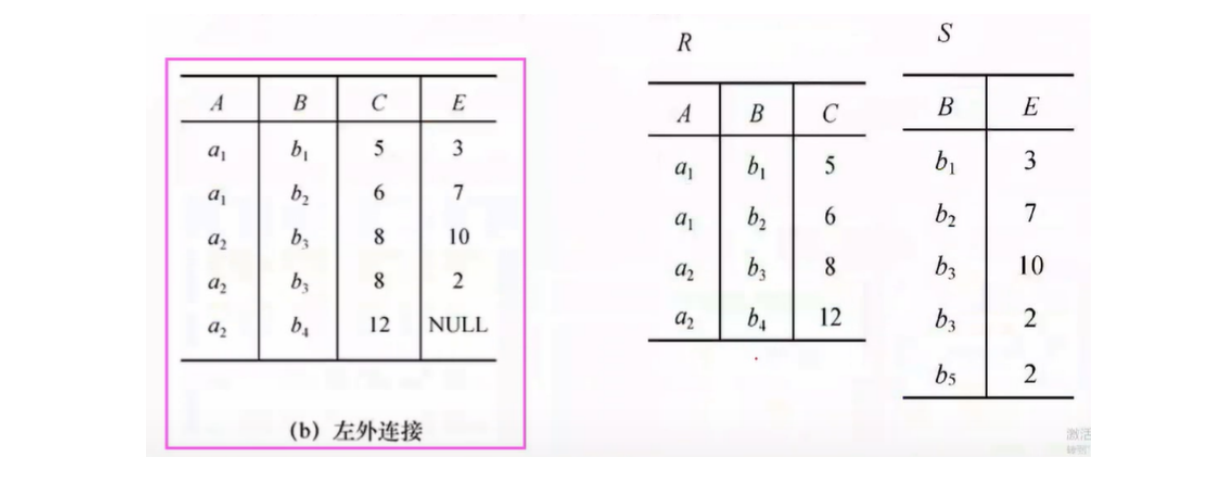
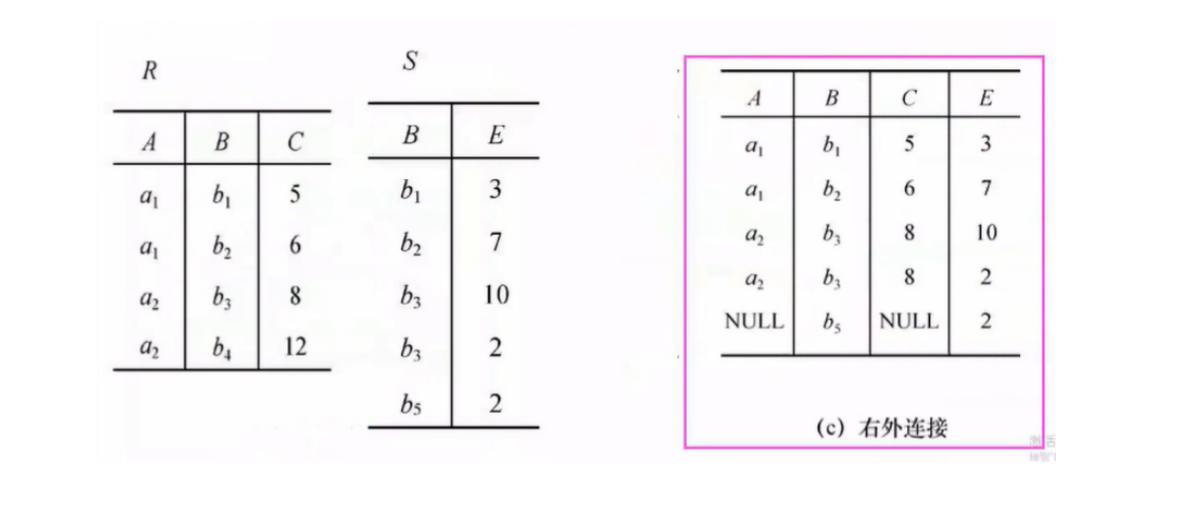
- 课堂例题




-
-
关系代数运算的扩展操作
-
广义投影 (Generalized Projection)
-
聚集 (Aggregate Functions) $\mathcal{G}$
-
内连接/外连接
内连接(Inner Join):两个关系做自然连接时,连接的结果时满足条件的元组保留下来,不满足条件的元组被舍弃了
外连接(Outer Join):如果把舍弃的元组也保留再结果关系中,而在其他属性上填null,叫做外连接
外连接分为左外连接和右外连接
-
-
关系代数练习
-
数据库的 schema 是指什么
schema 是元数据的一个抽象集合,包含一套 schema component: 主要是元素与属性的声明、复杂与简单数据类型的定义
数据库 schema 就是 :表,列,数据类型,视图,存储过程,关系,主键,外键等
-
课后简答题
-
设计数据库的步骤

-
List four significant differences between a file-processing system and a DBMS(database management system)
- 这两个系统都包含一个数据集合和一组访问该数据的程序。数据库管理系统同时协调对数据的物理和逻辑访问,而文件处理系统只协调物理访问
- 数据库管理系统通过确保物理数据适合所有被授权访问它的程序来减少重复数据量,而文件处理系统中由一个程序写入的数据可能不会被另一个程序读取
- 数据库管理系统设计为允许灵活访问数据(即查询),而文件处理系统设计为允许对数据的预定义访问(即编译程序)
- 一个数据库管理系统被设计用于协调多个用户同时访问同一数据。文件处理系统通常被设计为允许一个或多个程序同时访问不同的数据文件。在文件处理系统中,只有当两个程序都可以只读访问该文件时,两个程序才能同时访问一个文件



-
List three major disadvantages

-
DML 和 DDL 的区别

-
物理数据独立性
物理数据独立性使物理模式可以在应用程序丝毫不受影响的情况下被修改
这些修改包括将无阻塞记录存储更改为阻塞记录存储,或将顺序访问更改为随机访问
物理数据独立是指:应用程序不依赖于物理模式。如果修改了物理模式,能够保持 逻辑模式和应用程序不受影响,也就是说应用程序不受影响。保证了数据与程序的 物理独立性,简称数据的物理独立性。
-
3 SQL Basic
https://www.w3school.com.cn/sql/index.asp
SQL:结构化查询语言,是用于访问和处理数据库的标准的计算机语言
-
DML & DDL
SQL 是用于执行查询的语法,SQL 语言也包含用于更新、插入和删除记录的语法。可以把 SQL 分为两个部分:数据操作语言 DML 和数据定义语言 DDL
Data Manipulation Language:查询和更新指令构成了 SQL 的 DML 部分
- SELECT - 从数据库表中获取数据
- UPDATE - 更新数据库表中的数据
- DELETE - 从数据库表中删除数据
- INSERT INTO - 向数据库表中插入数据
Data Definition Language:SQL 的 DDL 部分使我们有能力创建或删除表格。我们也可以定义索引(键),规定表之间的链接,以及施加表间的约束。SQL 中最重要的 DDL 语句:
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
-
基本数据类型
- char(n) 固定长度字符串
- varchar(n) 可变长度字符串
- int 整数
- smallint 小整数
- numberic(p,d) 定点数,p位数字,其中d位在小数点右边
- real, double, precision:浮点数与双精度浮点数
- float(n) 精度至少为n的浮点数
-
创建表格 create table
语法:
CREATE TABLE 表名称 ( 列名称1 数据类型, 列名称2 数据类型, 列名称3 数据类型, .... )数据类型(data_type)规定了列可容纳何种数据类型,下面的表格包含了SQL中最常用的数据类型:
数据类型 描述 integer(size) int(size) smallint(size) tinyint(size) 仅容纳整数 在括号内规定数字的最大位数 decimal(size,d) numeric(size,d) 容纳带有小数的数字 “size” 规定数字的最大位数 “d” 规定小数点右侧的最大位数 char(size) 容纳固定长度的字符串 (可容纳字母、数字以及特殊字符) 在括号中规定字符串的长度 varchar(size) 容纳可变长度的字符串 (可容纳字母、数字以及特殊的字符) 在括号中规定字符串的最大长度 date(yyyymmdd) 容纳日期 举例:
CREATE TABLE Persons ( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), UNIQUE (Id_P), CHECK (Id_P>0), PRIMARY KEY (Id_P), FOREIGN KEY (Id_P) REFERENCES Persons ) -
创建视图 create view
create view name as <query expression> -
操作表格的列 alert table
ALTER TABLE 语句用于在已有的表中添加、修改或删除列
添加列:
ALTER TABLE table_name ADD column_name datatype改变数据类型:
ALTER TABLE table_name ALTER COLUMN column_name datatype删除列:
ALTER TABLE table_name DROP COLUMN column_name -
表格属性的约束类型
约束用于限制加入表的数据的类型
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后也可以(通过 ALTER TABLE 语句)我们将主要探讨以下几种约束:
- NOT NULL:约束强制列不接受 NULL 值
- UNIQUE:约束唯一标识数据库表中的每条记录,UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证
- PRIMARY KEY:约束唯一标识数据库表中的每条记录。主键必须包含唯一的值,主键列不能包含 NULL 值。每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束
- FOREIGN KEY: 一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY
- CHECK:约束用于限制列中的值的范围,如果对单个列定义 CHECK 约束,那么该列只允许特定的值。如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限制
- DEFAULT:
-
数据操作 update, insert, delete
INSERT
用于向表格中插入新的行
语法:
INSERT INTO table_name VALUES (value1, value2,....) INSERT INTO table_name (列1, 列2,...) VALUES (value1, value2,....)举例:
LastName FirstName Address City Carter Thomas Changan Street Beijing - 加入新的行,INSERT INTO Persons VALUES (‘Gates’, ‘Bill’, ‘Xuanwumen 10’, ‘Beijing’):
LastName FirstName Address City Carter Thomas Changan Street Beijing Gates Bill Xuanwumen 10 Beijing - 在指定的列中插入数据,INSERT INTO Persons (LastName, Address) VALUES (‘Wilson’, ‘Champs-Elysees’)
LastName FirstName Address City Carter Thomas Changan Street Beijing Gates Bill Xuanwumen 10 Beijing Wilson Champs-Elysees
UPDATE
语句用于修改表中的数据
语法:
UPDATE table_name SET column_name = 新值 WHERE column_name = 某值举例:
LastName FirstName Address City Gates Bill Xuanwumen 10 Beijing Wilson Champs-Elysees - 为 lastname 是 “Wilson” 的人添加 firstname,UPDATE Person SET FirstName = ‘Fred’ WHERE LastName = ‘Wilson’:
LastName FirstName Address City Gates Bill Xuanwumen 10 Beijing Wilson Fred Champs-Elysees - 更新某一行中的若干列,我们会修改地址,并添加城市名称,UPDATE Person SET Address = ‘Zhongshan 23’, City = ‘Nanjing’ WHERE LastName = ‘Wilson’:
LastName FirstName Address City Gates Bill Xuanwumen 10 Beijing Wilson Fred Zhongshan 23 Nanjing
DELETE
DELETE 语句用于删除表中的行
语法:
DELETE FROM table_nale WHERE column_name = 某值 DELETE FROM table_name // 不删除表的情况下删除所有的行 DELETE * FROM table_name // 不删除表的情况下删除所有的行举例:
LastName FirstName Address City Gates Bill Xuanwumen 10 Beijing Wilson Fred Zhongshan 23 Nanjing - “Fred Wilson” 会被删除,DELETE FROM Person WHERE LastName = ‘Wilson’:
LastName FirstName Address City Gates Bill Xuanwumen 10 Beijing - 删除所有的行,DELETE FROM person
- 加入新的行,INSERT INTO Persons VALUES (‘Gates’, ‘Bill’, ‘Xuanwumen 10’, ‘Beijing’):
-
创建索引和删除 create index, drop index/table/database
1.CREATE INDEX
在表中创建索引,以便更加快速高效地查询数据。用户无法看到索引,它们只能被用来加速搜索/查询
注意事项:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引
语法:
// 在表上创建一个简单的索引,允许使用重复的值 CREATE INDEX index_name ON table_name (column_name) // 如果希望以降序索引某个列中的值,在列名称之后添加保留字 DESC CREATE INDEX Index_name ON table_name (column_name DESC) // 多个索引列 CREATE INDEX index_name ON table_name (column1, column2) // 创建一个唯一的索引,意味着两个行不能拥有相同的索引值 CREATE UNIQUE INDEX index_name ON table_name (column_name)2.DROP INDEX
我们可以使用 DROP INDEX 命令删除表格中的索引
ALTER TABLE table_name DROP INDEX index_name DROP TABLE 表名称 DROP DATABASE 数据库名称如果我们仅仅需要除去表内的数据,但并不删除表本身,那么我们该如何做呢?请使用 TRUNCATE TABLE 命令
TRUNCATE TABLE 表名称 -
单个关系表查询 select, where, distinct
- SELECT
语法:
SELECT 列名称 FROM 表名称 SELECT * FROM 表名称举例:
针对下列表格
Id LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York 3 Carter Thomas Changan Street Beijing -
执行 SELECT LastName,FirstName FROM Persons,获取名为 “LastName” 和 “FirstName” 的列的内容:
LastName FirstName Adams John Bush George Carter Thomas -
执行 SELECT * FROM Persons,获取表中选取所有的列:
Id LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York 3 Carter Thomas Changan Street Beijing -
WHERE
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句
语法:
SELECT 列名 FROM 表名 WHERE 列 运算符 值操作符 描述 操作符 描述 = 等于 >= 大于等于 <> 或者 ! = 不等于 <= 小于等于 > 大于 BETWEEN 在某个范围内 < 小于 LIKE 搜索某种模式 举例:
LastName FirstName Address City Year Adams John Oxford Street London 1970 Bush George Fifth Avenue New York 1975 Carter Thomas Changan Street Beijing 1980 Gates Bill Xuanwumen 10 Beijing 1985 执行 SELECT * FROM Persons WHERE City=‘Beijing’
LastName FirstName Address City Year Carter Thomas Changan Street Beijing 1980 Gates Bill Xuanwumen 10 Beijing 1985 - DISTINCT
关键词 DISTINCT 用于返回唯一不同的值
语法:
SELECT DISTINCT 列名称 FROM 表名称举例:
Company OrderNumber IBM 3532 W3School 2356 Apple 4698 W3School 6953 在 company 中,W3School 被列出了两次,如需从 Company 列中仅选取唯一不同的值,执行 SELECT DISTINCT Company FROM Orders:
Company IBM W3School Apple -
where 中的限定符 in, between, like
- IN
IN 操作符允许我们在 WHERE 子句中规定多个值
语法:
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...)举例:
Id LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York 3 Carter Thomas Changan Street Beijing 从上表中选取姓氏为 Adams 和 Carter 的人
SELECT * FROM Persons WHERE LastName IN ('Adams','Carter')Id LastName FirstName Address City 1 Adams John Oxford Street London 3 Carter Thomas Changan Street Beijing - BETWEEN
操作符 BETWEEN … AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期
语法:
SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2举例:
Id LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York 3 Carter Thomas Changan Street Beijing 4 Gates Bill Xuanwumen 10 Beijing -
以字母顺序显示介于 “Adams”(包括)和 “Carter”(不包括)之间的人
SELECT * FROM Persons WHERE LastName BETWEEN 'Adams' AND 'Carter'Id LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York -
如需使用上面的例子显示范围之外的人,请使用 NOT 操作符
SELECT * FROM Persons WHERE LastName NOT BETWEEN 'Adams' AND 'Carter'Id LastName FirstName Address City 3 Carter Thomas Changan Street Beijing 4 Gates Bill Xuanwumen 10 Beijing -
LIKE
like 操作符用于在 WHERE 子句中搜索列中的指定模式
语法:
SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。SQL 通配符必须与 LIKE 运算符一起使用。在 SQL 中,可使用以下通配符:
通配符 描述 % 代表零个或多个字符 _ 仅替代一个字符 [charlist] 字符列中的任何单一字符 [^charlist] or [!charlist] 不在字符列中的任何单一字符 举例:
-
我们希望从上面的 “Persons” 表中选取居住在以 “N” 开始的城市里的人
SELECT * FROM Persons WHERE City LIKE 'N%' -
我们希望从 “Persons” 表中选取居住在以 “g” 结尾的城市里的人
SELECT * FROM Persons WHERE City LIKE '%g' -
我们希望从 “Persons” 表中选取居住在包含 “lon” 的城市里的人
SELECT * FROM Persons WHERE City LIKE '%lon%' -
通过使用 NOT 关键字,我们可以从 “Persons” 表中选取居住在不包含 “lon” 的城市里的人
SELECT * FROM Persons WHERE City NOT LIKE '%lon%' -
我们希望从上面的 “Persons” 表中选取名字的第一个字符之后是 “eorge” 的人
SELECT * FROM Persons WHERE FirstName LIKE '_eorge' -
我们希望从 “Persons” 表中选取的这条记录的姓氏以 “C” 开头,然后是一个任意字符,然后是 “r”,然后是一个任意字符,然后是 “er”
SELECT * FROM Persons WHERE LastName LIKE 'C_r_er' -
们希望从上面的 “Persons” 表中选取居住的城市以 “A” 或 “L” 或 “N” 开头的人
SELECT * FROM Persons WHERE City LIKE '[ALN]%' -
我们希望从上面的 “Persons” 表中选取居住的城市不以 “A” 或 “L” 或 “N” 开头的人
SELECT * FROM Persons WHERE City LIKE '[!ALN]%
-
多个关系表查询 cross join, natural join
FROM 后面接两个表表示笛卡尔积

-
找出所有教师的名字,以及他们所在系的名称和系所在的建筑
select name, instructor.dept_name, building from instructor, department where instructor.dept_name = department.dept_name
-
找出计算机系的教师名和课程标识
select name, course_id from instructor, teaches where instructor.id = teachrs.id and instructor.dept_name = 'Comp. Sci'
Natural Join 表示自然连接
自然连接(natural join)不同于两个关系上的笛卡儿积將第一个关系的每个元组与第二个关系的所有元组都进行连接。自然连接只考虑那些在两个关系模式中都出现的属性上取值相同的元组对。因此,回到 instructor 和 reaches 关系的例子上,instnuctor 和 teaches 的自然连接计算中只考虑这样的元组对:来自instructor 的元组和来自 teaches 的元组在共同属性 id 上的取值相同
-
找出所有教师的名字,以及他们所在系的名称和系所在的建筑,上面这道题的答案,可以简化改成
select name, course_id from instructor natural join teaches -
列出教师的名字和他们所讲授的课程的名称
select name, title from instructor natural join teaches, course where teaches.course_id = course.course_id这里不能用连续的自然连接:
select name, title from instructor natural join teaches natural join course因为注意 instructor 和 teaches 的自然连接包括属性
(ID, name, dept_name, salary, course_id, sec_id)
而 course 关系包含的属性是
(course_id, title, dept_rame, credits)
作为这二者自然连接的结果,需要来自这两个输人的元组既要在属性 dept_name 上取值相同,还要在 course_id 上取值相同。该查询将忽略所有这样的(教师姓名,课程名称)对:其中教师所讲授的课程不是他所在系的课程,而前一个查询会正确输出这样的对
所以,为了发扬自然连接的优点,同时避免不必要的相等属性带来的危险,SQL 提供了一种自然连接的 using 构造形式,允许用户来指定需要哪些列相等
select name, title from (instructor natural join teaches) join course using (course_id)
-
-
自然连接 join, inner, left, right, full
Join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 Join
下面是可以使用的 join 类型,以及它们之间的差异:
- JOIN = INNER JOIN: 在表中存在至少一个匹配时,返回行
- LEFT JOIN: 会从左表那里返回所有的行,即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 会从右表那里返回所有的行,即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
1.JOIN
在表中存在至少一个匹配时,返回行
语法:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name举例:
Persons 表:
Id_P LastName FirstName Address City 1 Adams John Oxford Street London 2 Bush George Fifth Avenue New York 3 Carter Thomas Changan Street Beijing Orders 表:Orders 表中的 Id_P 列用于引用 Persons 表中的人,而无需使用他们的确切姓名
Id_O OrderNo Id_P 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 65 -
我们可以通过引用两个表的方式,从两个表中获取数据,从而知道谁订购了产品,并且他们订购了什么产品
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons, Orders WHERE Persons.Id_P = Orders.Id_P -
除了上面的方法,我们也可以使用关键词 JOIN 来从两个表中获取数据
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons INNER JOIN Orders ON Persons.Id_P = Orders.Id_P ORDER BY Persons.LastNameLastName FirstName OrderNo Adams John 22456 Adams John 24562 Carter Thomas 77895 Carter Thomas 44678
2.LEFT JOIN
会从左表那里返回所有的行,即使右表中没有匹配,也从左表返回所有的行
语法:
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name举例:
还是上面的 person,order 表格,现在,我们希望列出所有的人,以及他们的定购——如果有的话
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons LEFT JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastNameLastName FirstName OrderNo Adams John 22456 Adams John 24562 Carter Thomas 77895 Carter Thomas 44678 Bush George LEFT JOIN 关键字会从左表 (Persons) 那里返回所有的行,即使在右表 (Orders) 中没有匹配的行
3.RIGHT JOIN
会从右表那里返回所有的行,即使左表中没有匹配,也从右表返回所有的行
语法:
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name举例:
还是上面的 person,order 表格,我们希望列出所有的定单,以及定购它们的人——如果有的话
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons RIGHT JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastNameLastName FirstName OrderNo Adams John 22456 Adams John 24562 Carter Thomas 77895 Carter Thomas 44678 34764 4.FULL JOIN
只要其中一个表中存在匹配,就返回行
语法:
SELECT column_name(s) FROM table1 FULL JOIN table2 ON table1.column_name=table2.column_name举例:
还是上面的 person,order 表格,我们希望列出所有的人,以及他们的定单,以及所有的定单,以及定购它们的人
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons FULL JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastNameLastName FirstName OrderNo Adams John 22456 Adams John 24562 Carter Thomas 77895 Carter Thomas 44678 Bush George 34764 -
附加的基本运算 as, upper, lower, trim, %
- 更名运算 as
对大学中所有讲授的课程的教师,找出他们的姓名以及所讲述的所有课程标识
select T.name, S.course_id from instructor as T, teaches as S where T.id = S.id- 字符串运算
全部转换大小写
upper(s) 全部转换为大写 lower(s) 全部转换为小写 trim(s) 去掉字符串后面的空格字符串模式匹配
百分号 %:匹配任意子串 下划线 _:匹配任意一个字符 **下面是例子说明** 'Intro%':匹配任何以 Intro 开头的字符串 '%Comp%':匹配任何包含 Comp 的字符串 '___':匹配只含三个字符的字符串 '___%':匹配至少含三个字符的字符串在sql语句中用 like 来表达模式匹配
select dept_name from department where building like '%Watson%'在sql语句中用 escape 来表达转义字符
like 'ab\%cd%' escape '\' 表示匹配所有以 ab%cd 开头的字符串 -
分组查询 order by, group by, having
- ORDER BY
order by 语句用于根据指定的列对结果集进行排序。order by 语句默认按照升序对记录进行排序。如果希望按照降序对记录进行排序,可以使用 DESC 关键字
举例:
Company OrderNumber IBM 3532 W3School 2356 Apple 4698 W3School 6953 -
以字母顺序显示公司名称,SELECT Company, OrderNumber FROM Orders ORDER BY Company (ASC by default) :
Company OrderNumber Apple 4698 IBM 3532 W3School 6953 W3School 2356 -
以字母顺序显示公司名称,如果有重复的公司名称,以数字从小到大的顺序显示,SELECT Company, OrderNumber FROM Orders ORDER BY Company, OrderNumber
Company OrderNumber Apple 4698 IBM 3532 W3School 2356 W3School 6953 -
以逆字母顺序显示公司名称,如果有重复的公司名称,以数字从小到大的顺序显示,SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC, OrderNumber ASC
Company OrderNumber W3School 2356 W3School 6953 IBM 3532 Apple 4698 -
GROUP BY
用于结合合计函数(比如 SUM),根据一个或多个列对结果集进行分组,在 group by 后面子句中的所有属性上取值相同的元组被分在一个组中
SELECT column_name, 合计函数(column_name) FROM table_name WHERE column_name 操作符 某值 GROUP BY column_name举例:
O_Id OrderPrice Customer 1 1000 Bush 2 1600 Carter 3 700 Bush 4 300 Bush 5 2000 Adams 6 100 Carter -
我们希望查找每个客户的总金额
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY CustomerCustomer SUM(OrderPrice) Bush 2000 Carter 1700 Adams 2000 -
看看如果省略 GROUP BY 会出现什么情况
SELECT Customer,SUM(OrderPrice) FROM OrdersCustomer SUM(OrderPrice) Bush 5700 Carter 5700 Bush 5700 Bush 5700 Adams 5700 Carter 5700 -
找出每个系的平均工资
select dept_name, avg(salary) as avg_salary from instructor group by dept_name -
找出每个系在2010年春季学期讲授一门课程的教师人数
select dept_name, count(distinct ID) as instr_count from instructor natural join teaches where semester = 'Spring' and year = 2010 group by dept_name
3.Having
用于对 group by 之后的分组限定条件,而不是对单个的元组限定条件。注意区别一下 having 跟 where 用法的区别!
-
查找出教师平均工资超过 42000 美元的系
select dept_name, avg(salary) as avg_salary from instructor group by dept_name having avg(salary) > 42000 -
对于在2009年讲授的每个课程段,如果该课程段至少有2名学生选课,找出选修该课程段的所有学生的总学分的平均值
select course_id, semester, year, sec_id, avg(tot_cred) from takes natural join student where year = 2000 group by course_id, semester, year, sec_id having count(ID) >= 2
-
集合运算 union, union all, intersect, intersect all, except, except all
集合运算用于合并不同表格的相同列
1.UNION
UNION 操作符用于合并两个或多个 SELECT 语句的结果集
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同
UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL
语法:
SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2举例:
Employees_China 表:
E_ID E_Name 01 Zhang, Hua 02 Wang, Wei 03 Carter, Thomas 04 Yang, Ming Employees_USA:
E_ID E_Name 01 Adams, John 02 Bush, George 03 Carter, Thomas 04 Gates, Bill 列出所有在中国和美国的不同的雇员名
SELECT E_Name FROM Employees_China UNION SELECT E_Name FROM Employees_USAE_Name Zhang, Hua Wang, Wei Carter, Thomas Yang, Ming Adams, John Bush, George Gates, Bill 注意:这个命令无法列出在中国和美国的所有雇员。在上面的例子中,我们有两个名字相同的雇员 Carter, Thomas ,他们当中只有一个人被列出来了。UNION 命令只会选取不同的值
2.UNION ALL
还是上面的两个表格,列出在中国和美国的所有的雇员:
SELECT E_Name FROM Employees_China UNION ALL SELECT E_Name FROM Employees_USAE_Name Zhang, Hua Wang, Wei Carter, Thomas Yang, Ming Adams, John Bush, George Carter, Thomas Gates, Bill 3.Intersect
简介:交运算,自动去除重复的
例子:找出在2009年秋季和2010年春季同时开课的所有课程的合集
(select course_id from section where semester = 'Fall' and year = 2009 ) intersect (select course_id from section where semester = 'Spring' and year = 2010 )4.Intersect All
简介:交运算,会保留重复的
例子:找出在2009年秋季和2010年春季同时开课的所有课程的合集
(select course_id from section where semester = 'Fall' and year = 2009 ) intersect all (select course_id from section where semester = 'Spring' and year = 2010 )5.except
简介:差运算,自动去除重复的
例子:找出在2009年秋季学期开课,但不再2010年春季学期开课的所有课程
(select course_id from section where semester = 'Fall' and year = 2009 ) except (select course_id from section where semester = 'Spring' and year = 2010 )6.except all
简介:差运算,不去除重复的
例子:找出在2009年秋季学期开课,但不再2010年春季学期开课的所有课程
(select course_id from section where semester = 'Fall' and year = 2009 ) except all (select course_id from section where semester = 'Spring' and year = 2010 ) -
聚集函数 avg, count, sum, max, min
1.AVG()
AVG 函数返回数值列的平均值,NULL 值不包括在计算中
语法:
SELECT AVG(*column_name*) FROM *table_name*举例:
O_Id OrderPrice Customer 1 1000 Bush 2 1600 Carter 3 700 Bush 4 300 Bush 5 2000 Adams 6 100 Carter -
我们希望计算 “OrderPrice” 字段的平均值
SELECT AVG(OrderPrice) AS OrderAverage FROM OrdersOrderAverage 950 -
我们希望找到 OrderPrice 值高于 OrderPrice 平均值的客户
SELECT Customer FROM Orders WHERE OrderPrice> (SELECT AVG(OrderPrice) FROM Orders)Customer Bush Carter Adams -
找出计算机系教师的平均工资
select avg(salary) as avg_salary from instructor where dept_name = 'Comp.Sci'
2. COUNT()
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入)
语法:
SELECT COUNT(column_name) FROM table_name SELECT COUNT(*) FROM table_name SELECT COUNT(DISTINCT column_name) FROM table_name举例:
O_Id OrderPrice Customer 1 1000 Bush 2 1600 Carter 3 700 Bush 4 300 Bush 5 2000 Adams 6 100 Carter -
希望计算客户 “Carter” 的订单数
SELECT COUNT(Customer) AS CustomerNilsen FROM Orders WHERE Customer='Carter'以上 SQL 语句的结果是 2,因为客户 Carter 共有 2 个订单
CustomerNilsen 2 -
如果我们省略 WHERE 子句
SELECT COUNT(*) AS NumberOfOrders FROM Orders结果为 6,这是表中的总行数
NumberOfOrders 6 -
我们希望计算 “Orders” 表中不同客户的数目
SELECT COUNT(DISTINCT Customer) AS NumberOfCustomers FROM Orders结果为 3,这是 “Orders” 表中不同客户(Bush, Carter 和 Adams)的数目
NumberOfCustomers 3 -
找出在2010年春季学期讲授一门课程的教师总数
select count(distinct ID) from teaches where semester = 'Spring' and year = 2010 -
找出每个系在2010年春季学期讲授一门课程的教师人数
select dept_name, count(distinct ID) as instr_count from instructor natural join teaches where semester = 'Spring' and year = 2010 group by dept_name
3.MAX()
MAX 函数返回一列中的最大值。NULL 值不包括在计算中
语法:
SELECT MAX(column_name) FROM table_name举例:
O_Id OrderDate OrderPrice Customer 1 2008/12/29 1000 Bush 2 2008/11/23 1600 Carter 3 2008/10/05 700 Bush 4 2008/09/28 300 Bush 5 2008/08/06 2000 Adams 6 2008/07/21 100 Carter -
我们希望查找 “OrderPrice” 列的最大值
SELECT MAX(OrderPrice) AS LargestOrderPrice FROM OrdersLargestOrderPrice 2000
4.SUM()
SUM 函数返回数值列的总数(总额)
语法:
SELECT SUM(column_name) FROM table_name举例:
我们希望查找 “OrderPrice” 字段的总数
SELECT SUM(OrderPrice) AS OrderTotal FROM OrdersOrderTotal 5700 -
6 Database Design and ER modal
-
E-R模型的三个要素
实体集、联系集、属性
- 实体(entity):在现实世界中存在并且区别于其他对象的事物或对象
- 实体集(entity set):相同类型即具有相同性质的实体集合,例如大学所有教师的集合instructor
- 联系(relationship):指多个实体间相互关联
- 联系集(relationship set):相同类型联系的集合
- 多元联系集:相同的实体集可能会参与到多个联系集中
- 实体属性:实体集中每个成员所拥有的描述性性质
- 描述性属性:例如考虑instructor和student之间的联系集advisor,可以将属性date与该联系关联
-
弱实体集的表示 week entity set
弱实体集(week entity set):实体集的所有属性都不足以形成主码
强实体集(strong entity set):具有主码的实体集
标识性联系(identifying):弱实体集必须与另一个称作标识或属主实体集的实体集关联才能有意义
注意:强实体与弱实体的标识性联系联系只能是1:1或1:N,弱实体参与联系时应该是全部参与
分辨符(discriminator):区分弱实体集中的实体的方法
弱实体集的主码由标识实体集的主码加上该弱实体集的分辨符构成
-
联系集的表示 relationship set
多对多的二元联系:该联系集属性自成一个关系,主码是参与实体集的主码的并集
一对多的二元联系:联系集的属性归到多的一方,少的一方的主码也要加到多的一方
一对一的二元联系:联系集的属性归到任意一方,另一方的主码也要加进去
-
例题一看就懂


7 Database Design Refinement
-
为什么要引入数据库范式
存储信息时避免不必要的冗余,并且可以让我们方便的获取信息
-
数据库四范式 ⭐
第一范式(1NF)
原子性,不可分割。确保每一列的原子性,如果每一列都是不可再分的最小数据单元


第二范式(2NF)
不存在非主属性对码的部分函数依赖
第三范式(3NF)
不存在非主属性对码的传递函数依赖,全码一定是3NF
BCNF 范式
主属性和非主属性都不存在对码的部分函数依赖和传递函数依赖。BCNF 消除了所有基于函数依赖能够发现的冗余,具有函数依赖集F的关系模式 R 属于 BCNF 的条件是,对 F+ 中所有形如 $\alpha \rightarrow \beta$ 的函数依赖下面至少有一项成立:$\alpha \rightarrow \beta$ 是平凡的函数依赖,或 $\alpha$ 是模式 R 的一个超码
第四范式(4NF)
关系模式 R 属于第三范式,且消除了非主属性对候选键以外属性的多值依赖
范式判断:
-
求候选键,和主属性/非主属性
-
非键属性是否部分依赖于候选键
部份依赖是指如果候选码是 AB,C 是非主属性,如果在 F 中找到 A→C 或者 B→C,就说明 C 直接依赖于 A 或者 B,也就是说 C 部分依赖于 AB
如果是:1NF
如果否:往下走
-
非键属性是否传递依赖于候选键
传递依赖有两个条件,一个是传递,B→A,A→C,其中 B 是候选键,C 是非主属性,二是不可逆,A!→B,A 不能推出 B
如果是:2NF
如果否:往下走
-
所有依赖项的左边是否全为候选键
如果是:BCNF
如果不是:3NF
-
-
如何判断满足哪些范式
-
求候选键,和主属性/非主属性
-
非键属性是否部分依赖于候选键
部份依赖是指如果候选码是AB,非键C,如果在F中找到A→C或者B→C,就是部分依赖
如果是:1NF
如果否:往下走
-
非键属性是否传递依赖于候选键
如果是:2NF
如果否:往下走
-
所有依赖项的左边是否全为候选键
如果是:BCNF
如果不是:3NF
-
-
各种码的概念
超码 (super key):能推出所有属性的属性集,唯一能够标识整条元组的属性集。R 的子集 K 是 r(R) 的超码的条件是:在关系 r(R) 的任意合法实例中,对于 r 的实例中的所有元组对 t1 和 t2 总满足,若 t1 != t2,则 t1[K] != t2[K]
候选码:可以推出所有的属性,但是他的任意一个真子集无法推出所有的属性,候选码是最小的超码
主码:从候选码中任意挑一个作为主码
主属性:包含在任意一个候选码中的属性
非主属性:不包含在任意一个候选码中的属性
码:把主码、候选码简称为码
全码:如果所有属性都是码,成为全码
-
求候选码的步骤 ⭐
step1:只出现在左边的一定是候选码
step2:只出现在右边的一定不是候选码
step3:左右都出现的不一定
step4:左右都不出现的一定是候选码
step5:求确定的候选码的闭包(closure,指由他可以推出来的所有属性),如果可以推出全部,那么当前确定的就是候选码。否则就把每个可能的码,放进当前确定的候选码里面进行求闭包

-
函数依赖的概念
-
函数依赖的闭包
-
函数依赖的 Armstrong 公理

-
求最小函数依赖集的步骤 ⭐
最小函数依赖集:即 F 中的每个依赖,都不可以被其他依赖推出
- 把左边的元素拆分成单个的
- 除去当前关系模式,求它的闭包,把集合里面所有关系一一排查
- 左边最小化(通过遮住元素来看能不能推出其他元素),比如BCD,遮住B看能不能推出B,再遮住C和D

-
判断是否保持函数依赖的步骤
- 无损连接性:具有无损连接性的分解不一定能够保持函数依赖
- 保持函数依赖:保持函数依赖的分解不一定具有无损连接性
对于关系模式 R(U,F),设 R1(U1, F1), R2(U1,F2), … Rn(Un, Fn) 是 R 的分解,若 F 的闭包等于 $F1\cup F2\cup …\cup Fn$ 的闭包,则称该分解是保持函数依赖

-
无损分解的概念 lossless decomposition
如果 R 分解为 R1 和 R2 之后,没有信息的损失,也就是说 R1 和 R2 通过自然连接之后还是等于 R,这就是一个无损分解
模式分解具有无损连接性的充分必要条件是:把一个关系模式分解为两个关系模式时,分解具有无损连接性,当且仅当两个关系模式的公共属性,是其中一个模式的键
$R1 \cap R2 \rightarrow R1 \in F \ or \ R1 \cap R2 \rightarrow R2 \in F$
其中 F 是 R 上的函数依赖集
-
判断是否为无损分解的步骤 ⭐
两个分解的关系判断无损分解:

多个分解的关系判断:二叉树法


-
求 3NF 分解的步骤
- 求候选码
- 求最小函数依赖集
- 把最小函数依赖集箭头前后的元素写在一起
-
求 BCNF 分解的步骤
- 求候选码
- 若所有关系模式都是 BCNF,直接转到步骤 5
- 找出第一个不是 BCNF 的关系模式,也就是箭头左侧的属性不是候选码
- 把这个关系模式从 F 中抽出来,作为一个新的关系 Ri,比如 BC → D,作为 R1(BCD)。然后把含有 Ri 中箭头这个右边的字母 D 的所有关系模式从 F 中抽出来扔掉,再从原来的关系里减去这个字母 D,作为新的关系 R(i+1),剩下的 F 里面的关系模式继续执行,转到步骤3
- 分解结束


13 storage
-
数据库管理系统的结构
- Query processing
- Storage manager
-
数据存储介质
- 高速缓存存储器 cache:最快最昂贵的,很小
- 主存储器 main memory:存放可处理的数据的存储介质,还是比较小,发生电源故障或者系统崩溃,内容容易丢失
- 快闪存储器 flash memory:在电源关闭的时候可以保存下来,有NAND和NOR快闪
- 磁盘存储器 magnetic disk storage:长期联机数据存储的主要介质,系统将数据从磁盘易到主存储器,在完成操作后修改过的数据必须写会磁盘
- 光学存储器 optical storage:光盘 compact disk,容纳 700MB 的数据
- 磁带存储器:比磁盘便宜,但访问也比磁盘慢很多,磁带是顺序访问,磁盘是直接访问的
比较:

-
数据存储介质分类
按照属性分:
- volatile storage 易失性存储:cache, main maemory
- non-volatile storage 非易失性存储
按照应用分:
- 基本存储
- 辅助存储,联机存储
- 三级存储,脱机存储
-
磁盘存储的特点 magnetic disk storage

盘面 platter:信息记录在盘面上
磁道 track:盘片表面一圈一圈的叫磁道,外侧的磁道比内侧的磁道拥有更多的扇区
扇区 sector:每个磁道划分为很多扇区,扇区是从磁盘读出和写入信息的最小单位,一般是512字节
读写头 read-write head:将信息磁化存储到扇区中
柱面 cylinder:所有盘片的第i条磁道合在一起成为第i歌柱面
-
磁盘存储性能的度量
- 容量 space
- 访问时间 access time:从发出读写请求到数据开始传输之间的时间,磁盘臂移动到正确的磁道,旋转到指定的扇区,是寻道时间+旋转等待时间的总和
- 寻道时间 seek time:磁盘臂重定位的时间
- 平均寻道时间:寻道时间的平均值,假设所有磁道包含相同的扇区数,大约是最长寻道时间的二分之一
- 旋转等待时间 rotation latency time:读写头找到磁道之后,等待旋转道访问的扇区的时间
- 数据传输率 data-transfer rate:从磁盘获得数据或者存储数据的速率,差不多25-100MB/s的最大传输率
- 平均故障时间 Mean time to faillur:我们可以期望系统无故障连续运行的时间量


-
磁盘访问的优化方法
- 缓存 buffer
- 预读 read ahead
- 调度 scheduling:磁盘臂调度,电梯算法
- 文件组织
- 非易失性写缓冲区
- 日记磁盘
-
独立磁盘冗余阵列 RAID
作用:通过冗余提高可靠性(奇偶校验),通过并行提高性能
磁盘阵列简称RAID(Redundant Array of Independent Disks)。磁盘阵列是由很多便宜、容量较小、稳定性较高、速度较慢磁盘,组合成一个大型的磁盘组,利用个别磁盘提供数据所产生的加成效果来提升整个磁盘系统的效能。同时,在储存数据时,利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任一颗硬盘故障时,仍可读出数据,在数据重构时,将故障硬盘内的数据,经计算后重新置入新硬盘中。而磁盘阵列柜就是装配了众多硬盘的外置的RAID 。
-
文件组织 file organization
什么是文件:数据存储在文件上,文件由很多个record构成,record由fields构成
文件组织定义:数据组织称记录、块、和访问结构的方式,包括把记录和块存储在磁盘上的方式,和记录和块之间相互联系的方式
-
可变长和不可变长记录 arable lenth record
-
文件记录组织 file records organization
- 堆文件组织 heap file:无序的,插入在尾部,删除在当下,然后加个删除标记
- 顺序文件组织 sequential file:按照属性的顺序插入,检索效率高,更新效率低
- 散列文件组织 hashing file:依据一个散列函数来计算存放的位置,检索效率和更新效率都提高
- 聚集文件组织 clustering file:将具有相似属性值的记录存放于连续的磁盘块中
-
数据库缓冲区管理 data buffer
原因:当buffer的空闲区不够,不能容下新读入的块,需要将buffer中原有的块覆盖
方法:
- 最近最少使用 LRU
- 最近最常使用 MRU
14 index and hash
-
索引的概念
-
MySQL 索引类型
1.普通索引:是最基本的索引,它没有任何限制。
CREATE INDEX index_name ON table(column(length)) ALTER TABLE table_name ADD INDEX index_name ( column ) DROP INDEX index_name ON table2.唯一索引:与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
CREATE UNIQUE INDEX indexName ON table(column(length)) ALTER TABLE table_name ADD UNIQUE ( column )3.主键索引:是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) NOT NULL , PRIMARY KEY (`id`) ); ALTER TABLE table_name ADD PRIMARY KEY ( column )4.组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
ALTER TABLE table_name ADD INDEX index_name ( column1, column2, column3 )5.全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多
// 1 修改表结构添加全文索引 ALTER TABLE table_name ADD FULLTEXT ( column) // 2 创建表的适合添加全文索引 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (content) ); // 3 直接创建索引 -
顺序索引和散列索引
顺序索引:基于值的顺序排序的
散列索引:基于将值平均分布道若干散列桶中
-
稠密索引和稀疏索引
稠密索引 Dense Index:对于主文件中每一个记录,都有一个对应的索引项

稀疏索引 Sparse Index:对于主文件中部分记录,有对应的索引项,只有索引是聚集索引(当关系按照搜索码排列顺序存储时)才能使用稀疏索引

-
聚集索引和非聚集索引
聚集索引 clustering index:包含记录的文件按照某个搜索码指定的顺序排序,该搜索码对应的索引成为聚集索引,也成为主索引,可以建立在主码和任何搜索吗上,主索引是稀疏索引,一个文件只可以创建一个聚集索引
非聚集索引 nonclustering index:搜索码指定的顺序与文件中记录的物理顺序不同的索引成为非聚集索引,也叫辅助索引,辅助索引是稠密索引
总结:
索引在搜索记录时提供了很大的好处。有序索引:密集索引;稀疏索引。辅助索引必须是密集的。使用主索引的顺序扫描是高效的。但是使用二级索引的顺序扫描开销很大。每个记录访问可能从磁盘获取一个新的块。当一个文件被修改时,文件上的每个索引都必须更新;更新索引会增加数据库修改的开销。
-
为什么要用 B+ 树索引
索引顺序文件的缺点:
性能随着文件的增长而下降,因为创建了许多溢出块。需要对整个索引文件进行定期重组。而B+树索引是索引顺序文件的另一种选择。
B+树索引文件的优点:
在面对插入和删除时,通过小的、局部的更改自动地重新组织自己。为了保持性能,不需要重组整个文件
B+树的缺点:
- 额外的插入和删除开销,2. 空间开销,B+树的优点大于缺点,它们被广泛使用
常见的索引类型:hash、b树、b+树
hash:底层就是 hash 表。进行查找时,根据 key 调用hash 函数获得对应的 hashcode,根据 hashcode 找到对应的数据行地址,根据地址拿到对应的数据。
B树:B树是一种多路搜索树,n 路搜索树代表每个节点最多有 n 个子节点。每个节点存储 key + 指向下一层节点的指针+ 指向 key 数据记录的地址。查找时,从根结点向下进行查找,直到找到对应的key。
B+树:B+树是b树的变种,主要区别在于:B+树的非叶子节点只存储 key + 指向下一层节点的指针。另外,B+树的叶子节点之间通过指针来连接,构成一个有序链表,因此对整棵树的遍历只需要一次线性遍历叶子结点即可
为什么MySQL数据库要用B+树存储索引?而不用红黑树、Hash、B树?
- 红黑树:如果在内存中,红黑树的查找效率比B树更高,但是涉及到磁盘操作,B树就更优了。因为红黑树是二叉树,数据量大时树的层数很高,从树的根结点向下寻找的过程,每读1个节点,都相当于一次IO操作,因此红黑树的I/O操作会比B树多的多。
- hash 索引:如果只查询单个值的话,hash 索引的效率非常高。但是 hash 索引有几个问题:1)不支持范围查询;2)不支持索引值的排序操作;3)不支持联合索引的最左匹配规则。
- B树索引:B树索相比于B+树,在进行范围查询时,需要做局部的中序遍历,可能要跨层访问,跨层访问代表着要进行额外的磁盘I/O操作;另外,B树的非叶子节点存放了数据记录的地址,会导致存放的节点更少,树的层数变高。
-
B+ 树的简介和特点
**简介:**B+ 树索引是一种多级索引,在数据插入和删除的情况下仍能保持其执行效率

**特点:**B+树是一棵满足以下性质的有 root tree
- 从根到叶的所有路径都具有相同的长度,是平衡树
- 每个既不是根的非叶节点的节点具有⌈n/2⌉~n的子节点
- 一个叶节点的值在⌈(n−1)/2⌉~n-1之间
- 特殊情况:如果根节点不是叶节点,则至少有2个子节点。如果根是叶节点,则它的值可以在 0~(n−1) 之间。

-
B+ 树的合成
就是从第一个节点加入到最后一个节点的过程,例题可以见下面的添加元素
-
B+ 树的查询
复杂度:查询的节点不超过 ⌈log_⌈n/2⌉(M)⌉ 个
例子:使用100万个搜索键值并且 n=100,从根到叶的查找最多访问log_50(1,000,000)≈4 个节点
-
B+ 树添加元素
- 确认一个节点有几个格子
- 如果添加的格子没有满,直接添加
- 如果格子满了,需要进行分裂,分裂之后每个节点的格子都空一格,比如说一个节点有四个格子,分裂之后每个格子都只有三个
例题:Construct a B+-tree for the following set of key values (1, 2, 5, 6, 8, 10, 18, 27, 32, 39, 41, 45, 52, 58, 73, 80, 91, 99) Assume that the tree is initially empty and values are added in ascending order. The number of pointers that will fit in one node is 5.
-
B+ 树删除元素
- 如果格子里面元素>2,直接删除
- 如果格子里面元素=2,删除之后要进行合并
- 合并之后的node数字的填写小诀窍:就填右边箭头指向的这个格子的第一个数字就行
-
索引的原理
索引的存储原理大致可以概括为一句话:以空间换时间。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
数据库在未添加索引进行查询的时候默认是进行全文搜索,也就是说有多少数据就进行多少次查询,然后找到相应的数据就把它们放到结果集中,直到全文扫描完毕
优点:
- 大大提高数据查询速度。
- 可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
- 通过索引列对数据进行排序,降低数据的排序成本降低了CPU的消耗。
- 被索引的列会自动进行排序,包括【单例索引】和【组合索引】,只是组合索引的排序需要复杂一些。
- 如果按照索引列的顺序进行排序,对order 不用语句来说,效率就会提高很多。
缺点:
- 索引会占据磁盘空间。
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改查操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
- 维护索引需要消耗数据库资源。
-
哪种情况不适合用索引
查询很少使用的情况不适合建立索引
经常增、删、改的字段不适合建立索引
当数据过少的时候不适合建立索引
定义为text, image和bit数据类型的列不适合建立索引
15 query processing
要考 代价 寻到时间和存储时间的计算
-
代价
代价取决于两个因素:执行的算法、数据库目录中的统计信息估计成本
查询处理的代价包括:磁盘存取,执行一个查询所需要的CPU时间,在并行/分布式数据库系统中的通信代价
用传送磁盘块数以及搜索磁盘次数来度量查询计划的代价:
假设瓷盘子系统传输一个块的数据平均消耗t_T秒,磁盘平均访问时间(磁盘搜索时间+旋转延迟)为t_S秒,则一次传输b个块,以及执行S次磁盘搜索的操作将消耗(bt_T+St_S)秒。
其中t_T和t_S必须针对所使用的磁盘系统来计算
通果把读磁盘块和写磁盘块区分开,可以进一步细化磁盘存取代价的估算。
本书给出的代价没有包括将操作最终写回磁盘的代价,当需要时需要单独考虑。
- 本书所考虑的算法代价依赖于主存中缓冲区的大小
- 最好的情形是所有的数据都可以读入到缓冲区中,不必再访问磁盘
- 最坏的情形是假定缓冲区只能容纳数目不多的块——大约每隔关系一块
- 在代价估算时,通常假定最坏的情形
-
选择运算
表格有点问题: a3 a5要加一个传输 寻道时间
在b+树去做index,查到叶子节点,就是树的高度
后面算法的比较不过多涉及
复合查询有一些概念就好

-
cost of hash join



-
课后例子

16 Query Optimization
17 transaction
基本概念 选择判断题 什么是及联回滚 什么是全欺负
-
事务的定义 transaction
定义:构成单一逻辑工作单元的操作集合称作事务,事务是数据库的操作序列,这些操作要么全做,要么全不做,是不可分割的工作单位,一个事务可以是一个sql语句,一组sql语句,或者整个程序。事务是恢复的基本单位,也是并发控制的基本单位
-
事务的生命周期
- 活动的 active:初始状态
- 部分提交的 partially committed:最后一条语句执行后
- 失败的 failed:发现正常的执行不能继续后
- 中止的 aborted:事务回滚并且数据库已恢复到事务开始执行前的状态后
- 提交的 committed:成功完成后
-
事务的ACID原则:原子性、一致性、隔离性、持久性
事务 transaction:执行单个逻辑功能的一组指令或操作称为事务。它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位
原子性 Atomicity:事务是一个不可再分割的工作单元
一致性 Consistency:数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性
隔离性 Isolation:多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果
持久性 Durability:该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
-
事务的四大隔离级别
主要用于解决脏读、不可重复读、幻读的问题
- 脏读:一个事务读取到另一个事务还未提交的数据
- 不可重复读:在一个事务中多次读取同一个数据时,结果出现不一致
- 幻读:在一个事务中使用相同的 SQL 两次读取,第二次读取到了其他事务新插入的行
隔离级别 脏读 不可重复读 幻读 读未提交(Read Uncommitted) 有 有 有 读已提交(Read Committed) 无 有 有 可重复读(Repeatable Read) 无 无 有 串行化(Serializable) 无 无 无 -
可串行化和冲突可串行化
串行调度 serial schedule:n个并行事务有n!种可选择的串行调度
可串行化调度 serializability:多个事务并发执行的结果= 这些事务按照某种次序串行执行的结果
冲突 conflict:如果顺序交换,那么涉及的事务中至少有一个事务的行为会改变。同一个事务的任何两个操作都是冲突的,不同事务对同一元素的写操作是冲突的,不同事务对同一元素的一读一写操作是冲突的
冲突等价 conflict equivalent:如果调度S可以经过一系列非冲突指令交换转换成S‘,我们称S与S’是冲突等价的
冲突可串行化 conflict serializability:一个调度如果通过相邻两个无冲突的操作能够转化到某一个串行调度(重冲突等价),则称此调度为冲突可串行化调度
**注意:**满足冲突可串行性,一定满足可串行性,反之不然


-
优先图 precedence graph ⭐
**简介:**是一个冲突可串行的判别算法
**使用:**每个事务是一个节点,每个有冲突的操作是一条边,如果没有环就是冲突可串行化的。如果T1的一个操作跟T2冲突,且T1在T2之前执行,绘制一条从T1指向T2的箭头,如果该图没有环,表示它是冲突可串行化的
例题1:下图画出来是一个拓扑排序,所以是冲突可串行化的

例题2:下图展示了两个不同的

-
级联回滚 cascading rollback
级联回滚 cascading rollback:一个事务的失效导致一系列并发执行的事务回滚的现象。级联回滚导致撤销大量事务的工作,因此需要加以限制,避免这种现象的发生。因此调度应为无级联调度。
-
事务的大题例题
第一道题:判断执行是否正确
- 计算并行的结果:A = 30, B = 100

- 计算先 T1 后 T2 的串行结果:A = 30, B = 200

- 计算先 T2 后 T1 的串行结果:A = 110, B = 100

- 因为三个结果都不一样,说明执行结果是错误的
第二道题:通过加锁使得结果正确


-
SQL 事务控制语句
- BEGIN 或 START TRANSACTION:显式地开启一个事务
- COMMIT 或 COMMIT WORK,二者是等价的:COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的
- ROLLBACK 或 ROLLBACK WORK,二者是等价的:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier:SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT
- RELEASE SAVEPOINT identifier:删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常
- ROLLBACK TO identifier:把事务回滚到标记点
- SET TRANSACTION 用来设置事务的隔离级别:InnoDB 存储引擎提供事务的隔离级别有 READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE
-
MySql 事务处理两种方法
- 用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT = 0 禁止自动提交
- SET AUTOCOMMIT = 1 开启自动提交
事务测试:
mysql> use RUNOOB; Database changed mysql> CREATE TABLE runoob_transaction_test( id int(5)) engine=innodb; # 创建数据表 Query OK, 0 rows affected (0.04 sec) mysql> select * from runoob_transaction_test; Empty set (0.01 sec) mysql> begin; # 开始事务 Query OK, 0 rows affected (0.00 sec) mysql> insert into runoob_transaction_test value(5); Query OK, 1 rows affected (0.01 sec) mysql> insert into runoob_transaction_test value(6); Query OK, 1 rows affected (0.00 sec) mysql> commit; # 提交事务 Query OK, 0 rows affected (0.01 sec) mysql> select * from runoob_transaction_test; +------+ | id | +------+ | 5 | | 6 | +------+ 2 rows in set (0.01 sec) mysql> begin; # 开始事务 Query OK, 0 rows affected (0.00 sec) mysql> insert into runoob_transaction_test values(7); Query OK, 1 rows affected (0.00 sec) mysql> rollback; # 回滚 Query OK, 0 rows affected (0.00 sec) mysql> select * from runoob_transaction_test; # 因为回滚所以数据没有插入 +------+ | id | +------+ | 5 | | 6 | +------+ 2 rows in set (0.01 sec) mysql>
18 并发控制
-
封锁的类型
- X锁:写锁,排他锁,某事务对数据对象上锁后,可读取和修改该数据对象。其它事务不可再对它添加锁
- S锁:读锁,共享锁,某事务对数据对象上锁后,可读取但不可修改该数据对象。其它事务可以再对它添加S锁,但不能添加X锁
- 表示方法:上锁Slock(),解锁Unlock()
- 共享锁可以升级为排他锁,排他锁可以降级为共享锁

-
三种封锁协议
- 封锁协议:规定事务何时对数据项们进行加锁、解锁,限制了可能的调度数目
- **一级封锁协议:**写前加排他锁,事务结束后释放锁
- **二级封锁协议:**写前加写锁,读前加读锁,读完释放读锁,事务结束释放写锁,可防止丢失修改和读脏数据
- 三级封锁协议:写前加写锁,读前加读锁,事务结束释放各个锁,可防止丢失修改、读脏数据和不可重复读,但是因为隔离级别高,事务无法交叉并行,都是可串性化调度
-
两阶段封锁协议 2PL ⭐
**两阶段封锁协议 two-phase locking protocol:**事务在对任何数据进行读写之前,需要获得对该数据的封锁,而当事务释放任何一个封锁后,不可再获得任何其它的封锁。事务遵循两段封锁协议是可串化的充分条件,保证了冲突可串行化,遵循两段协议是可能发生死锁的
两阶段封锁协议的两个过程:
每个事务分成两个阶段提出加锁和解锁的申请
- 增长阶段 growing phase 事务可以获得锁,不能释放锁
- 缩减阶段 shrinking pahse 事务可以释放锁,不能获得新锁
进阶两阶段封锁协议:
- 严格两阶段封锁协议:要求事务提交之前不得释放排他锁
- 强两阶段封锁协议:要求事务提交之前不得释放任何锁
-
活锁和死锁

-
脏读、不可重复读、幻读
脏读:一个事务读取到另一个事务还未提交的数据。
不可重复读:在一个事务中多次读取同一个数据时,结果出现不一致。
幻读:在一个事务中使用相同的 SQL 两次读取,第二次读取到了其他事务新插入的行。
不可重复读注重于数据的修改,而幻读注重于数据的插入。
-
基于图的加锁协议
-
死锁处理
19 故障恢复
基于日志的恢复
checkpoint
-
数据库的故障类型
- 事务故障:两种错误导致事务故障,逻辑错误和系统错误,其中逻辑错误就是程序逻辑写错了,系统错误指DBMS本身原因导致的错误,如死锁等
- 系统崩溃:软硬件故障导致的系统中止,主存中的信息丢失。例如掉电、软件漏洞等
- 磁盘故障:磁盘设备故障,如读写头、磁盘本身写数据问题等
-
存储器分类
- 易失性存储:当系统故障时,其中的数据丢失,例如主存、cache等都属于易失性存储
- 非易失性存储:系统故障时,其中的数据不会丢失,例如磁盘、磁带、flash以及有电源支撑的RAM
- 稳定存储:是一种理想的存储器,可以在任何故障情况下不损坏数据,通常用异地保存多个副本的方式来实现,如两地三备份
-
什么是日志

-
缓冲区的处理策略
最常用的是 Steal 和 No force
Force:内存中的数据最晚在commit的时候写入磁盘
No steal:不允许在事务commmit之前把内存中的数据写入磁盘
No force:内存中的数据可以一直保留,在commit之后过一段时间在再写入磁盘,此时在系统崩溃的时候,可能还没写入到磁盘,需要redo
Steal:允许在事务commit之前把内存中的数据写入磁盘,此时若系统在commit之前崩溃时,已经有数据写入到磁盘了,要恢复到崩溃前的状态,需要undo

-
日志的记录方式

-
Undo型日志
将事务改变的所有数据写到磁盘之前不能提交该事务


-
利用Undo型日志进行恢复


-
检查点 checkpoint

-
Redo型日志
- 是先commit后再output
- <T,a,b>里的这个b是记录新的值不是老的值


-
Undo/Redo结核性
如果故障发生在提交之前,从后往前按反序,把更新前的值机记录 undo
如果故障发生在提交之前,从前往后按正序,把更新后的值机写会去 redo