软件测试与验证
期中考试范围 软件缺陷 逻辑覆盖 控制流测试
全是简答题,英文试卷
二、代码单元测试
动态的代码测试:在开发环境中,通过运行被测代码,验证其是否满足期望目标,尽早发现与目标不一样的缺陷
面向代码的动态测试分为两类:代码单元测试、代码接口测试
单元测试和集成测试的区别:一个是规模,以测试执行速度的快慢来界定,不超过0.1s。另一个是独立性,单元测试不能有任何外部资源的依赖,用到了测试替身
测试替身(Test Double):替代真实代码中依赖于数据库、网络和文件系统的代码,只有形没有内容,是假的东西
单元:功能相对独立、规模较小的代码
按照软件测试技术发展规律,我们面向代码测试内容讲解分成两大部分:测试技术,测试生成

1.逻辑覆盖准则
逻辑测试:以代码中逻辑表达式结构为对象的测试,以期发现代码逻辑结构缺陷
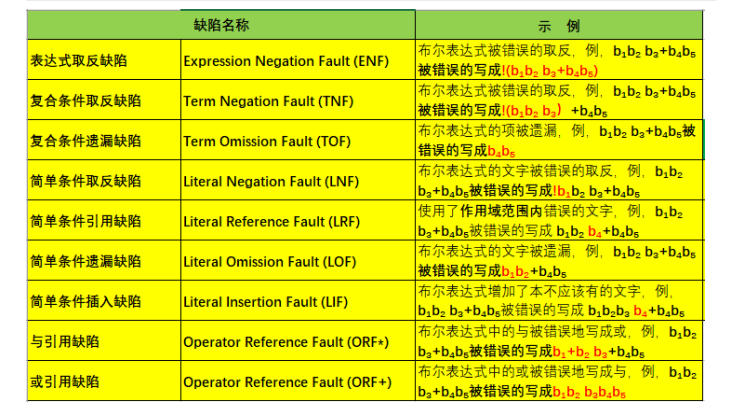
逻辑结构缺陷:写代码时所犯错误在逻辑表达式上的可视化体现;逻辑表达式写错了,程序行为不正确
逻辑表达式缺陷类型DNF:
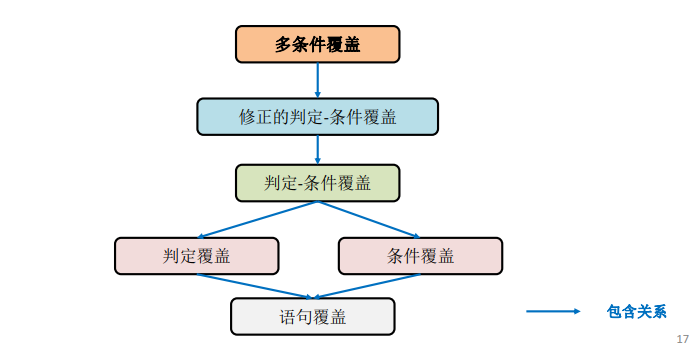
基于逻辑覆盖准则的测试(Logical Coverage Criteria):用于衡量代码中逻辑表达式被测试的充分程度

下图中的蓝色箭头表示A包含B,意思是B能够发现的缺陷一定可以被A发现,满足上面就一定满足下面的意思,但是判定覆盖和条件覆盖比较特殊
满足逻辑覆盖准则 ≠ 高质量测试
高质量测试是发现高质量缺陷的测试
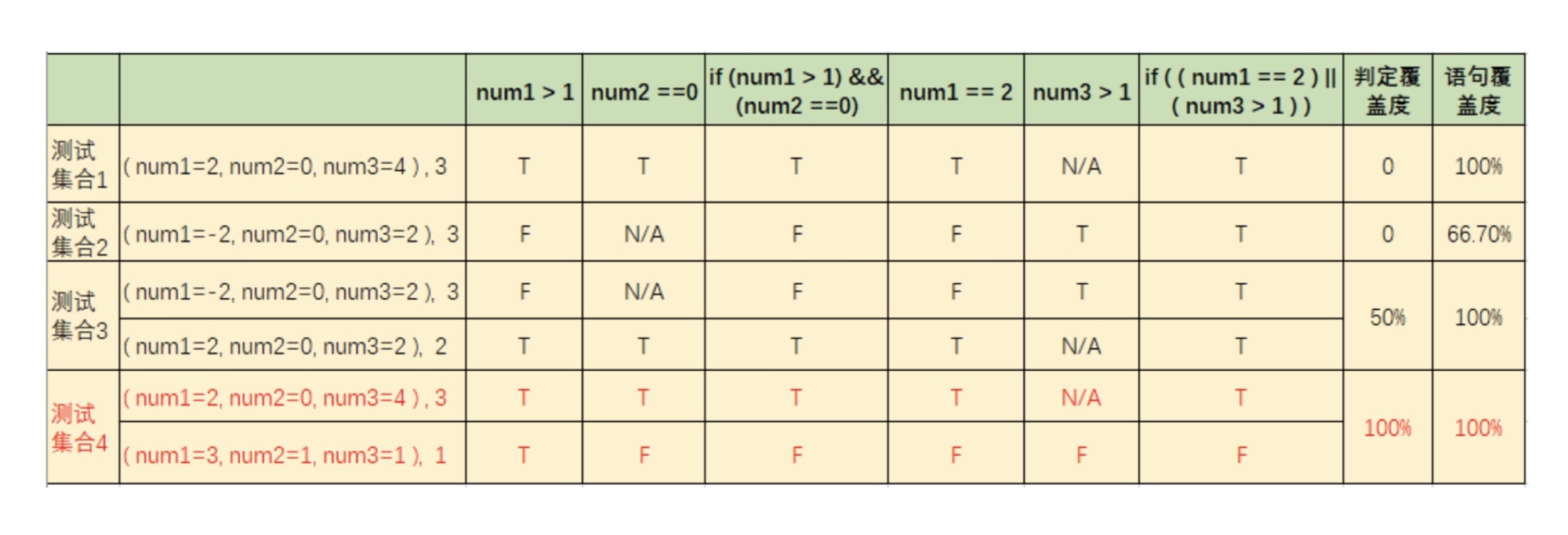
语句覆盖Statement Coverage
用来衡量被测代码中的语句得到执行的程度,如果测试集合能够使得被测代码中的每条语句至少被执行一次,那么则说该测试集合满足了语句覆盖
语句覆盖度:

语句覆盖测试案例:
语句覆盖是定义在源代码上的,所以看的是源代码
可以在测试集合中增加多个测试用例使语句覆盖度达到100%,如例3
在逻辑测试当中,语句覆盖是最低级的,因为它只是把每个语句走了一遍,并没有去测试什么逻辑,如果把 if 里面的 && 改成 || 语句覆盖无法揭示错误

判定覆盖Decision Coverage
衡量代码中的判定得到执行的程度,如果测试集合能够使得被测代码中的每个判定至少被执行一次(指每个判定的所有可能结果都至少出现一次,例如 if((num1>1)&&(num2==0)) 的真假结果都得到执行,才认为该判定被执行),那么则说该测试集合满足了判定覆盖
条件:不含布尔算子(与或非)的逻辑表达式,例如关系表达式、布尔变量等

判定:一个或者多个条件通过一个或多个布尔算子连接起来的逻辑表达式
判定覆盖度:

判定覆盖测试案例:
注意指每个判定的真和假结果都至少出现一次,才叫做执行了

判定覆盖的缺点:主要看的是逻辑操作符用的对,逻辑操作符用的对不代表逻辑就对,不一定能发现条件缺陷,如果把 num > 1 写成了 num > -1,则不能揭示错误
注意短路操作符 && 和 ||,即当出现了false或true就不走了,MC/DC准则产生的原因,所以上个例子正确的结果表格应该是
条件覆盖 Condition Coverage
衡量代码中构成判定的各个条件得到执行的程度,如果测试集合能够使得被测代码中的每个条件至少被执行一次,那么则说该测试集合满足了条件覆盖
每个条件被执行一次的含义:每个条件的所有可能结果都至少出现一次

条件覆盖度:

条件覆盖测试用例:
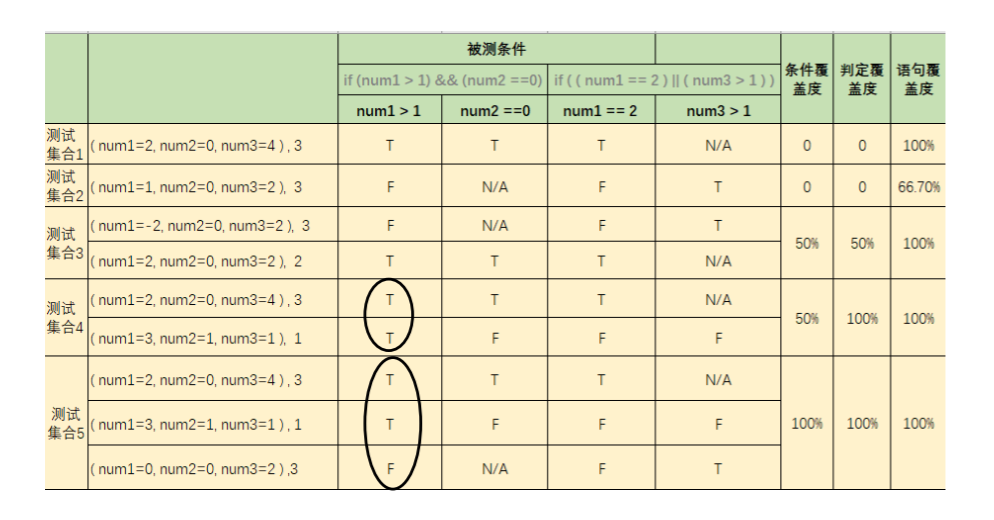
notice:满足判定不一定满足条件,满足条件不一定满足判定
判定-条件覆盖 Decision-Condition Coverage(仅了解)
衡量代码中每个判定以及构成判定的每个条件得到执行的程度,如果测试集合能够使得被测代码中的每个判定至少被执行一次并且构成判定的每个条件至少被执行一次,那么则说该测试集合满足了判定-条件覆盖。

修正的判定-条件覆盖
Modified Condition/Decision Coverage,MC/DC
期望构成每个判定的每个条件能独立地影响整个判定的结果
方法:
使用D表示判定,ci表示D的第i个条件
D(ci=true)表示将D中所有ci使用true替换之后的判定表达式
D(ci=false)表示将D中所有ci使用false替换之后的判定表达式
逻辑表达式==Dci= D(ci=true)⊕D(ci=false)== 可以用于计算ci独立影响判定时,其它条件的测试输入值
异或算法表示两边取值不一样,所以只有Dci = true才能证明独立影响
注意不是每一个算法都能找到MC/DC结果
一个简单的例子:

分析:
第一个式子里面,c2的值没有变化,一直为真,随着c1从真变成假,结果也从真变为了假,说明c1对我们整个判定结果产生了影响
第二个式子里面,c1的值没有变,变的只是c2的值,c2的值变了结果也变了,c2也能够独立影响
下面是一个综合例子:
求D的mc/dc测试用例,就是把满足c1,c2,c3的测试用例结果并起来?

对于上面这个判定,使得它可以独立影响表达式结果,那么它的输入应该有3个,真真,假真,真假
注意,我们要算的是其他人取什么值才不会影响结果,使得我可以独立影响整个结果


分别求出来之后,把三种情况的测试情况求并集


下面一个实际应用:

多条件覆盖 Multiple Condition Coverage

不是对着覆盖度来去设计测试用例,而是对着功能设计,再来根据覆盖度去修改用例
2. 逻辑覆盖测试工具
两种工具:IntelliJ IDEA Code Coverage Runner/JaCoCo
IDEA Code Coverage Runner

IDEA branch coverage的计算方法与Jacoco不一样,而且似乎有缺陷
获取jacoco覆盖报告的方法
注意,想要获取覆盖率结果,工程里必须写单测代码,否则不会有结果
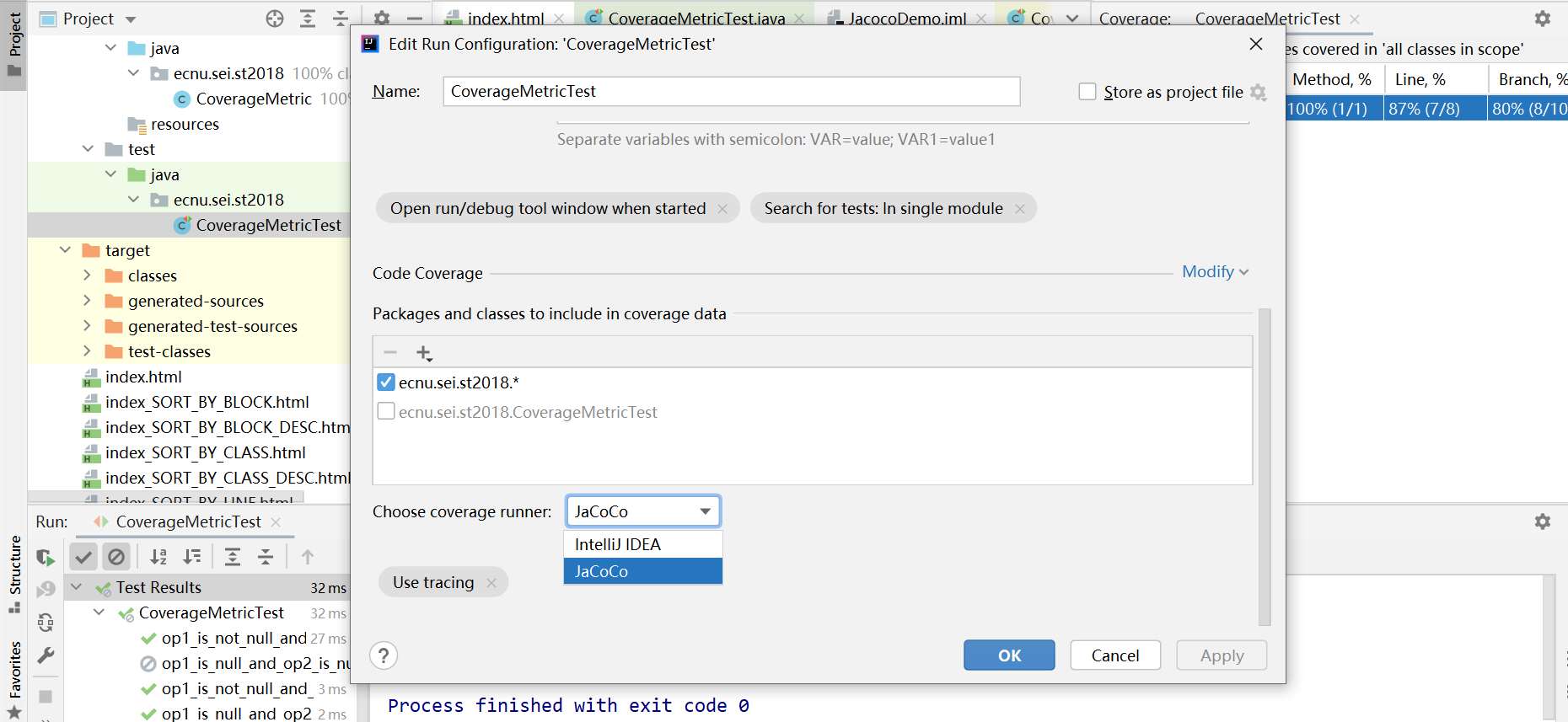
点击mvn test
就可以在target的site目录下生成一个 index.html文件,点开文件即可查看报告
覆盖报告分析
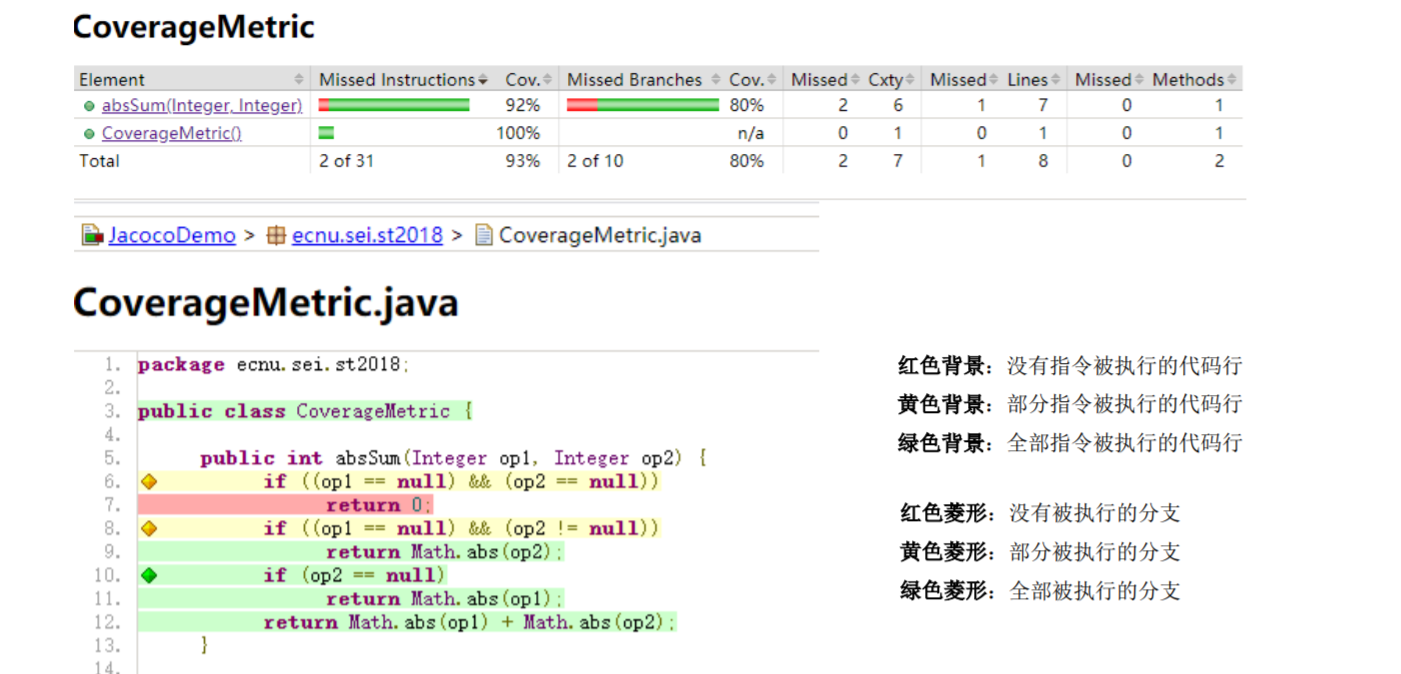
JaCoCo Coverage Counters
Instructions
Branches
计算所有 if 和 switch 语句的分支覆盖率
无覆盖:行中没有分支被执行(红色菱形)
部分覆盖:只执行了行中的部分分支(黄色菱形)
全覆盖:行中的所有分支都已执行(绿色菱形)
Cyclomatic Complexity 环复杂度
二值节点的个数 超过10的代码不能通过
在(线性)组合中,可以通过一种方法生成所有可能路径的最小路径数
Lines 语句覆盖 跟这个语句相关的二进制指令执行
当至少一条分配给该行的指令已被执行时,该行被视为已执行
无覆盖:该行中未执行任何指令(红色背景)
部分覆盖:只执行了该行中的一部分指令(黄色背景)
全覆盖:该行中的所有指令都已执行(绿色背景)
Methods 方法覆盖
Classes 类覆盖
IDEA branch coverage的计算方法与Jacoco不一样,而且似乎有缺陷
3. 启发式规则
好的单元测试:r原则,自动化的,independent,可重复的repeatable
BCDE原则

Heuristic Rules
没有理论基础,只是根据工程实践经验总结出来的,类似于头脑风暴
告诉你在设计测试用例时,可以遵循一个什么样的思路
Right—BICEP

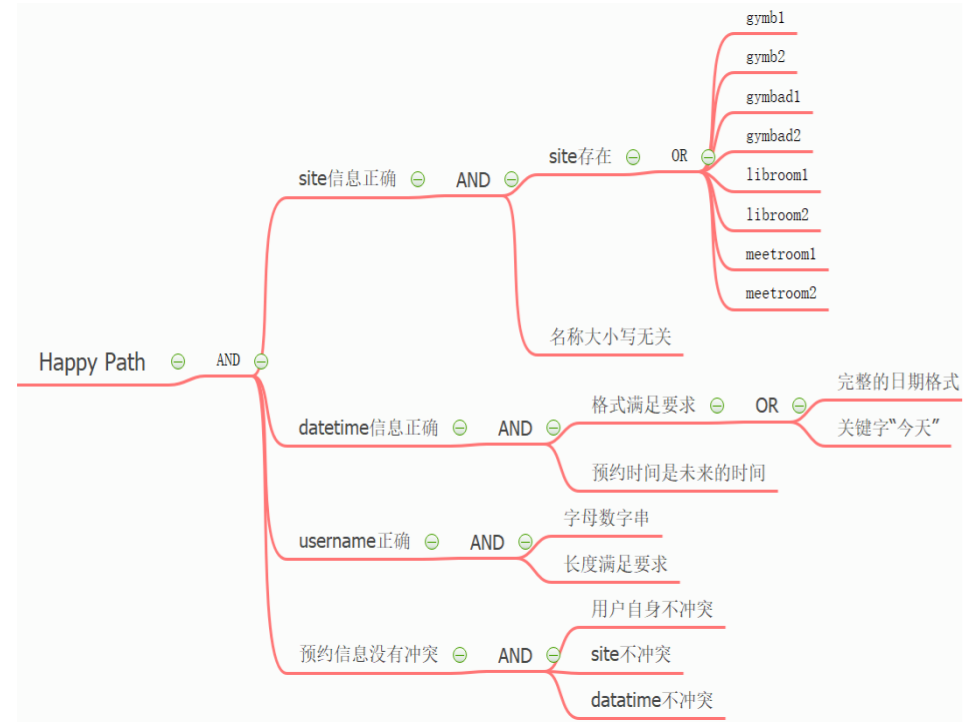
Right
找到happy path 就是满足下面所有条件的测试用例
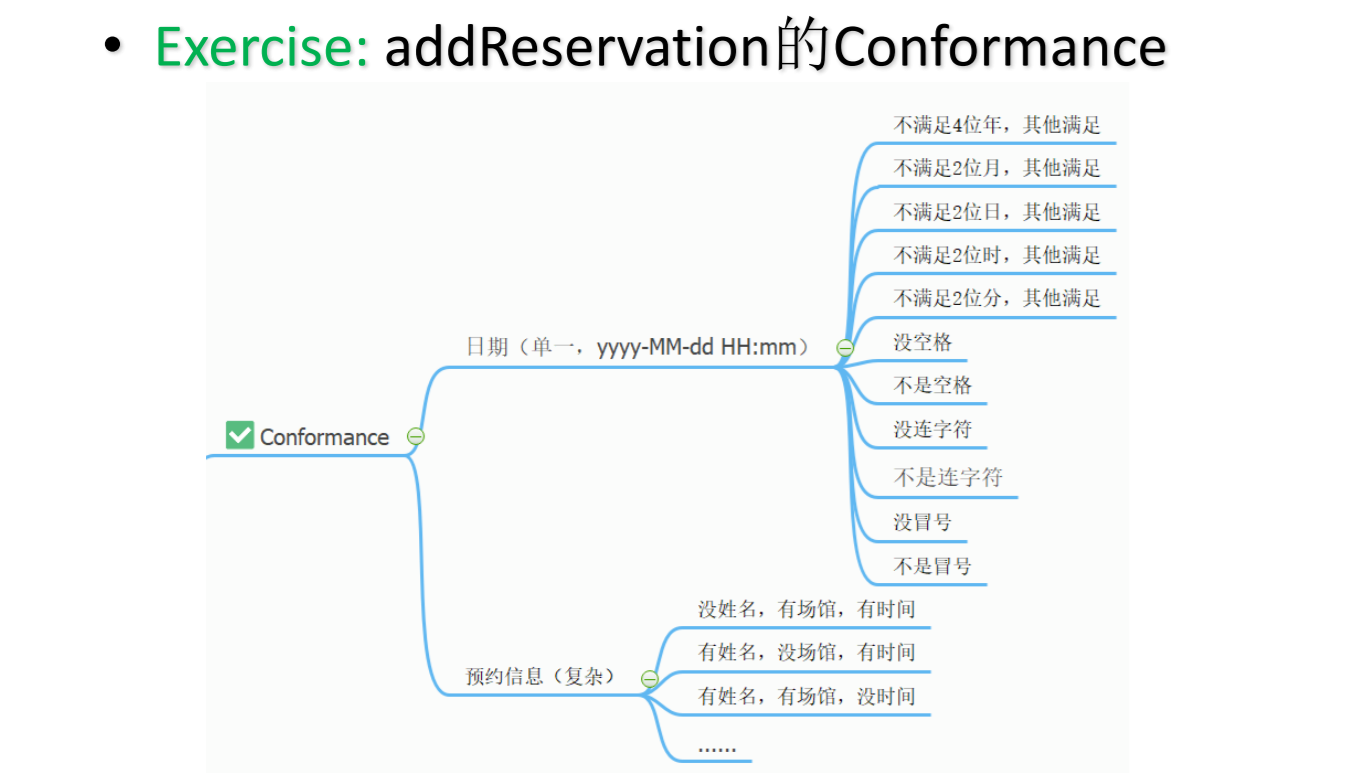
B:边界条件(最重要)
缺陷隐藏在代码里,一般聚集在边界上,程序员在边界处经常出问题
虚假或不一致的输入值,格式错误的数据、错误的电话号码,可能导致数字溢出的计算,空值或缺失值
年龄的边界很好找,但不是所有的边界条件都那么好找,所以我们引入了correct规则寻找边界条件


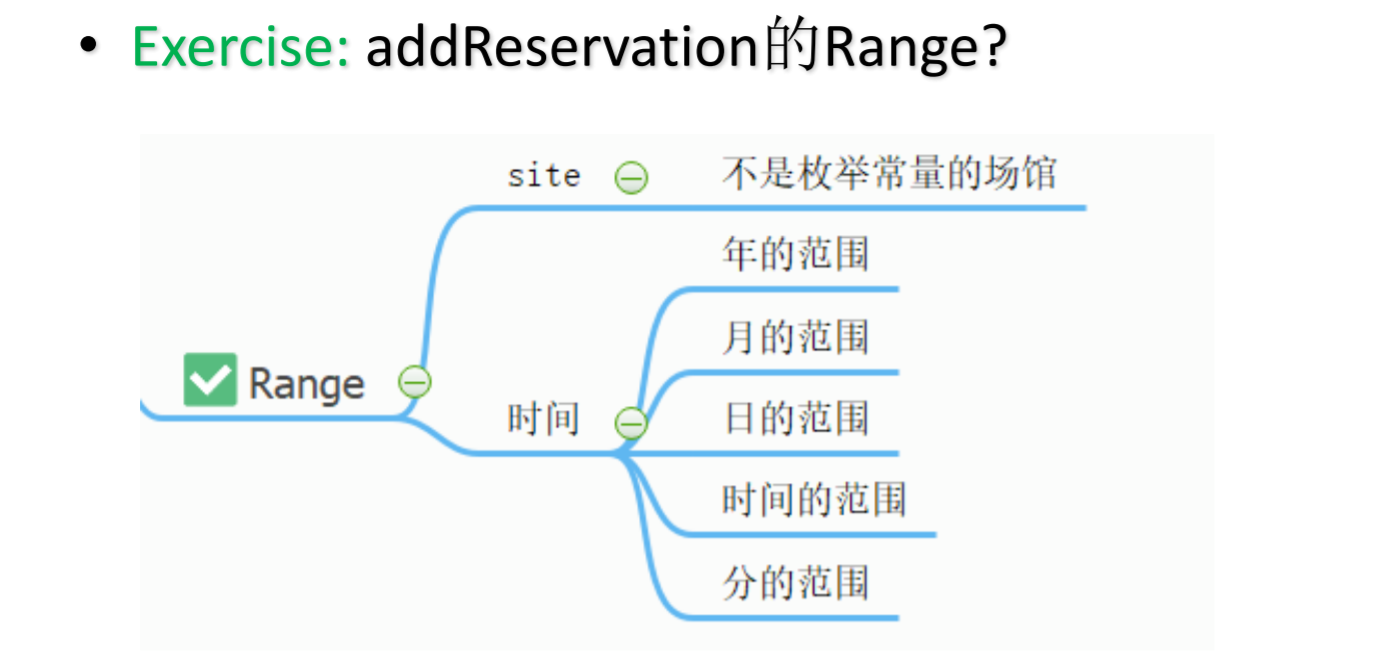

I:逆关系
用“逆行为”测试被测试代码
在数据库中插入一条记录后,查询该记录
已经使用的款项总数 = 款项总数 – 剩余的款项数
C:交叉关系检查被测功能是否满足要求
使用不同数据之间的关系进行测试
已经使用的款项总数 = 款项总数 – 剩余的款项数

E:验错 Forcing Error Condition
java中长生命周期对象引用了短生命周期对象,而短生命周期对象用完之后没有及时释放,就是内存泄露

P:查看性能

单元测试第一目标是要找缺陷,覆盖是顺带要达到的目标
4. Junit 测试脚本
Junit5 Features
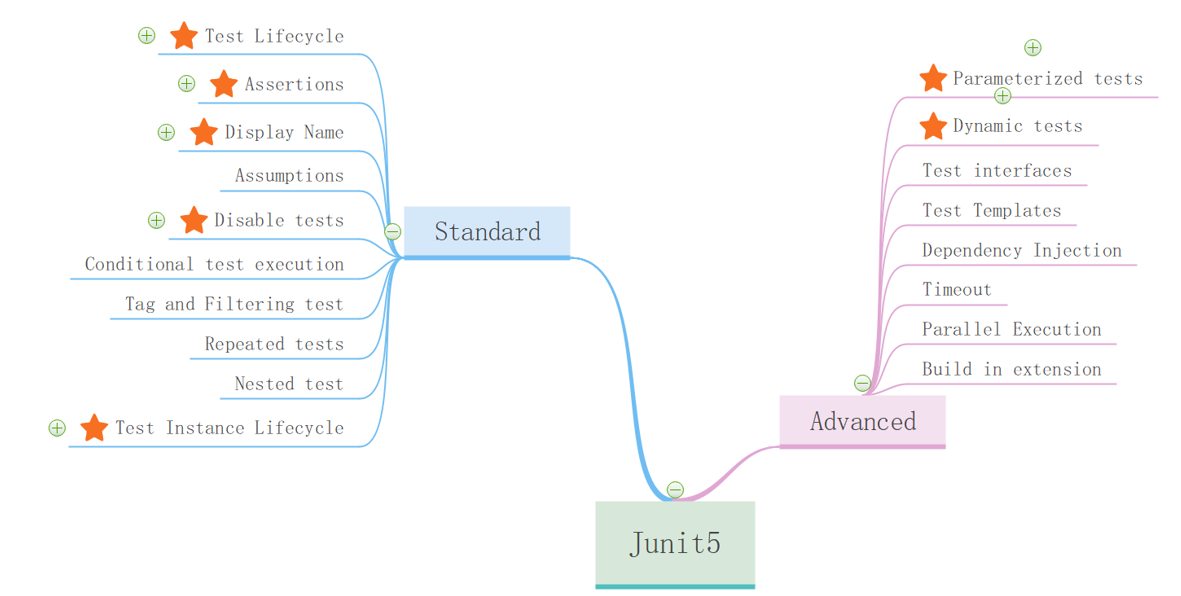

junit所有特性都通过allowcation(at notation?)这个功能来实现的,要记住每个at notation的含义是什么,每个功能对应哪个notation要记住,下面几个老师单独提了一下:
@displayname的作用,提高可读性
@disable 忽略执行
@test instance lifecycle :star:
@test instance lifecycle 具体用法参考 TestPerClass 和 TestPerMethod 两个文件
测试类不是你的被测类,测试类是testlifecycle,被测类是meetcalendar

junit实例化测试类(instance)的方法有两种生命周期模式:
一种是在每一个测试方法之前,都会实例化一个测试类(独立性,减少测试和测试之间的依赖关系)
一种是一个测试类就实例化一个测试类的实例
|
|
要是两个程序代码一样,只是@TestInstance的参数不同(以上面的程序为例):
第一种 MeetCalendarTestPerMethod
addcount1冒号后面是几
addcount2冒号后面是几
都是1,因为每个测试方法之前都会实例化一个testmethod实例
第二种 MeetCalendarTestPerClass
addcount1 addcount2 顺序不确定 但count是在累加的
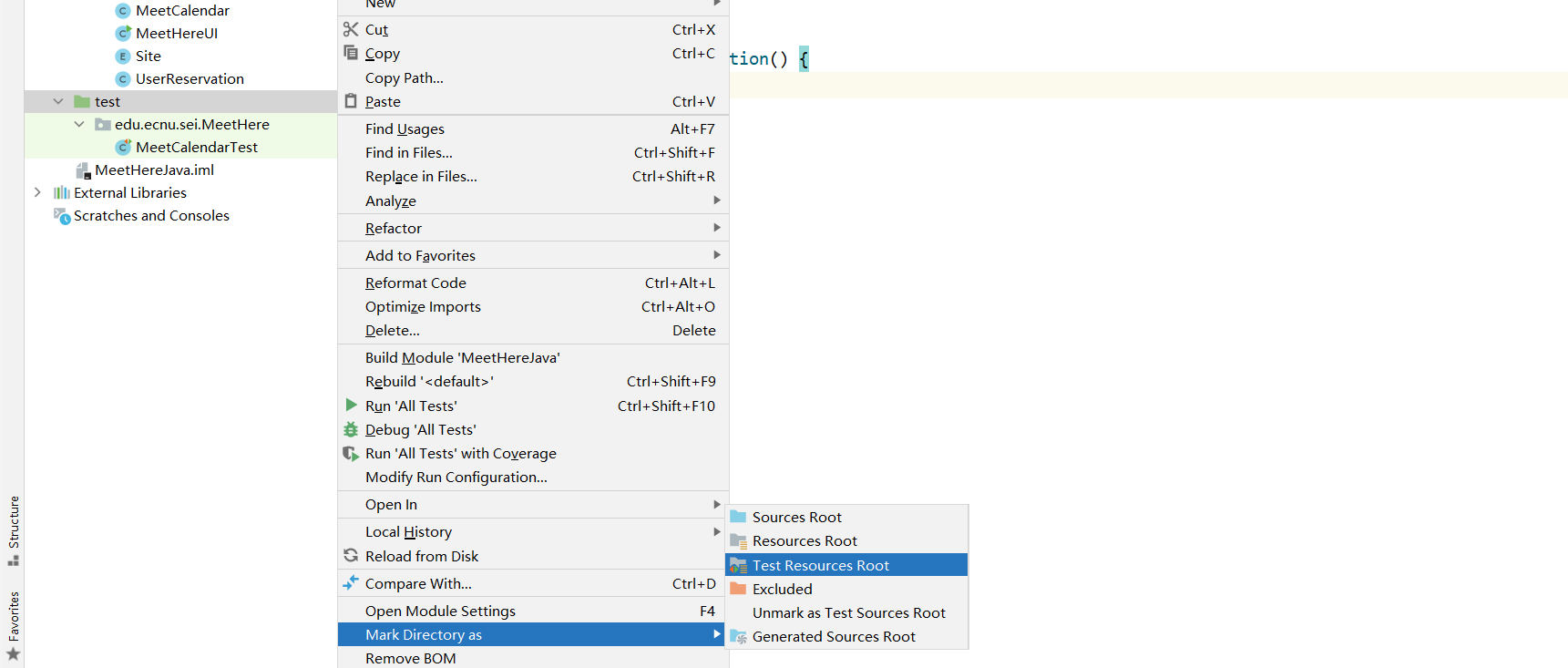
配置junit5环境
junit需要java8以上的支持,确认java版本
在项目里新建test目录,并且标记为测试根目录
右键一个方法,generate test
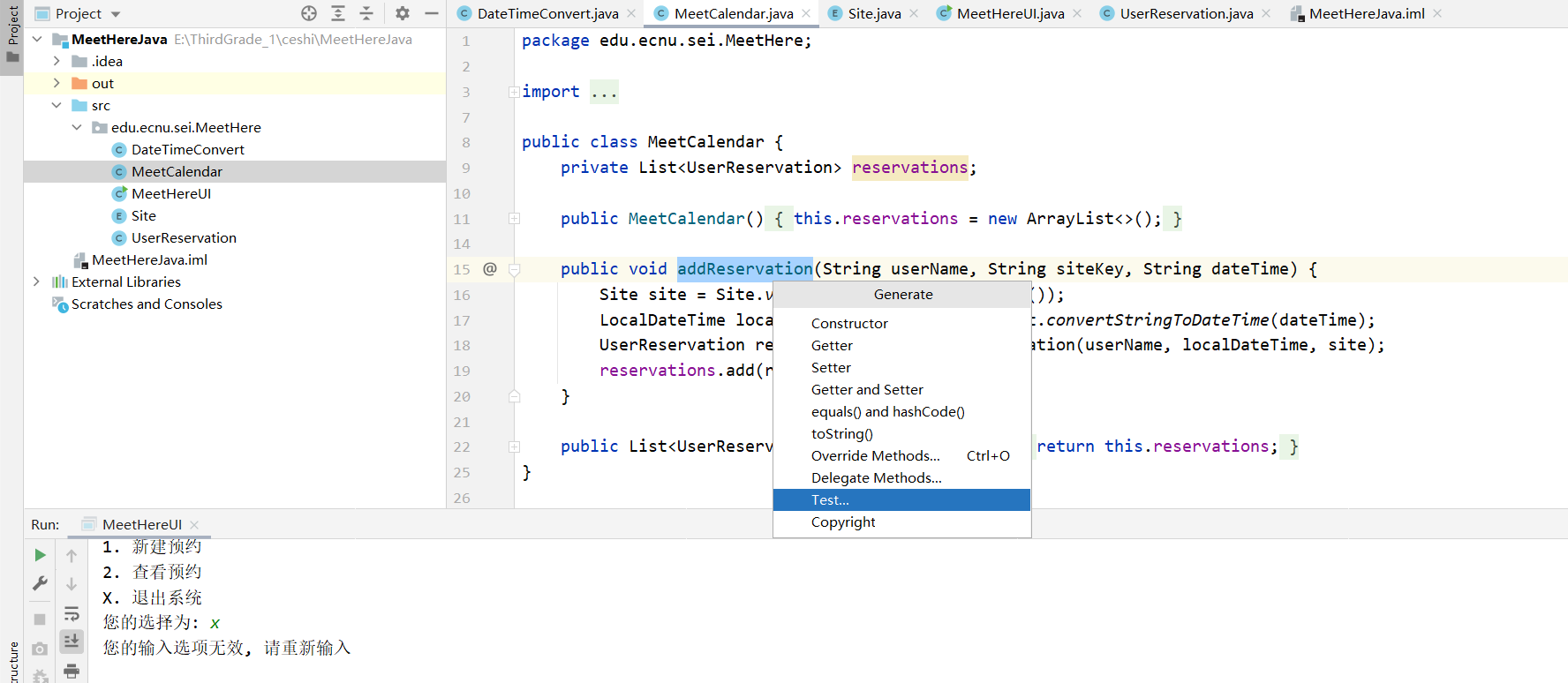
窗口提示我们当前项目并没有junit的支持,点击fix,自动下载jar包

已经有了测试方法,至此测试环境已经准备就绪

配置maven测试环境
setting maven runner jre改为1.8

project structure project sdk 也选1.8
Lifecycle
meetherejava里面有一个test lifecycle的测试类,每一个@test就是一个测试方法

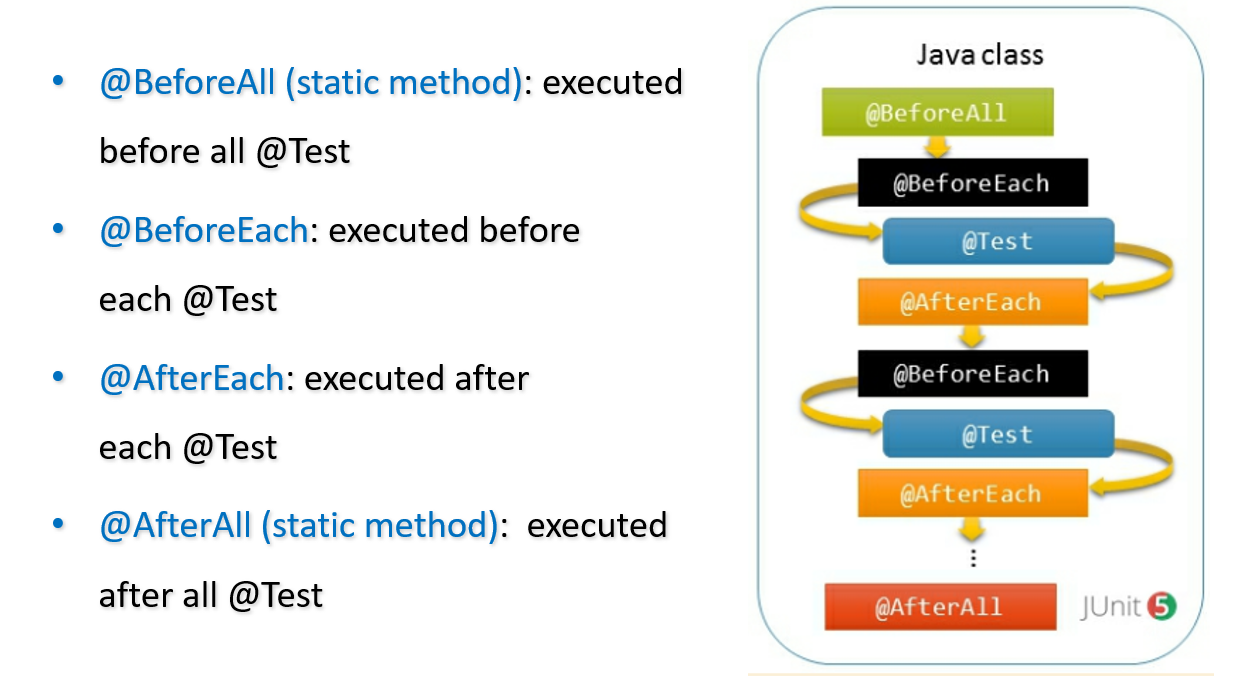
例如,避免在每个方法之前都要实例化一个对象,我们可以用@beforeeach的方法进行初始化
|
以上代码和以下原始代码是一致的
|
下面的代码运行结果应该是
before all test, before each test, the first test, after each test, before each test, the second test, after each test, after all test
|
Assertions
assertAll():
分组不同的断言,所有断言是被执行,任何失败都会一起报告
|
MeetHereMaven 项目中 MeetCalendarTest 的 addAnReservation() 中的以上代码,可以用assertAll()改写为
|
assertThrows():
系统抛出期望的异常
注意两点,一点系统是否抛出了期望的异常类型,一点处理异常的行为是不是正确
MeetHereMaven 项目中 DateTimeConvertTest 中有异常处理的例子
第一个参数是抛出的异常类型,第二个参数是我们输入的拉姆达表达式
|
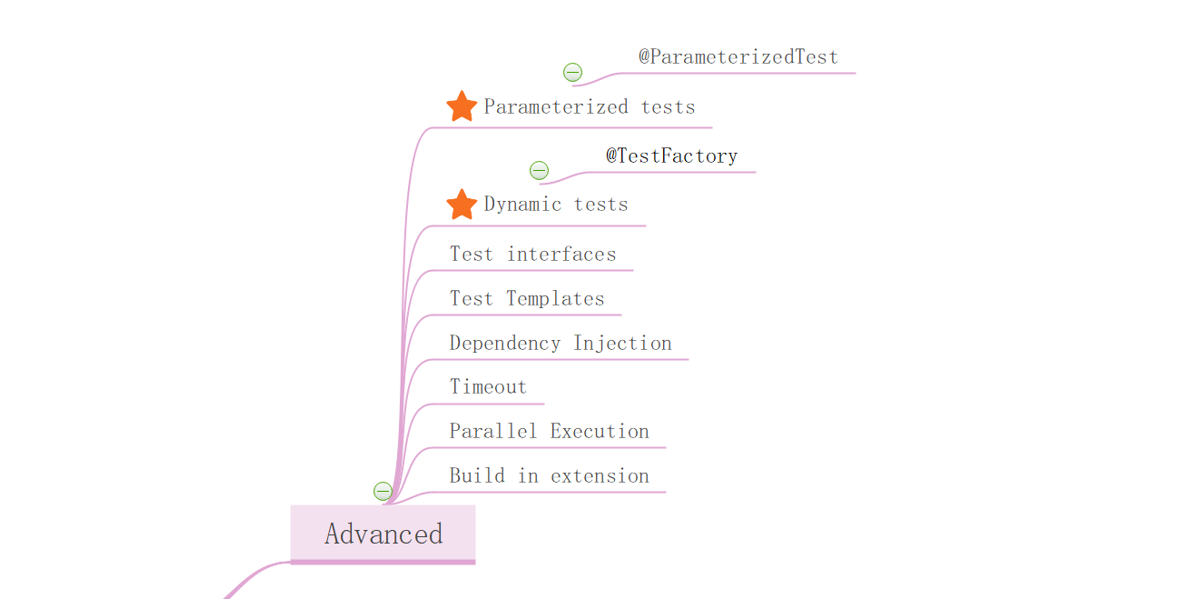
Parameterized tests 参数化测试
@ParameterizedTest 与 @Test 相同的生命周期
这是Junit5中实现的数据驱动自动化测试技术,通俗的讲就是只写一个测试方法,可以跑不同的数据
将测试数据和测试行为进行了分离,测试数据源和数据脚本是分开的,数据不是写在代码里
使用不同的参数多次运行测试,一段代码可以执行很多测试数据
学参数化测试要学哪些东西至少三点,最重要的是测试数据源,一是为测试定义测试数据类型,二是参数转换,测试数据源如何处理变量类型,类型匹配,类型转化,三是自己的属性
(1)定义数据源
参数指的的测试方法里面的方法的参数,测试数据源是这一个集合,每一条叫一个测试数据argument
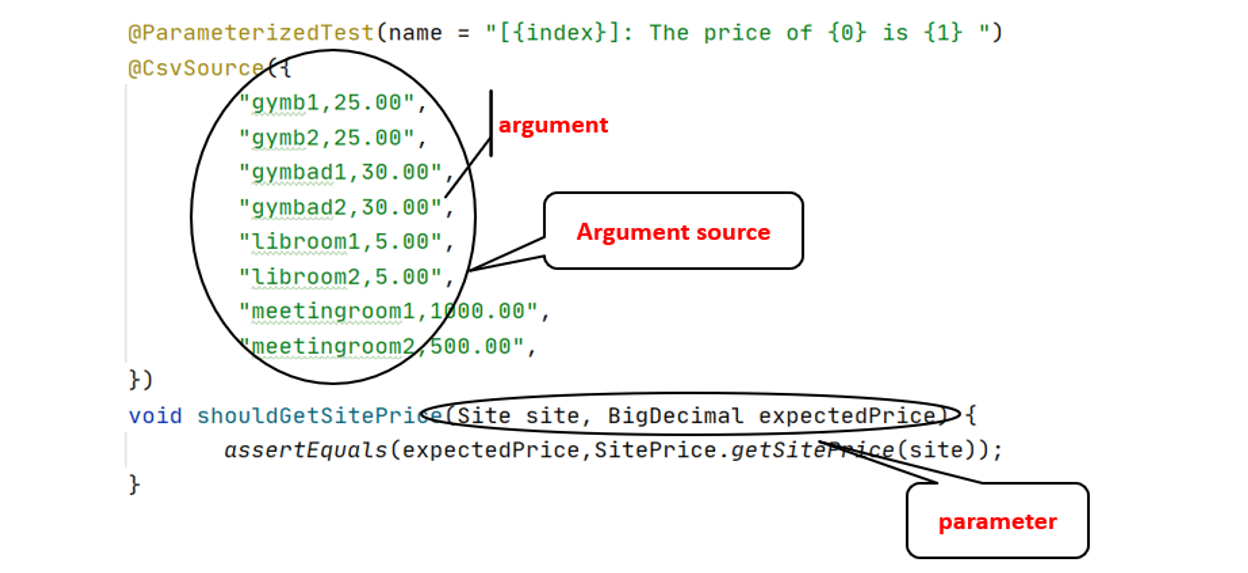
(1).1 测试数据源(argument source 简称 AS)的基本使用原则:
AS规则1:
每个@Parameterized测试方法可以使用多个测试数据源,但是至少需要有一个
|
下面代码给了两个数据源,用了junit5提供的两种定义数据源的方式(共七种),一种是一维数组@ValueSource,一种是使用方法来指定数据源@MethodSource,这个方法的名字叫range,但是必须返回一个string兼容类型
下面这个方法会运行8次,range是包含0,不包含20,但是从第15个往后跳,只有15 16 17 18 19,运行5次
|
AS规则2:
每个测试数据源必须为测试方法的所有参数提供测试数据。例如,测试方法若有2个参数,参数1不能使用测试数据源1,而参数2使用其他数据源,即参数2也必须使用测试数据源1
比如下面这个程序是不对的会报错
|
(1).2 常用的定义数据源的七种方法:
详见junitDemo项目
|
@EnumSource
有两个可选的属性,用哪一个枚举量,跟模式是相关的,INCLUDE, EXCLUDE, MATCH_ALL,MATCH_ANY
//1 must attribute
value: @EnumSource(TimeUnit.class)
//2 Optional attributes
name: @EnumSource(value = TimeUnit.class, names = { "DAYS", "HOURS" })
mode: @EnumSource(value = TimeUnit.class, mode = EXCLUDE, names = { "DAYS", "HOURS" })@CsvSource
@ParameterizedTest
@CsvSource({"apple,1","orange,2","'lemon,lime',0xF1"})
void testWithCsvSource(String fruit,int rank) {
assertNotNull(fruit);
assertNotEquals(0, rank);
}
@ParameterizedTest
@CsvSource(delimiter= ';',value = {"apple;1","orange;2","'lemon,lime';0xF1"})
void testWithCsvSourcebyAtt(String fruit,int rank) {
assertNotNull(fruit);
assertNotEquals(0, rank);
}@MethodSource
参考一种或多种方法(工厂方法)为测试方法提供测试数据
这个制造数据的方法必须是static,不能带参数
如果@MethodSource 中没有给出工厂方法,则选择与测试同名的方法作为工厂方法
//字符串
@ParameterizedTest
@MethodSource({"stringArguments","stringArgumentsWithStream","stringArray"})
void testWithString(String argument) {
assertNotEquals("hysun", argument);
}
static List<String> stringArguments(){
return Arrays.asList("software","testing");
}
static Stream<String> stringArgumentsWithStream(){
return Stream.of("Junit","Mockito");
}
static String[] stringArray(){
String[] str_data = {"selenium","appnium"};
return str_data;
}
//单个数字
@ParameterizedTest
@MethodSource("singleInteger")
void testSingleGrade(int grade){
assertTrue(grade >= 0 && grade <= 100);
}
static int singleInteger(){
return 85;
}
//list
//测试方法有多个参数,工厂方法返回 Stream、Iterable、Iterator 或 Arguments 类型的数组
@ParameterizedTest
@MethodSource("provideWithList")
void testMultipleGrade(int grade1,int grade2){
assertTrue(grade1 >= 0 && grade1 <= 100);
assertTrue(grade2 >= 0 && grade2 <= 100);
}
static List<Arguments> provideWithList(){
return Arrays.asList(Arguments.of(90,45),
Arguments.of(60,30),
Arguments.of(85,42));
}工厂方法可以是测试类中的方法,也可以是其他类的方法
至于来自外部类的工厂方法,需要完整的类名,不要忘记包名!!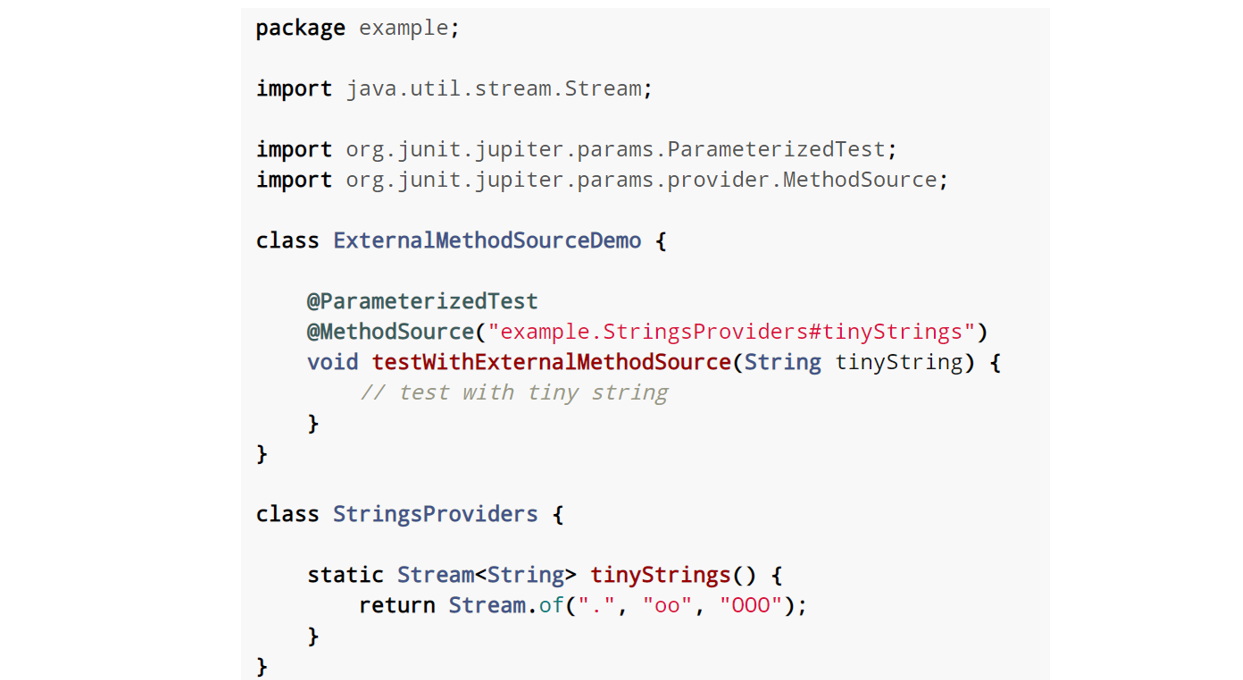
@CsvFileSource
通过引用resource里面的文件


如果把lemon,line的双引号改成了单引号
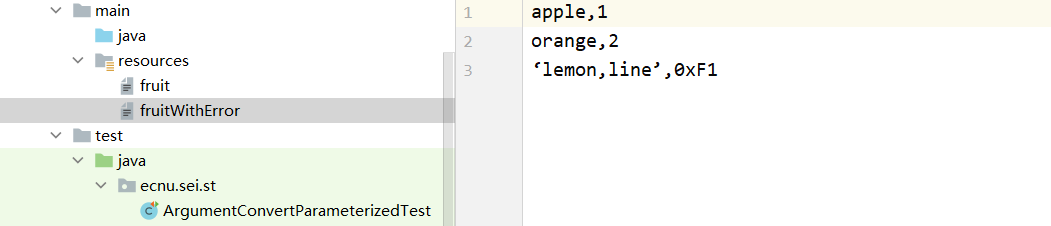
则下面的代码会报错
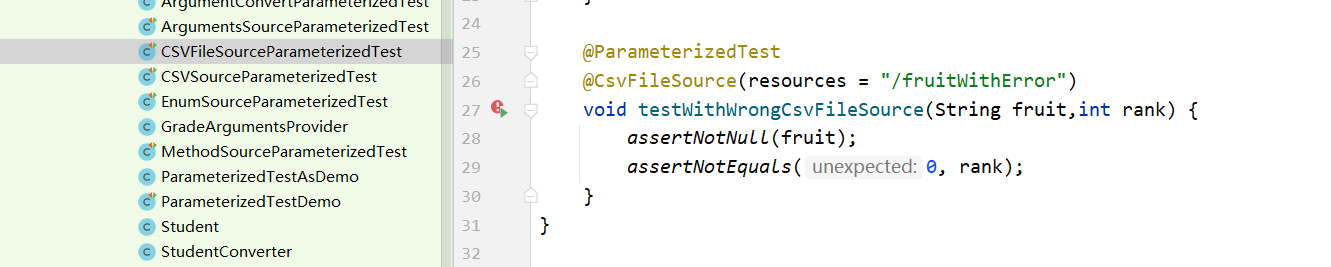
如果想要提取excel文件并跳过表头,numLinesToSkip = 1
@ArgumentsSource
通过实现 ArgumentProvider 接口自定义参数源

下面定义一个类实现接口
public class GradeArgumentsProvider implements ArgumentsProvider {
@Override
public Stream<? extends Arguments> provideArguments(ExtensionContext var1) {
return IntStream.of(90,60,85)
.mapToObj(
grade->
Arguments.of(grade,0.5*grade)
);
}
}然后可以在另一个类里使用 ,ArgumentsSource参数是实现了接口的类
@ParameterizedTest
@ArgumentsSource(GradeArgumentsProvider.class )
void testFinalGrateGradeWithArgumentProvider(int grade, double finalGrade){
assertEquals(2.0, grade/finalGrade,0.0001);
}
(2)参数类型转换
显示转换
实现 ArgumentConverter 接口/扩展 SimpleArgumentConverter
SimpleArgumentCoverter 是一个抽象类实现了 ArgumentCoverter接口
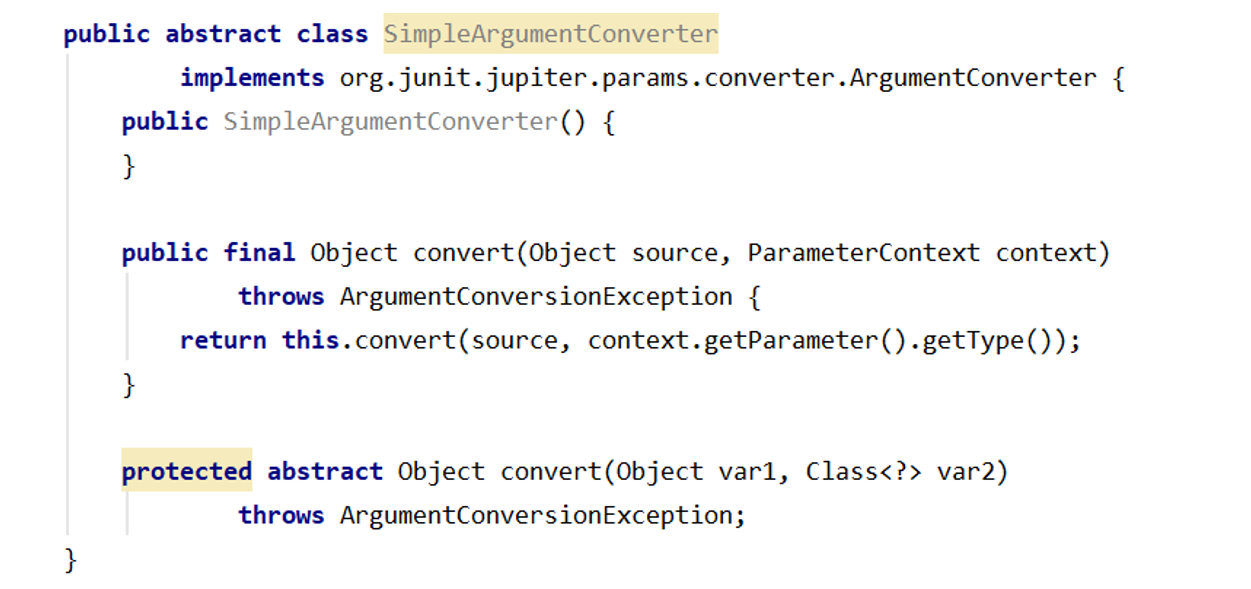
我们可以直接定义一个类继承 SimpleArgumentCoverter

在参数中@ConvertWith
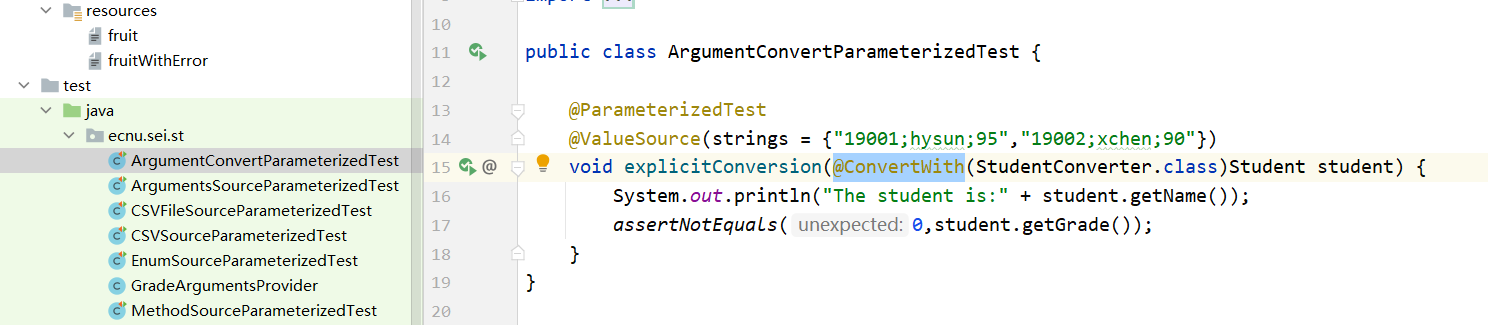
隐式转换
Junit5 内置隐式类型转换器:字符串转换为参数类型

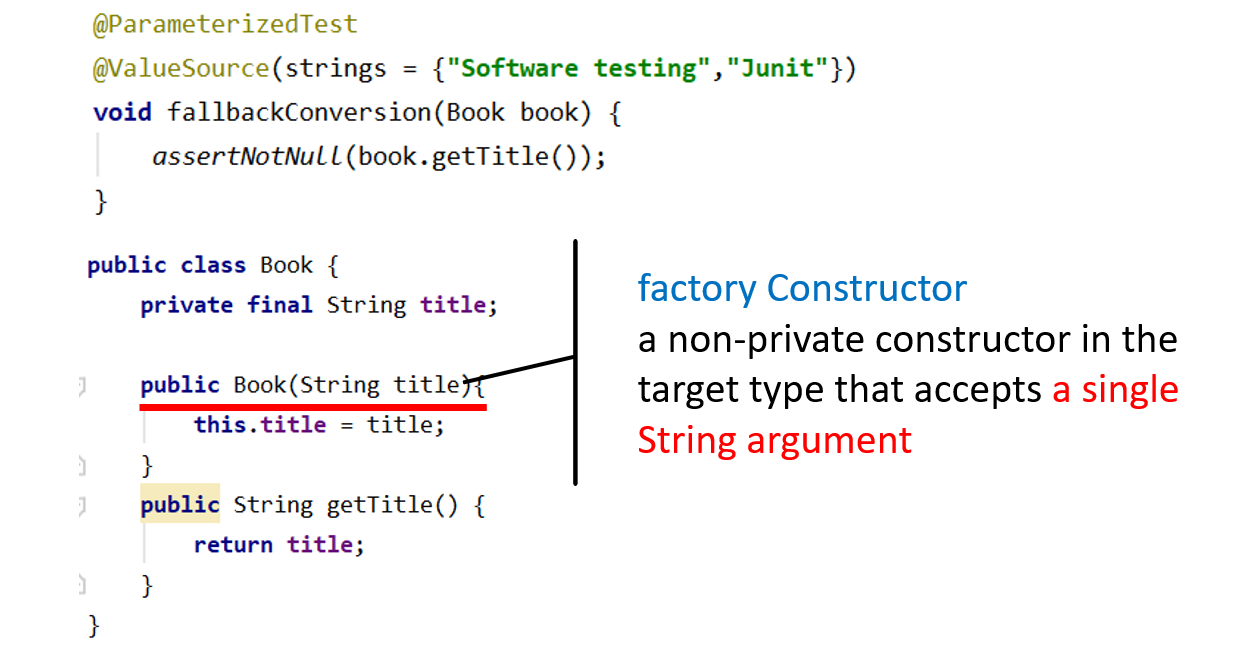
回退字符串到对象的转换Fallback String-to-Object Conversion:工厂方法和工厂构造函数
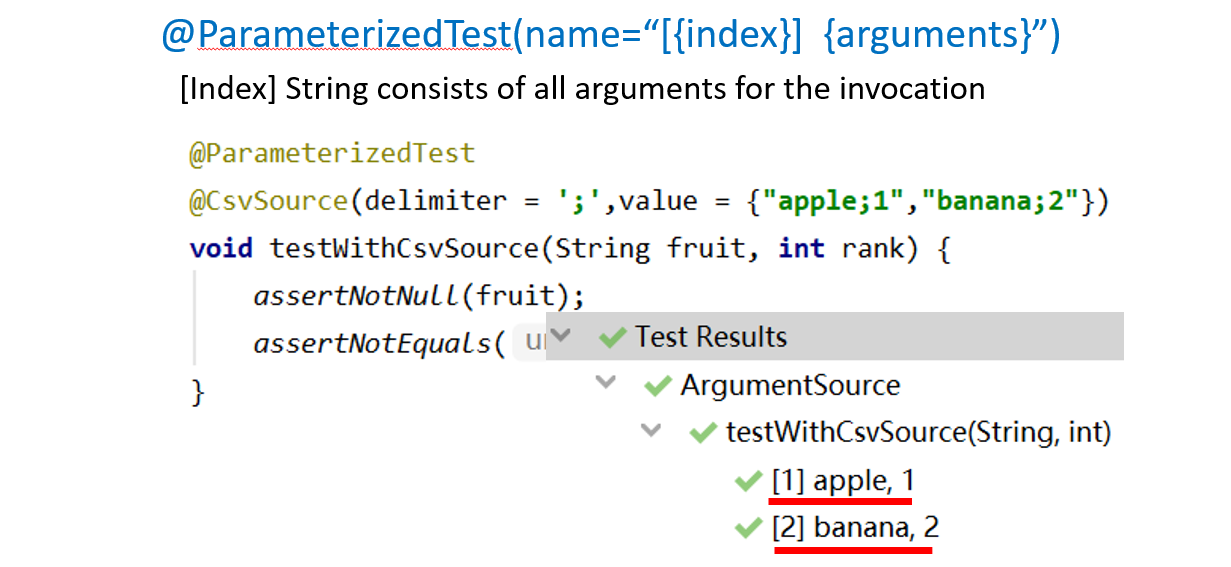
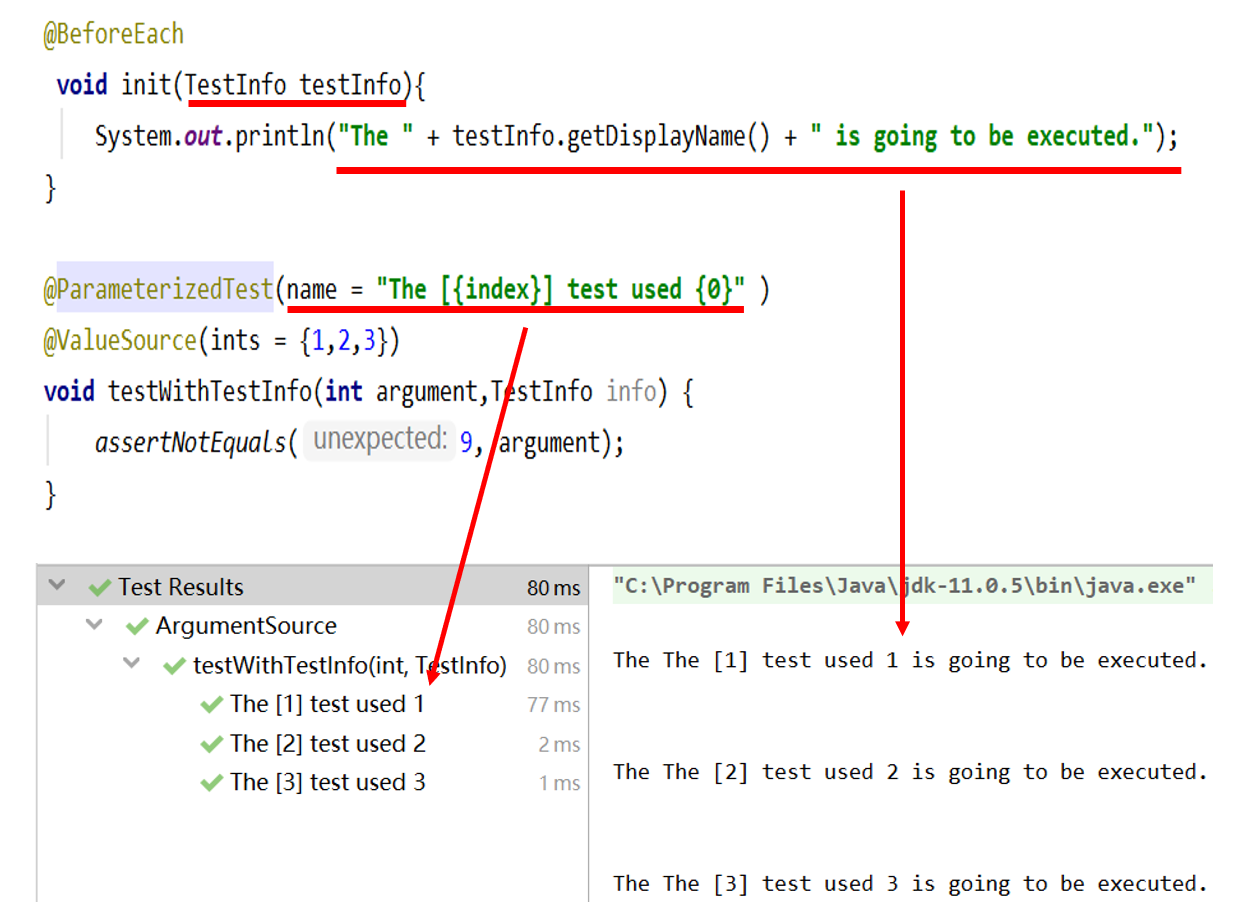
(3)给测试命名
@ParameterizedTest(name=“[{index}] {arguments}”)
每一次测试的名字,提高可读性
index第几次执行,后面argument是把所有参数值都列出来
举例1
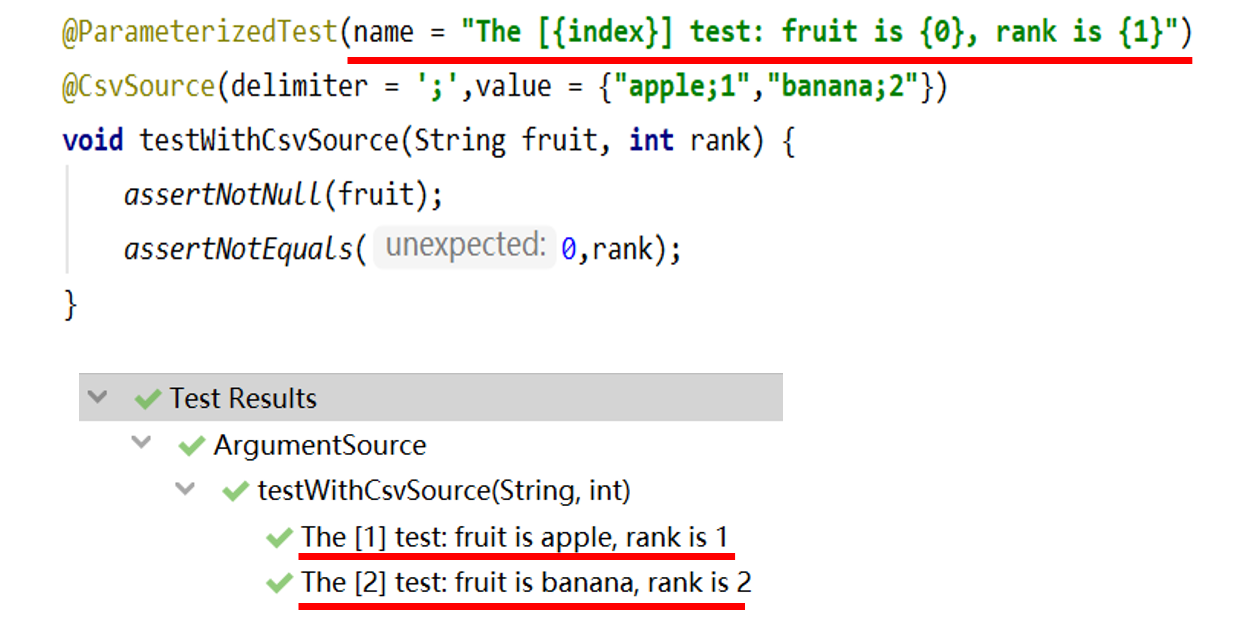
举例2
生命周期方法不可以参数化,但可以在生命周期测试方法中去获取信息,提高可读性:用到两个类TestInfo和TestReporter
5. mockito
meetheremaven中有一个类叫 add
基于行为的测试,不是基于状态的测试
基于行为需要mokito这样一个框架帮助我们,doc verify
设计脚本的三个阶段arrange action assert
6. 基于控制流的测试
recording4 7:14 开始的
前面用了单元测试主要用的技术和方法,现在要学测试用例自动生成方法
测试理论的三大支柱:基于控制流的(Control Based Tests Generation),基于数据流的(Data Flow Based Testing),基于遍历的(Mutation Testing)
基于控制流主要介绍基路径测试:基于程序控制结构设计可覆盖基本执行路径的测试的测试设计技术
- 构建控制流图(CFG)
- 计算基路径集,两个算法复杂度都不低
- 推出/计算测试用例
6.1 构建控制流图
控制流图是对代码中所有执行的一个抽象,用一张图表达出来
两个元素,一个是节点,一个是边,符合离散数学中图论的定义
节点是指代语句或一系列顺序执行的语句,如果第一个语句被执行,所有语句都将被执行
边指代代码当中控制的转移,是对指令顺序的一个抽象
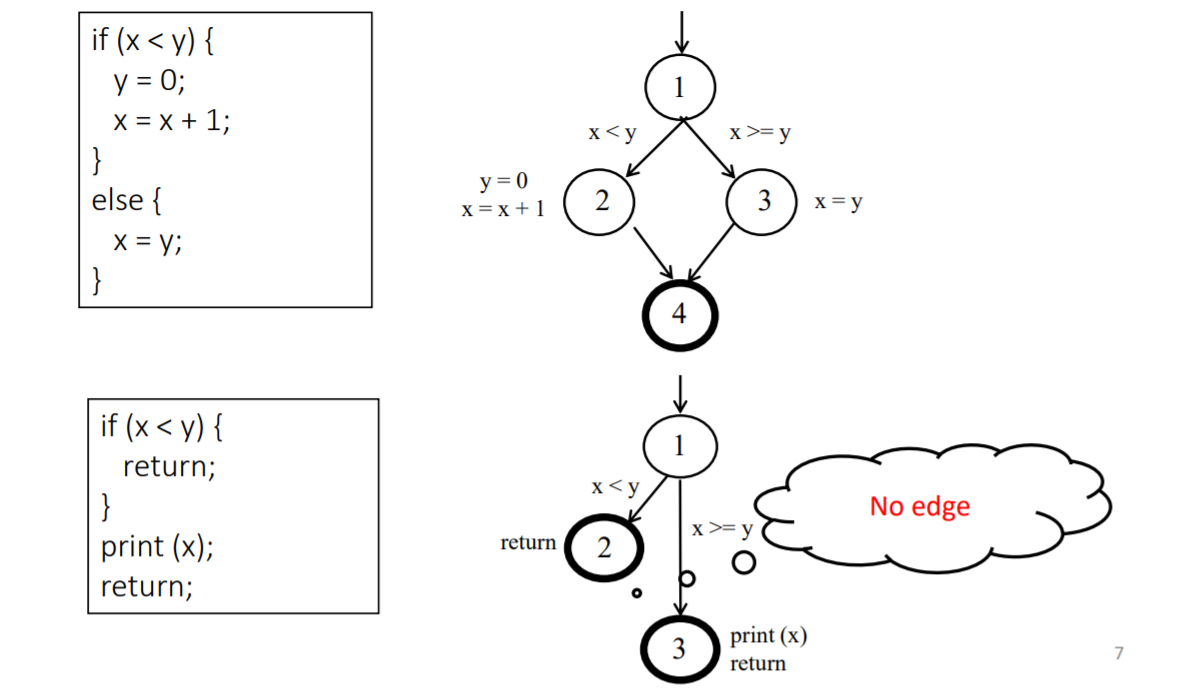
if语句
switch语句:分支可以有好多个
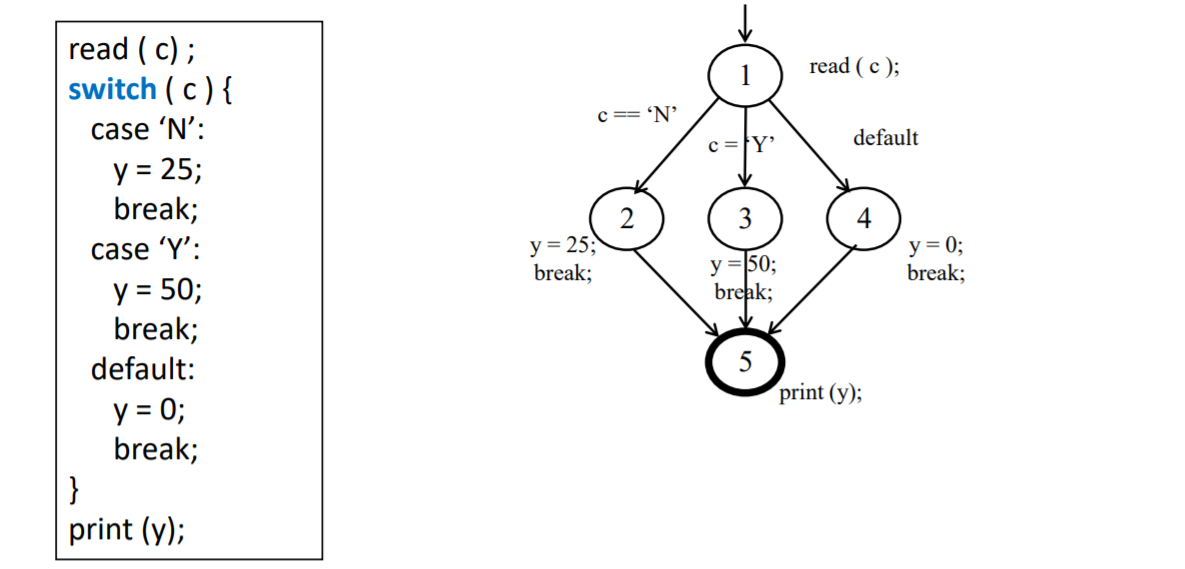
覆盖度工具中有个环复杂度,计算的是二值节点,switch就不是二值节点
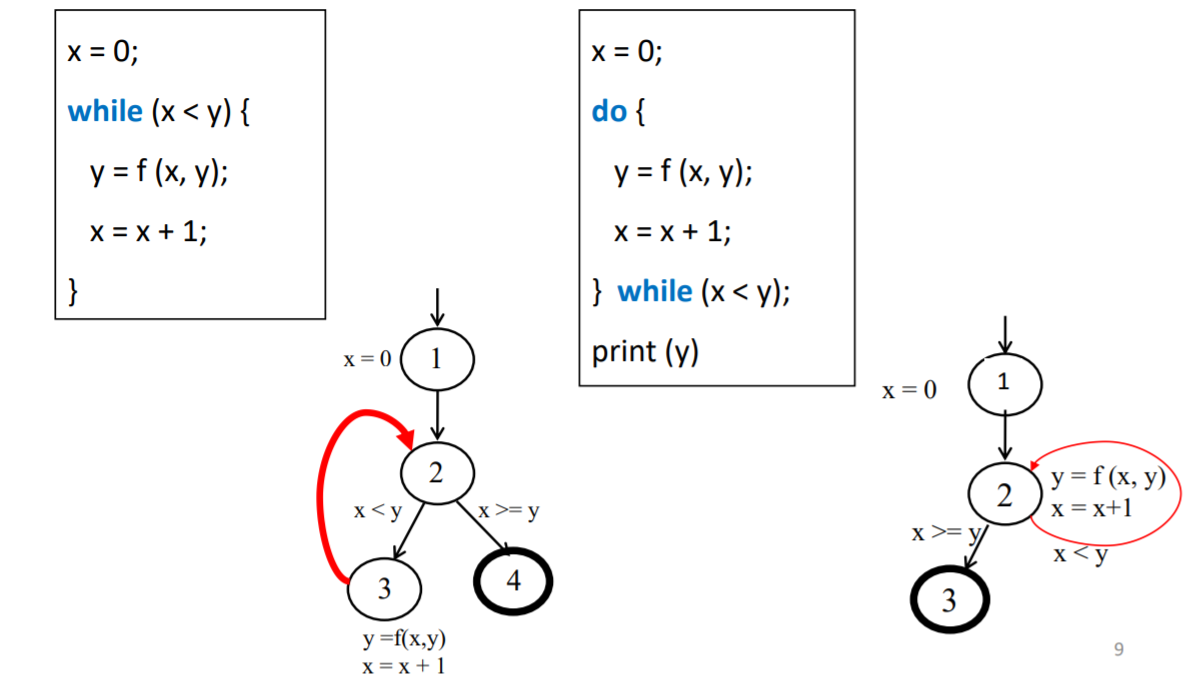
while语句和do-while语句
for语句
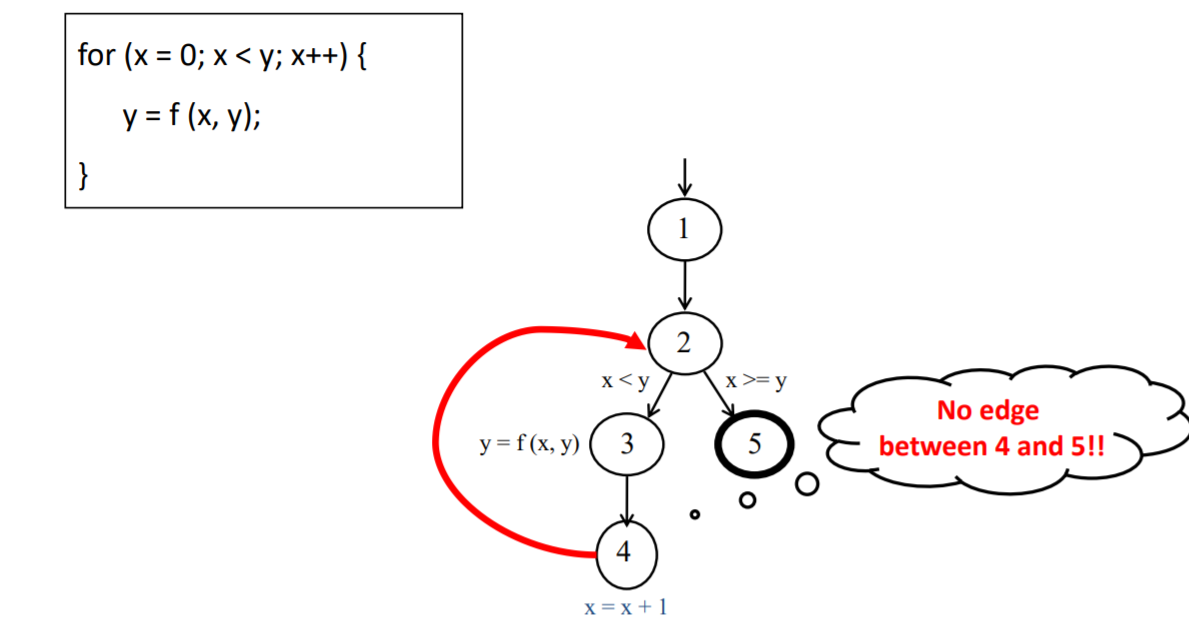
一个例子,注意红色箭头容易出错的部分
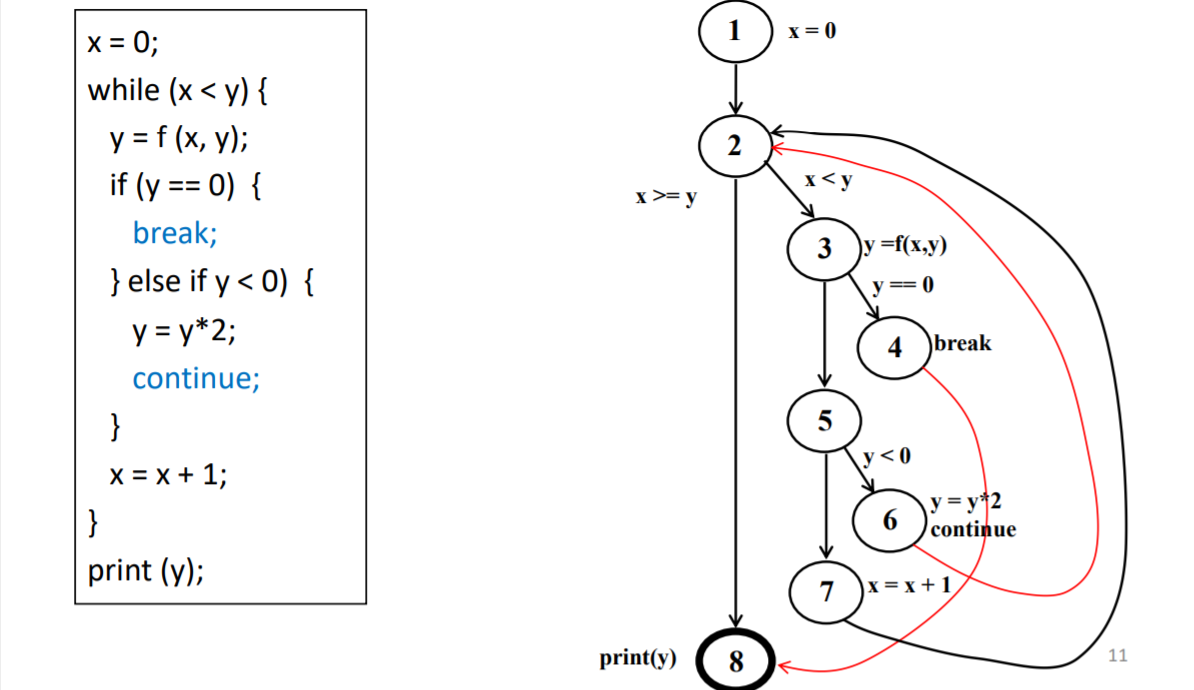
学会如何去切代码!
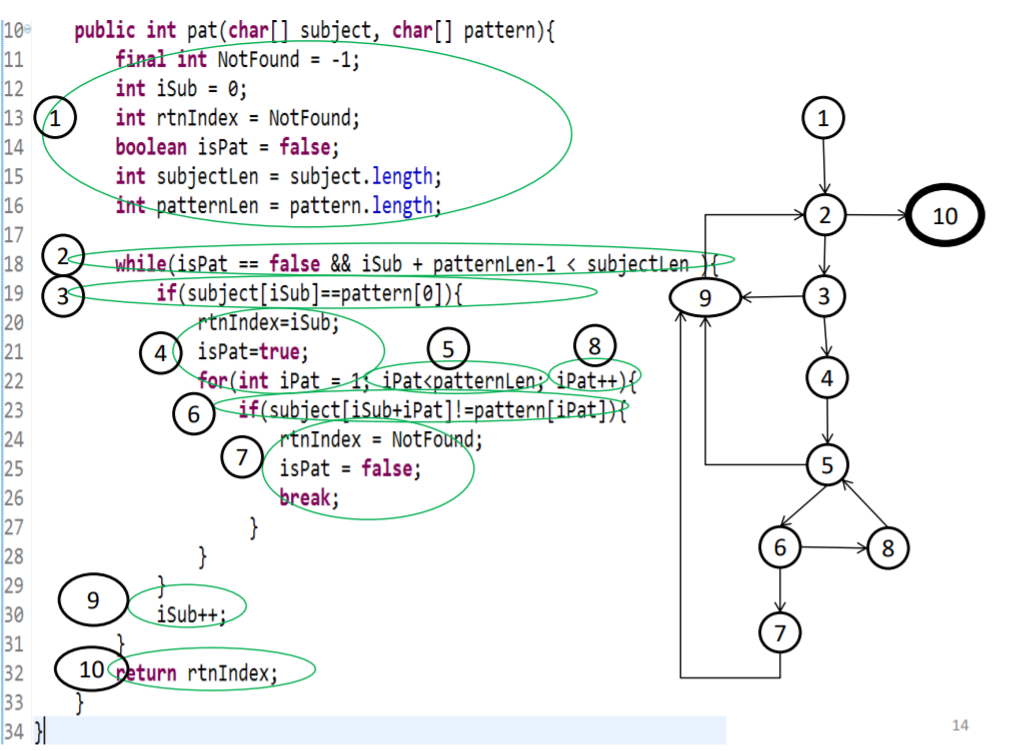
切代码exercise:
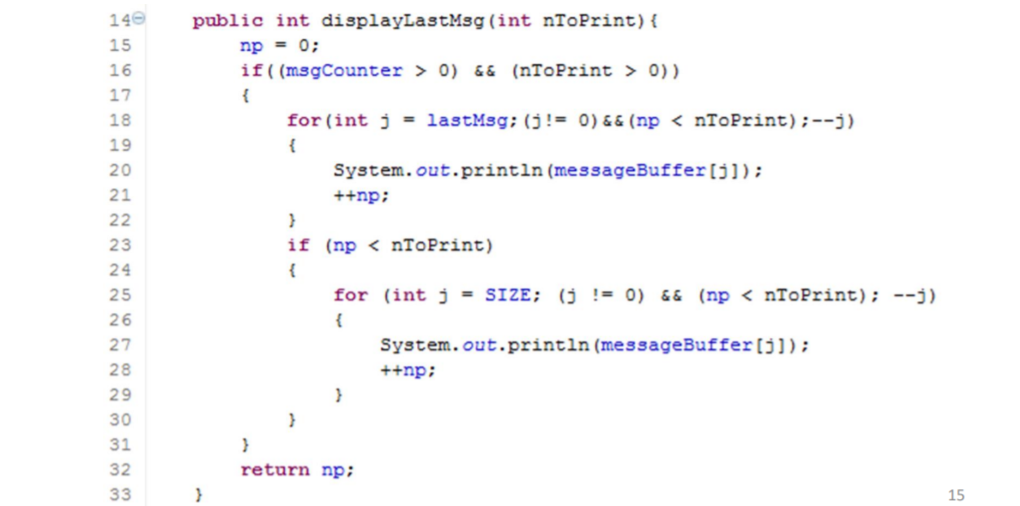

6.2 计算基路径
基于控制流测试的第二步:计算基路径
求出基路径:找到被测代码中必须要执行的测试路径
路径:首尾相连的边构成的节点序列
路径的长度:路径中包含的边的数量,允许长度为0的路径就是一个节点,一条语句就是一个节点
子路径:节点子序列构成的路径
根据控制流图,可以得到相应的路径,从长度为1到长度为10的路径都有,这里的路径不是程序的完整路径,只是节点的序列
而基路径是要在成千上万的路径中找出比较有代表性的路径集合,因为资源有限不可能每一条路径都去测试

complete path完整路径:这条路径的开始必须是开始节点,终止必须是终止节点
Infeasible Complete Path不可达路径:水浒传第134位?
simple path简单路径:是一种特殊的路径,除了第一个节点和最后一个节点外,中间节点出现的次数有且只有一次。(目的是剔除中间包含循环的那些路径)
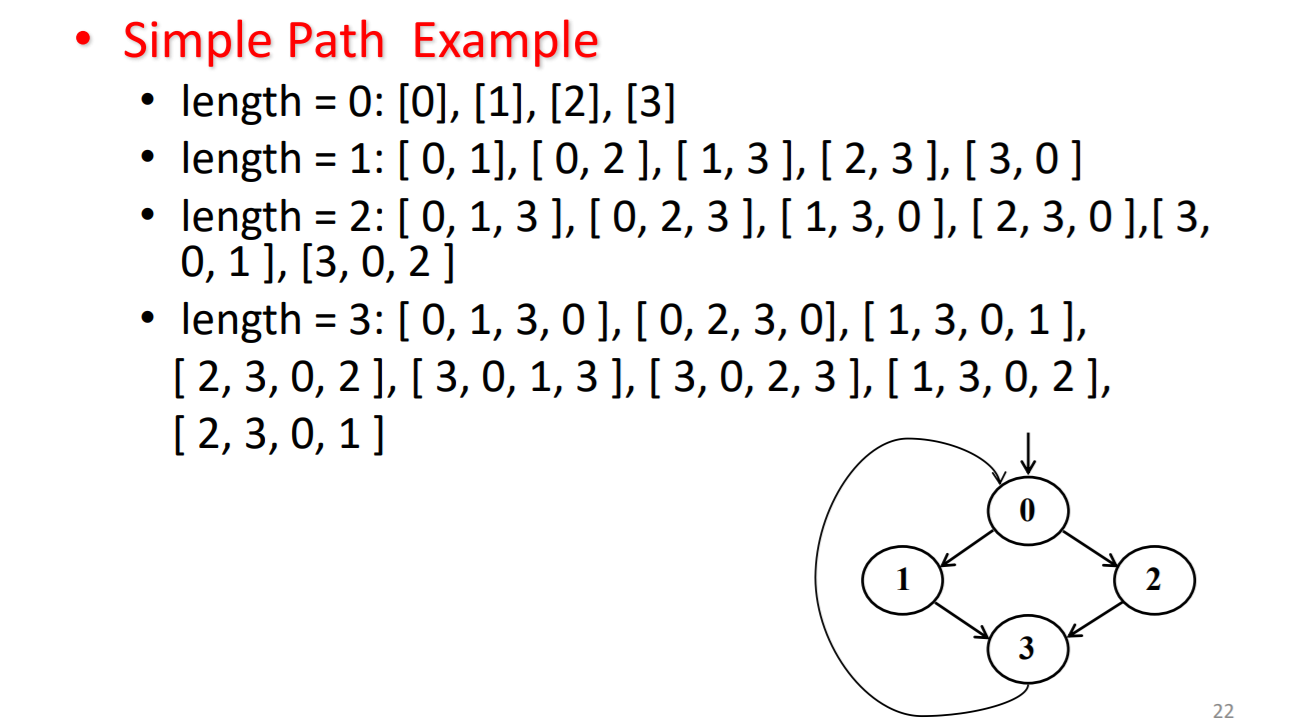
怎样去处理这么庞大数量的路径呢,基路径帮助我们减少要去测试的路径
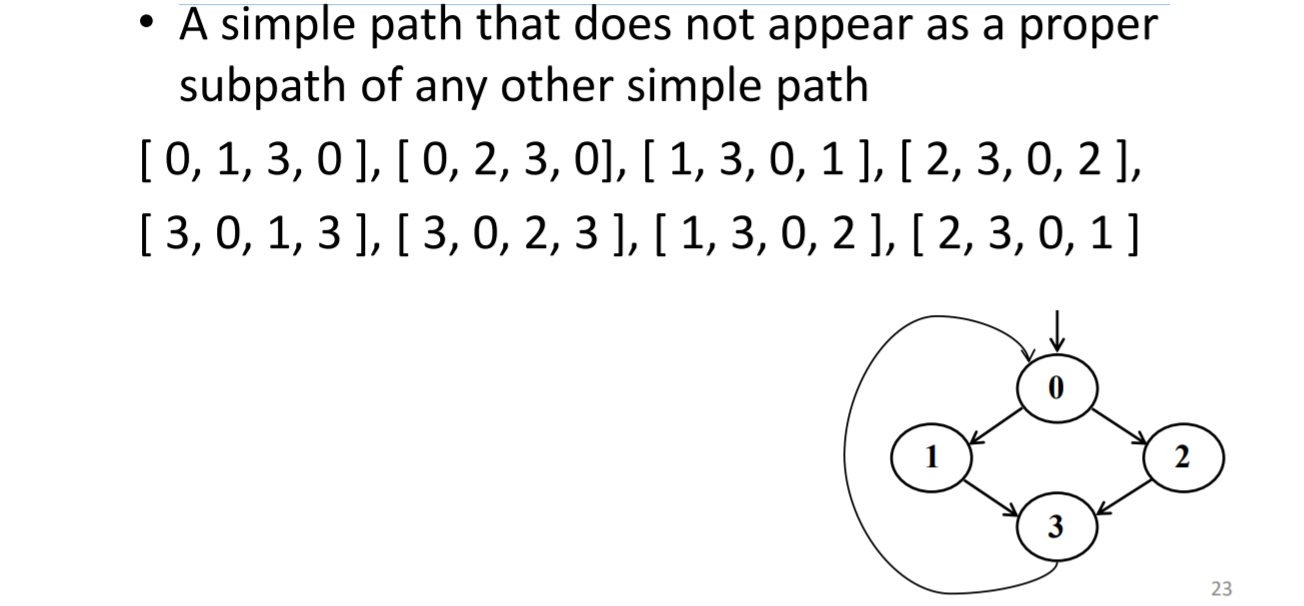
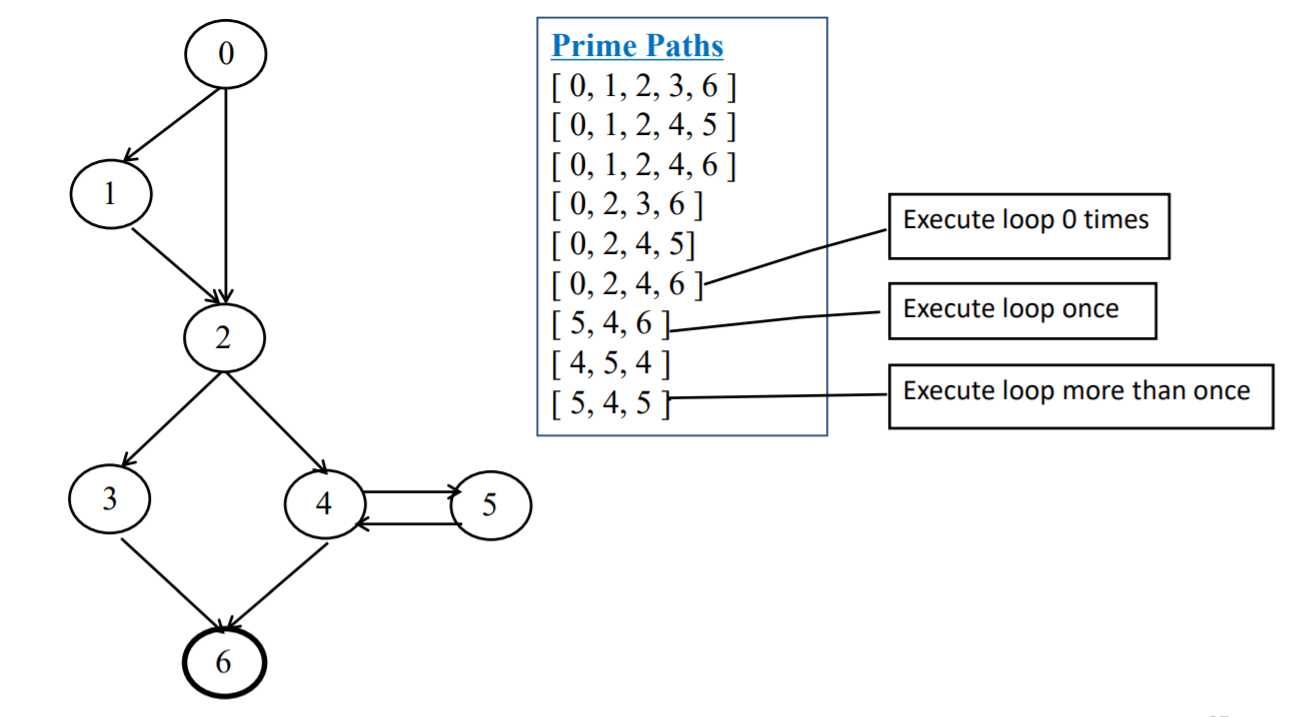
prime path基路径
不作为任何其他简单路径的正确子路径的简单路径,基路径不一定是一条完整路径
所以上一道题只有长度为3的简单路径是基路径
控制流图的所有路径都可以通过基路径的加或者乘得出,跟向量中的”基”含义一样
How to calculate prime path
- Exhaust method (穷举)
- Node tree method (节点树法,同学想出来的)
学期作业可以构造复杂度更低的方法来完成
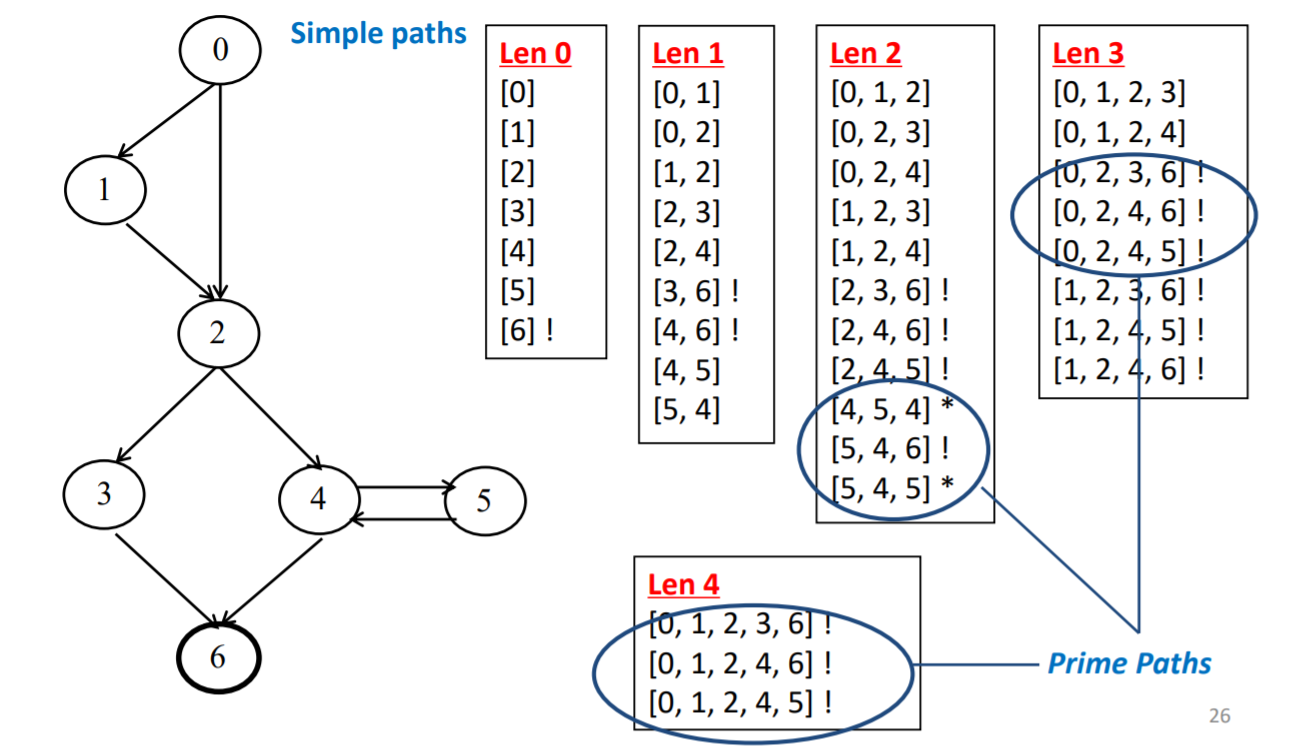
(1)暴力法step
- 从len 0 开始列出所有的简单路径
- 将列出来的不能再扩展的路径标记感叹号
- 继续扩展列出 len 1 len 2 … len 4,直到所有的集合都被标记上感叹号
- 长度最长的一定是基路径
- 再找出其他长度(从高到低找)里不是别人子路径的简单路径
(2)节点树法 step
方法介绍:
节点树
以G中的节点为根节点建立的树,且满足树中除根节点和叶节点 可以相同外,从根节点到每个树中节点的路径中,每个节点的出现次数有且仅有 1 次。在节点树中,每条从根节点到叶节点的路径即为一条简单路径
简单节点树
若节点树T不是任何其它节点树的子树,则称节点树T为简单节点树
所有简单节点树的从根节点到叶节点的路径集合为备选的基路径 集合
步骤
- 画出每个结点的节点树
- 0节点数都是基路径,再一个一个找没有被0节点数的路径包含的基路径

6.3 自动生成测试集合
“ Deriving Test Cases ”
测试生成算法目标:Prime Path Coverage (PPC) 每条基路径应至少被一个测试用例执行一次
步骤:
- 把基路径扩展成完整路径:从最长的基路径开始,将其扩展成包含CFG的初始节点和终止节点的完全路径
- 计算使得路径能够被执行的输入作为测试输入
方法:
观察法
约束求解法:将路径构造为约束表达式,再用工具求解
当构成路径表达式的各个变量的取值使得路径表达式的结果为真,说明在该取值下,程序执行该条路径
我们这个课约束求解器用的是Z3
生成工具:把代码通过soot编译成中间形式,利用soot提供的生成控制流图工具构造被测源码的控制流图,第二步找基路径,他这里没有写基路径,只用了soot里面直接提供有个getExtendedBasicBlockPathBetween()方法,直接提供了从开始节点到终止节点的路径,这里没有写基路径,这是交给大家学期作业去写的,测下来对循环不大友好会出错
demo
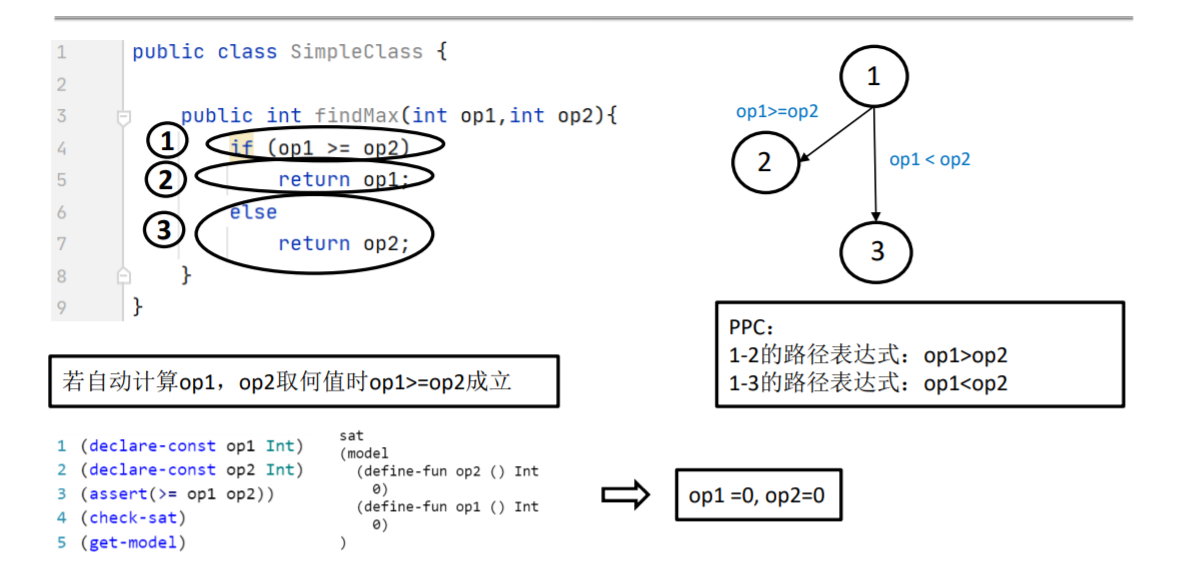
假设根据控制流算出了两条路径,接下来就要去找约束表达式:
不再用 1→2 表示路径,而是用 op1>=op2 来表示这条路径
三指令表达式 smp
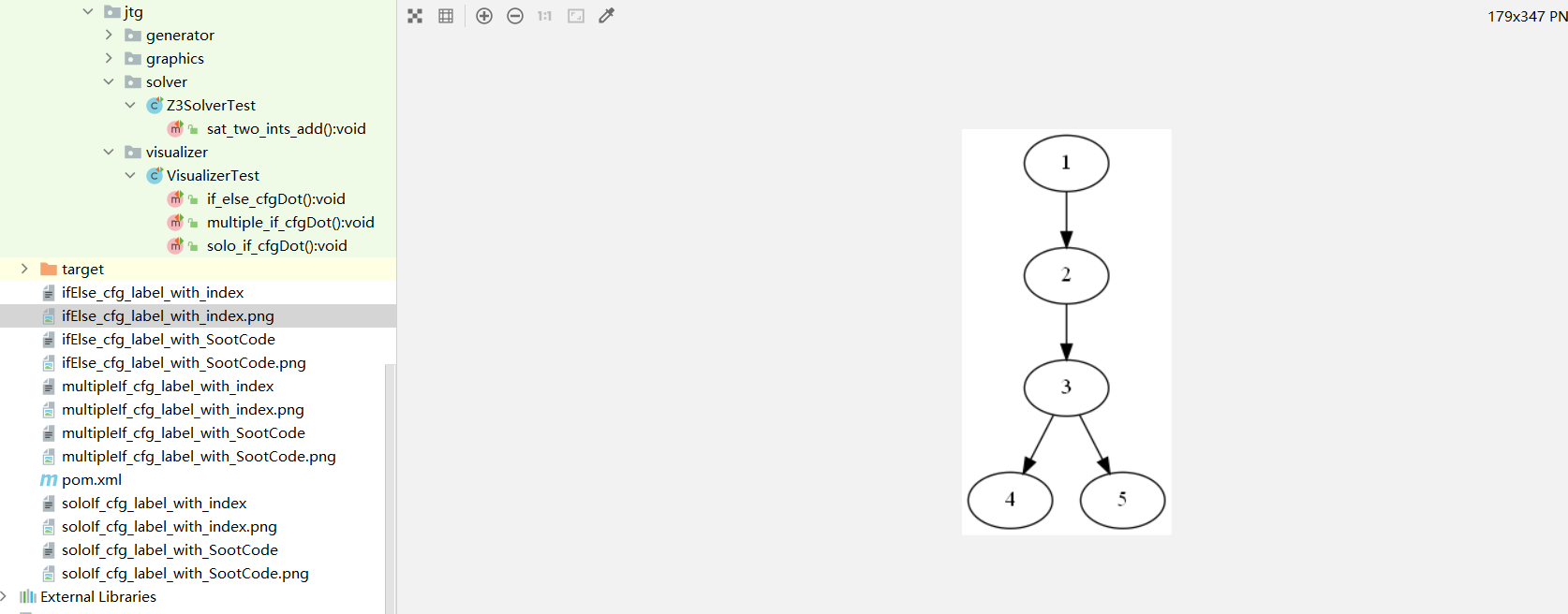
工具针对的是方法,给定任意一个java方法,可以可视化控制流图
graphic里面是基于soot框架,去解析被测的测试方法,soot里面的unitgraph类去构造控制流图ug
static方法getMethodCFG()里面传入的参数,第一个是类的路径,第二个参数是类名,第三个是方法名
visualizer
printCFGDot(),用dot画出控制流图,第三个参数indexLabel表示dot中显示节点序号(true),还是Soot代码(false)
getLabelFromUnit(Unit unit) 这个方法需要扩展,先调用sootCFG去生成控制流图得到这样一个类,然后再把这个类printCFGDot,
test -> visualizer
multiple_if_cfgDot() 其实是把soot里面的getCFG()方法拷贝过去的
@Test
void multiple_if_cfgDot() {
//78-98行代码都是 soot编译生成控制流图
//大概的意思就是把用jimple编译过的方法的方法体传递给soot里面的类
String sourceDirectory = System.getProperty("user.dir") + File.separator + "target" + File.separator + "test-classes";
System.out.println(sourceDirectory);
String clsName = "cut.LogicStructure";
String methodName = "multipleIf";
//setupSoot
System.out.println(sourceDirectory);
G.reset();
Options.v().set_prepend_classpath(true);
Options.v().set_allow_phantom_refs(true);
Options.v().set_soot_classpath(sourceDirectory);
SootClass sc = Scene.v().loadClassAndSupport(clsName);
sc.setApplicationClass();
Scene.v().loadNecessaryClasses();
// Retrieve method's body
SootClass mainClass = Scene.v().getSootClass(clsName);
SootMethod sm = mainClass.getMethodByName(methodName);
JimpleBody body = (JimpleBody) sm.retrieveActiveBody();
//把数据流图画出来
UnitGraph ug = new ClassicCompleteUnitGraph(sm.retrieveActiveBody());
Visualizer.printCFGDot("multipleIf_cfg_label_with_index",ug,true);
Visualizer.printCFGDot("multipleIf_cfg_label_with_SootCode",ug,false);
}
@变量名是soot自己加的变量,不是我们源代码中的变量
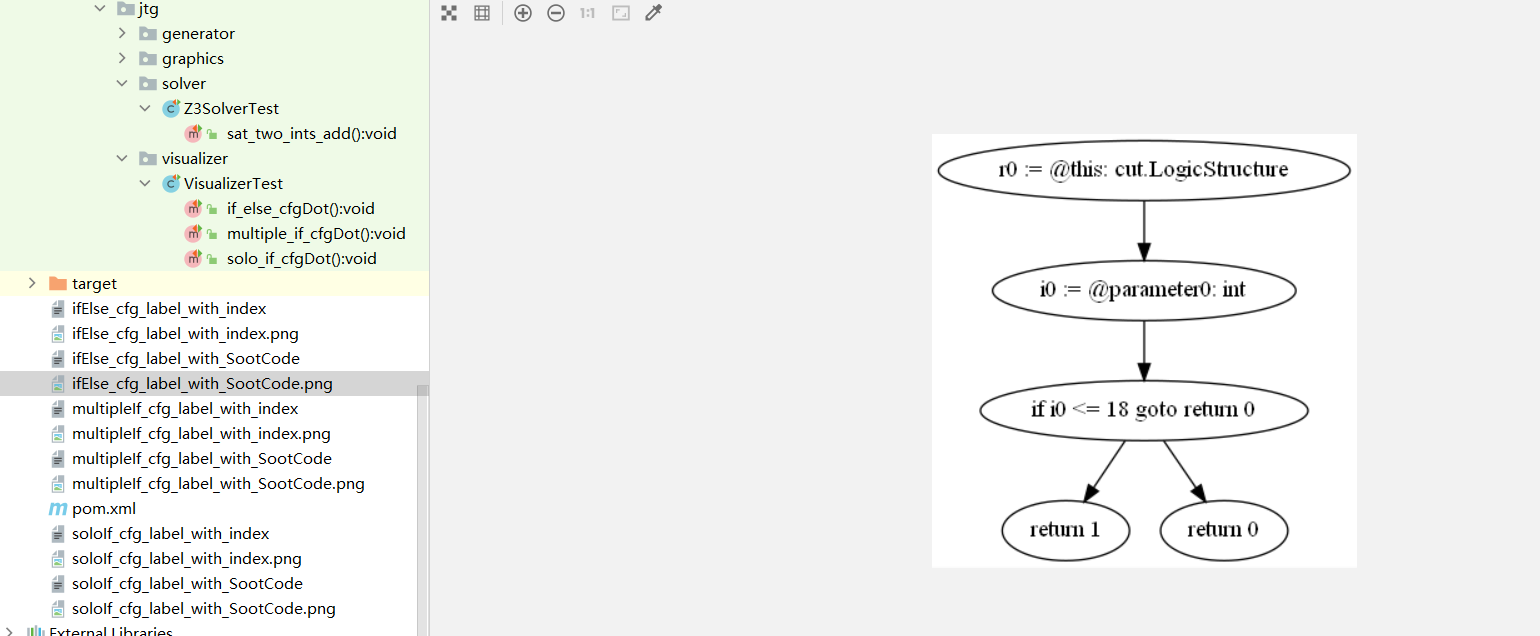
我们的工作就是要把控制流图中的信息提取出来,构造路径表达式,放到z3里去约束求解
test -> cut 被测代码 class and test 的缩写?
是我们这个工具的测试数据,是一段段程序,不是一个个数据
测试数据LogicStructure里面的multipleIf()就是我们要测试的方法
SimpleGenerator 和 solver 是核心 一个是求解,一个是生成测试用例
SimpleGenerator
两个构造函数
public SimpleGenerator(String className, String methodName) {
String defaultClsPath = System.getProperty("user.dir") + File.separator + "target" + File.separator + "classes";
new SimpleGenerator(defaultClsPath, className, methodName);
}
public SimpleGenerator(String classPath, String className, String methodName) {
clsPath = classPath;
clsName = className;
mtdName = methodName;
ug = SootCFG.getMethodCFG(clsPath, clsName, mtdName);
body = SootCFG.getMethodBody(clsPath, clsName, mtdName);
}核心生成代码
public List<String> generate() { //核心代码 生成测试用例的地方
List<Unit> path = null;
ArrayList<String> testSet = null;
String pathConstraint = "";
System.out.println("============================================================================");
System.out.println("Generating test case inputs for method: " + clsName + "." + mtdName + "()");
System.out.println("============================================================================");
try {
testSet = new ArrayList<String>();
for (Unit h : ug.getHeads()) //76-79行在找路径 找soot提供的从开始到终止的基本路径 找的不是基路径
for (Unit t : ug.getTails()) {
path = ug.getExtendedBasicBlockPathBetween(h, t);
System.out.println("The path is: " + path.toString()); //path取出来是unit序列 soot语句
pathConstraint = calPathConstraint(path); //判断它是不是分支路径 计算约束表达式
//如果路径约束为空字符串,表示路径约束为恒真
//如果是分支路径,对路径进行求解,如果是true就开始随机生成
if (pathConstraint.isEmpty()) testSet.add(randomTC(body.getParameterLocals()));
System.out.println("The corresponding path constraint is: " + pathConstraint);
if (!pathConstraint.isEmpty())
testSet.add(solve(pathConstraint));
}
} catch (Exception e) {
System.err.println("Error in generating test cases: ");
System.err.println(e.toString());
}
if (!testSet.isEmpty()) {
System.out.println("");
System.out.println("The generated test case inputs:");
int count = 1;
for (String tc : testSet) {
System.out.println("( " + count + " ) " + tc.toString());
count++;
}
}
return testSet;
}计算路径函数
大概逻辑是,我现在已经获得了一条路径信息,当我要去计算约束的时候,如果有if判断语句,我就要去判断是不是我当前这条语句的下面一条语句,如果是说明if条件取得是真,如果不一样说明if条件取得是假
然后发现它的变量名是jimple生成的变量,不是我们真正的变量,所以还要做一次替换
public String calPathConstraint(List<Unit> path) {
List<Local> jVars = getJVars();
String pathConstraint = "";
String expectedResult = "";
HashMap<String, String> assignList = new HashMap<>();
ArrayList<String> stepConditionsWithJimpleVars = new ArrayList<String>();
ArrayList<String> stepConditions = new ArrayList<String>();
for (Unit stmt : path) {
if (stmt instanceof JAssignStmt) {
assignList.put(((JAssignStmt) stmt).getLeftOp().toString(), ((JAssignStmt) stmt).getRightOp().toString());
continue;
}
if (stmt instanceof JIfStmt) {
String ifstms = ((JIfStmt) stmt).getCondition().toString();
int nextUnitIndex = path.indexOf(stmt) + 1;
Unit nextUnit = path.get(nextUnitIndex);
//如果ifstmt的后继语句不是ifstmt中goto语句,说明ifstmt中的条件为假
if (!((JIfStmt) stmt).getTarget().equals(nextUnit))
ifstms = "!( " + ifstms + " )";
else
ifstms = "( " + ifstms + " )";
stepConditionsWithJimpleVars.add(ifstms);
continue;
}
if (stmt instanceof JReturnStmt) {
expectedResult = stmt.toString().replace("return", "").trim();
}
}
System.out.println("The step conditions with JimpleVars are: " + stepConditionsWithJimpleVars);
//bug 没有考虑jVars为空的情况
if (jVars.size() != 0) {
for (String cond : stepConditionsWithJimpleVars) {
//替换条件里的Jimple变量
for (Local lv : jVars) {
if (cond.contains(lv.toString())) {
stepConditions.add(cond.replace(lv.toString(), assignList.get(lv.toString()).trim()));
}
}
}
} else
stepConditions = stepConditionsWithJimpleVars;
if (stepConditions.isEmpty())
return "";
pathConstraint = stepConditions.get(0);
int i = 1;
while (i < stepConditions.size()) {
pathConstraint = pathConstraint + " && " + stepConditions.get(i);
i++;
}
//System.out.println("The path expression is: " + pathConstraint);
return pathConstraint;
}运行
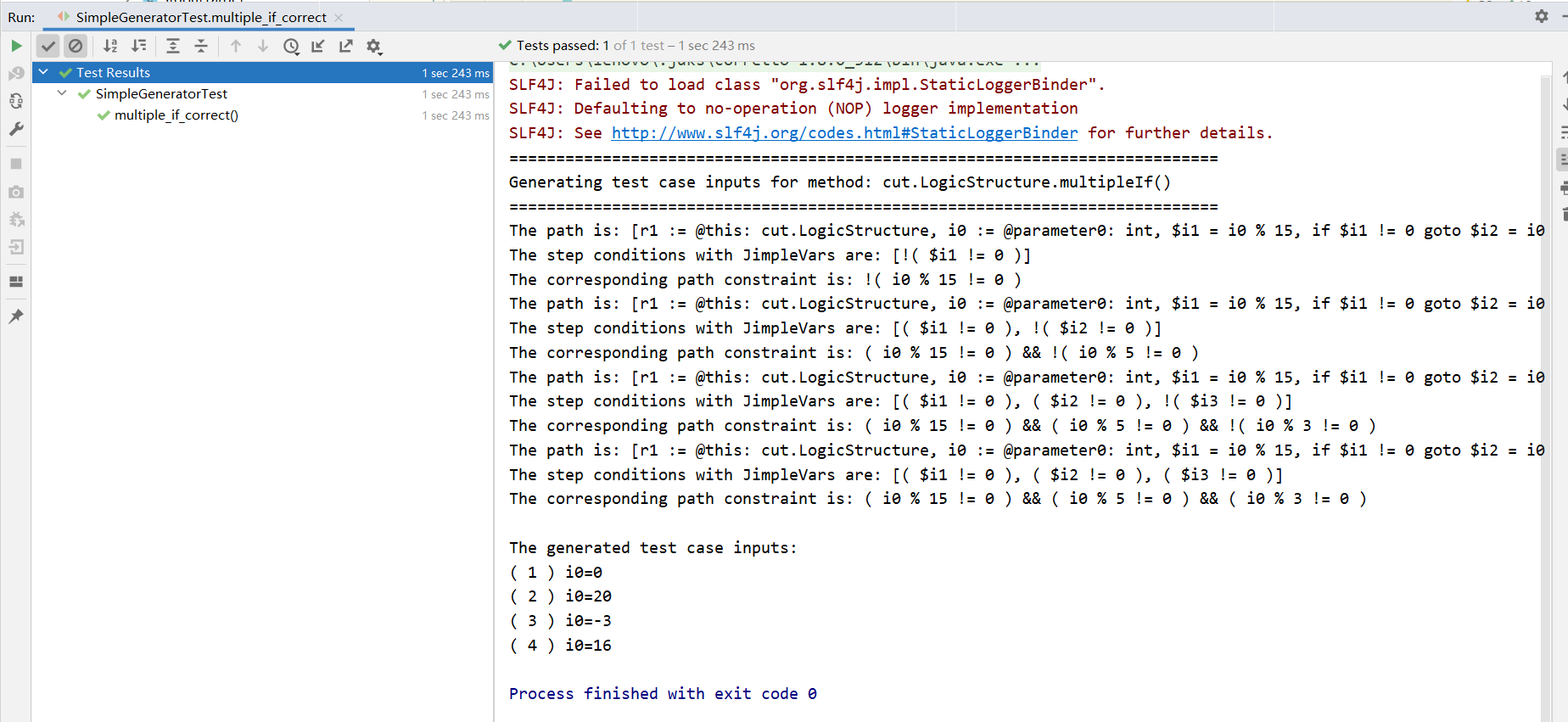
soot提供的jimple
|
基路径生成的测试集合不够,其他测试方法自动生成测试用例
节点覆盖 node
边覆盖 edge
边对覆盖 长度为2的所有路径都要测量
全对偶测试
测试揭错能力图,灰色的部分是数据流图

7.基于数据流的测试
控制流考虑的是代码中的分支机构,数据流考虑对变量进行定义和使用的测试
本章包含的问题:如何构造数据流图、怎样基于数据流图找数据输入、哪些数据流覆盖准则
数据流不是测试当中特有的概念,是编译原理里面的
跟数据流相关的概念:
变量的定义def:将变量的值存入内存的语句,对变量的写操作 x=44 input
变量的使用use:读取或访问变量的值的语句,不改变变量的值,比如条件语句
数据流测试的关键就是,检测变量的定义有没有用,是不是该用,是不是正确
有些语句既读又写
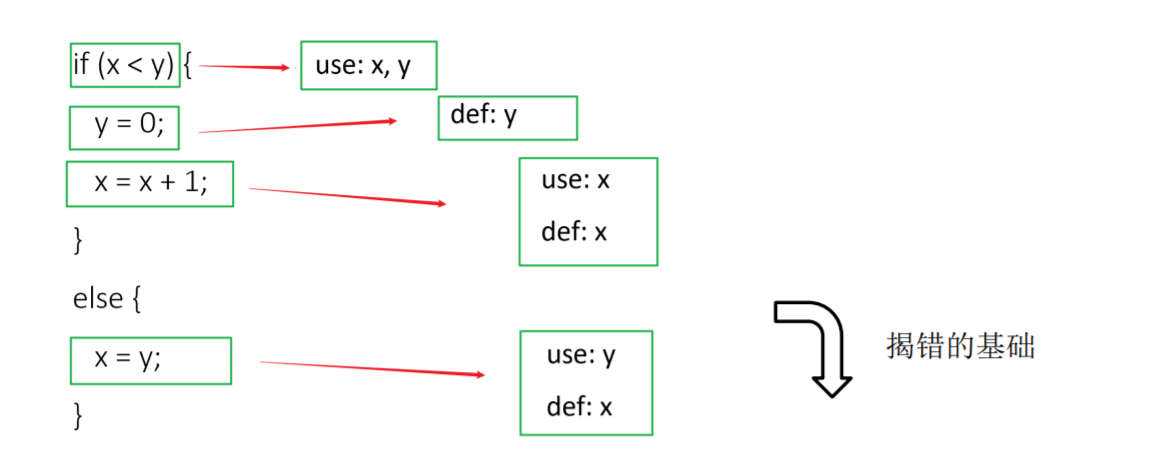
区别c-use和p-use

exercise 1
注意6不是p的定义节点
程序缺陷在于没有回收内存空间
exercise 2

数据流图
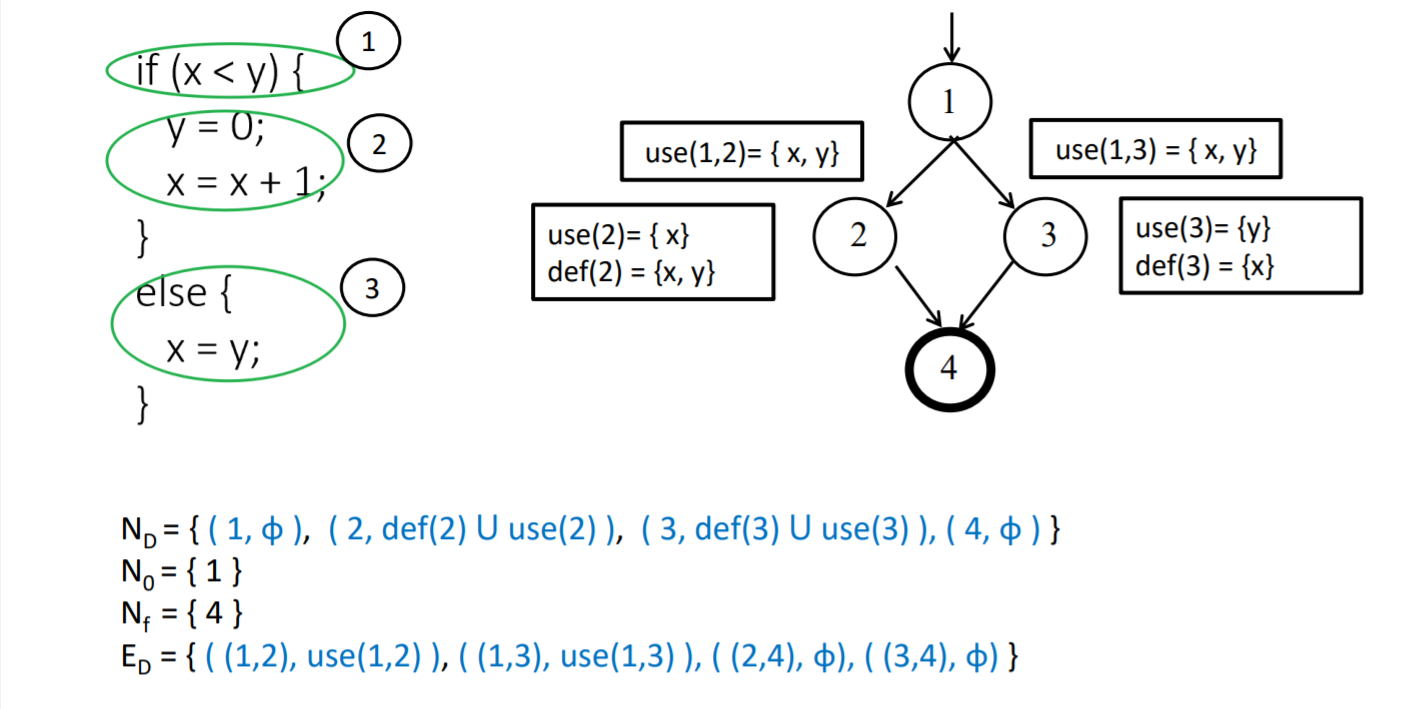
控制流测试设计的思想:执行程序路径到达期望的控制覆盖准则
数据流测试设计的思想:执行程序路径到达期望的数据流覆盖准则
du pair 定义使用对:一个二元组 (li,lj),在li处定义,在lj处使用
def clear定义清除路径:从li开始,在lg结束,如果变量是定义清除的,那么除了 li 以外其他的节点都是不是定义节点
:star:du path 定义使用路径:首先是简单路径,必须是定义清除的
定义使用路径的两种表示方式,第二个集合应该等于第一个集合的并集

例题
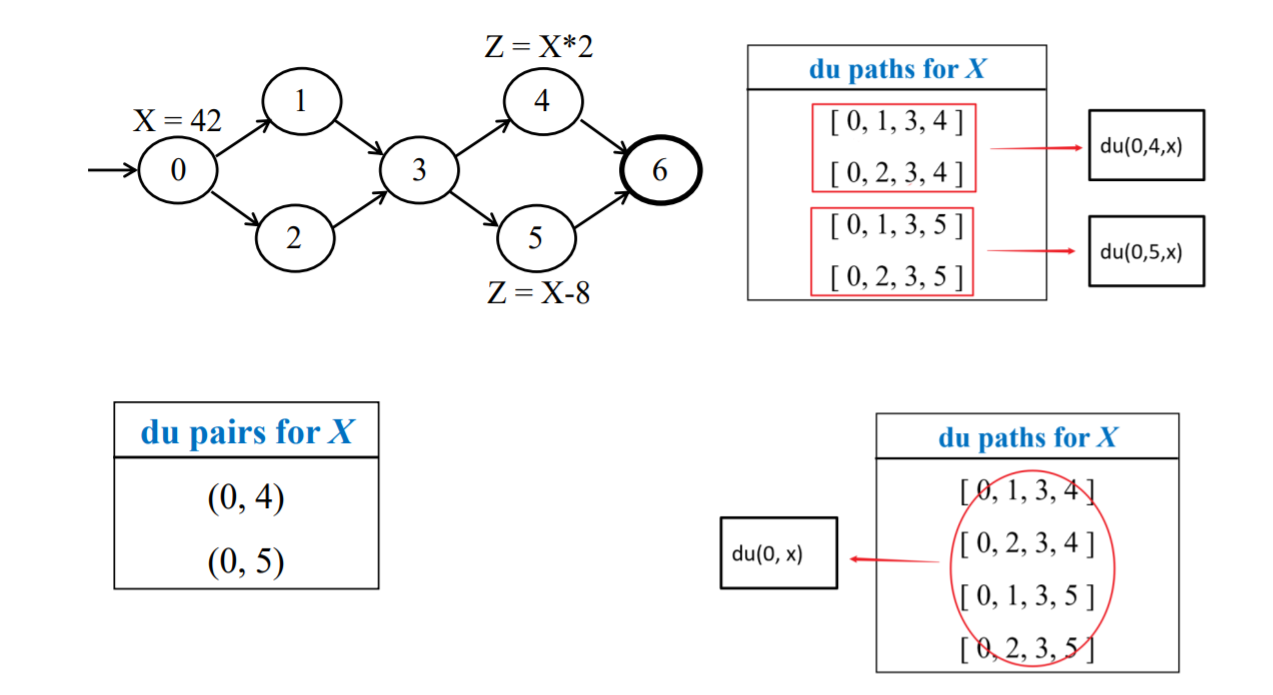
数据流覆盖准则
全定义覆盖 ADC:对每个变量v而言,每个定义必须被至少执行一次
全使用覆盖 AUC:对每个变量而言,所有的使用必须在测试用例中出现一次
全定义使用路径覆盖 ADUPC:对于每个变量而言,执行所有的定义使用路径
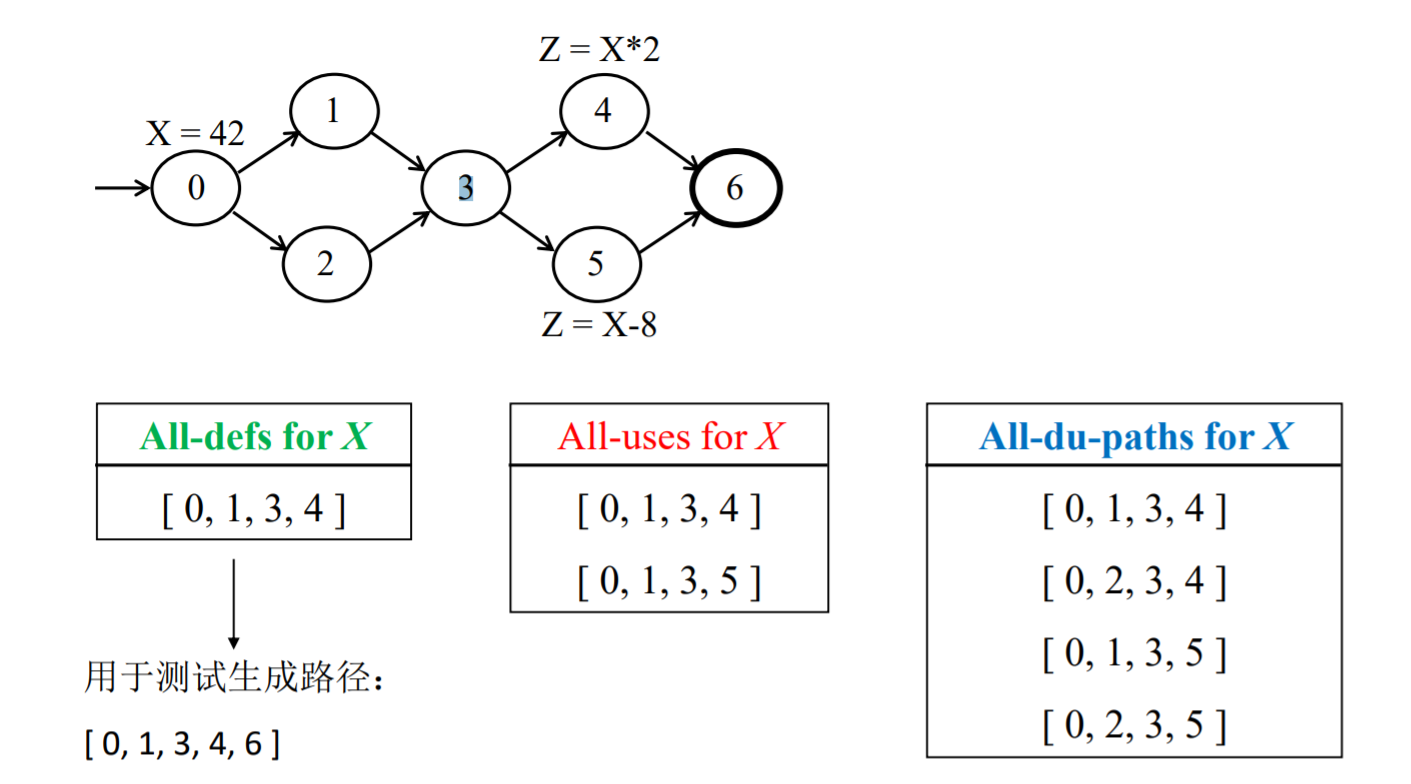
exercise:
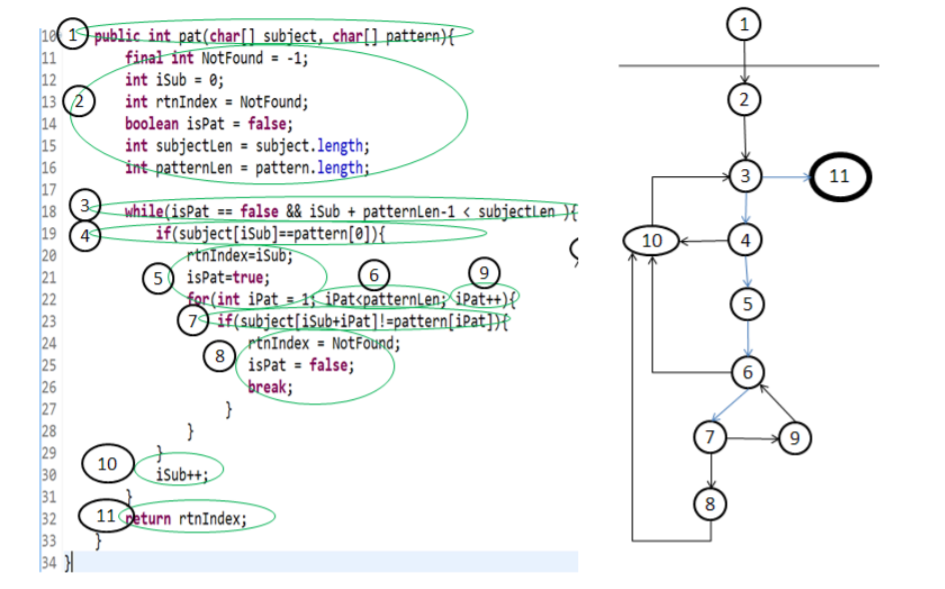
第一步画出控制流图
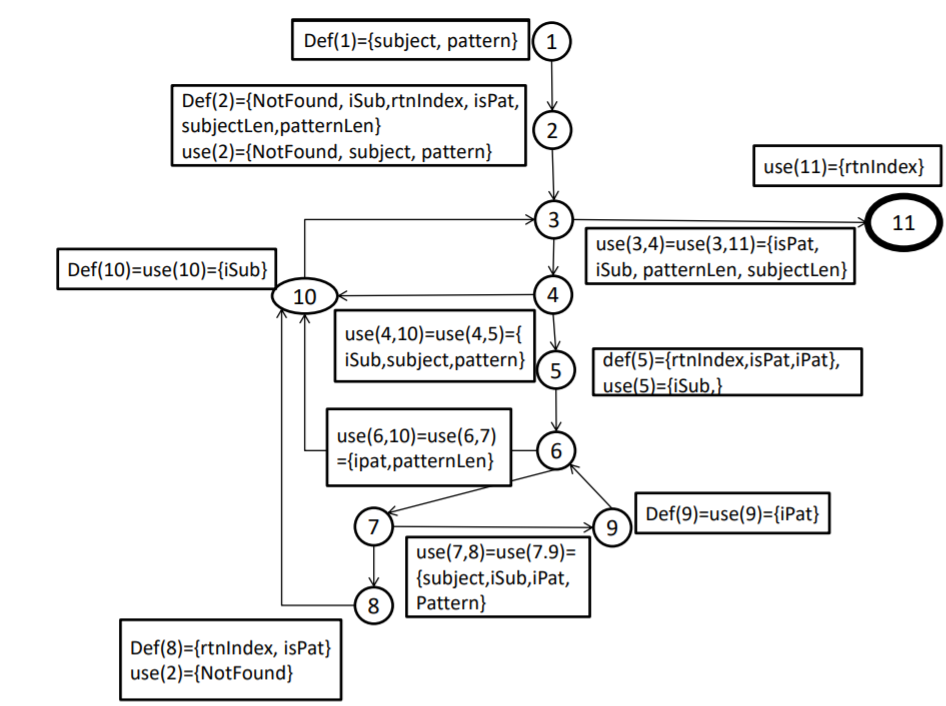
第二步画出数据流图
第三步
列出定义使用对
以2为开头的
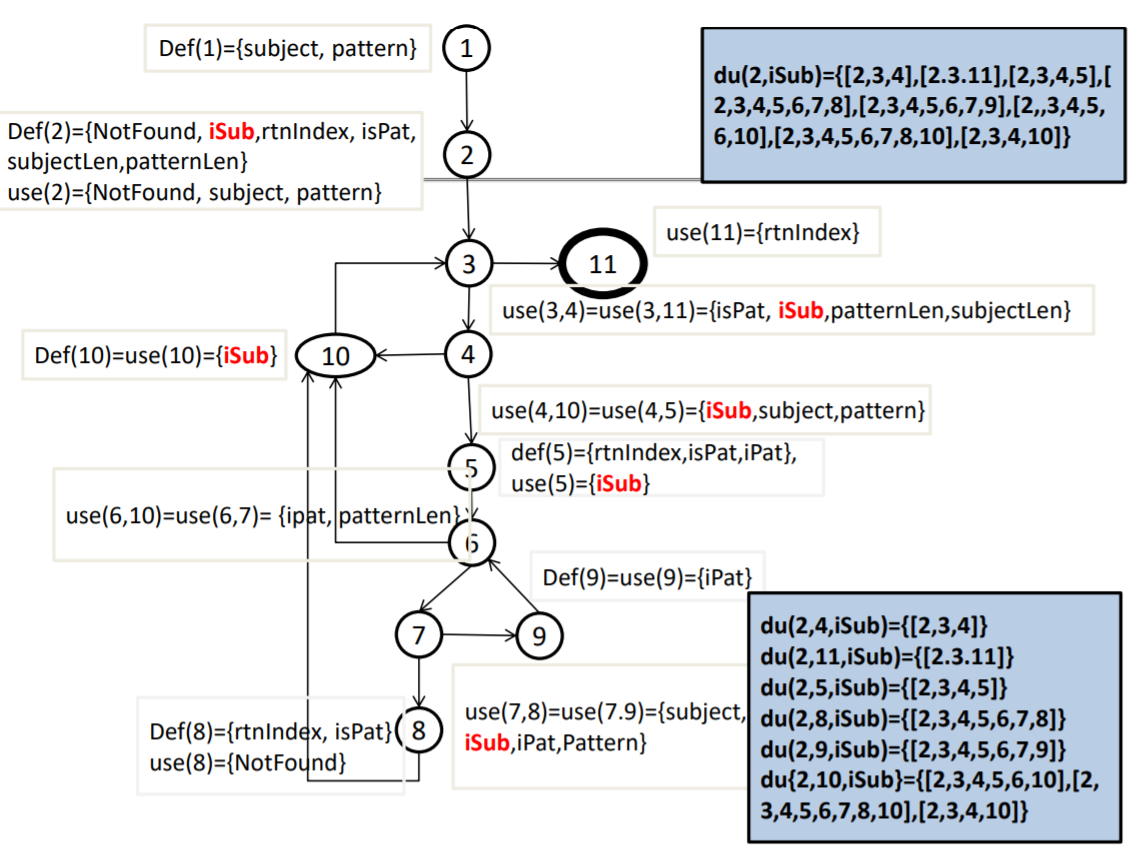
以10开头的,注意从10到10也是一个路径

第四步
选出全定义覆盖
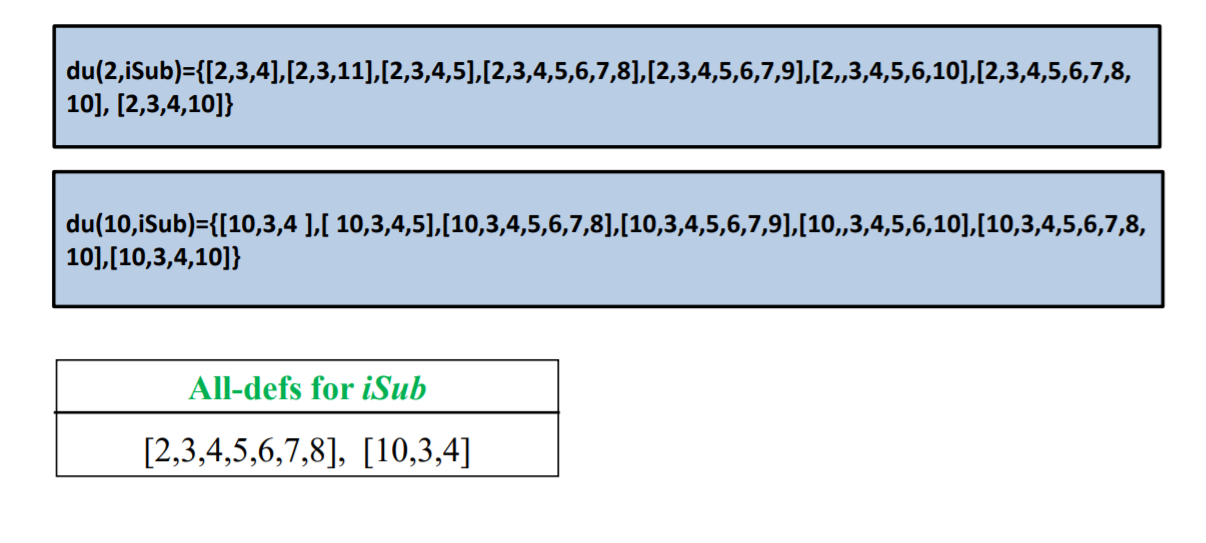
第五步
选出全使用覆盖路径
注意绿色的部分挑一个出来就像

第六步
选出全定义使用覆盖路径

8. 变异测试
基本概念
企业界的理解就是做出来就行
学理届一定要系统的用科学的方法和态度把它做出来
变异测试是揭错能力最强的方法,在代码当中故意植入一些缺陷,但是在工程界不被广泛应用
他开始是用来评估测试揭错能力的标准,后来才演变成了测试生成方法
变异算子:
缺陷,用于引入错误的方法
对被测代码做语法上的改变,这种改变的途径就是变异算子,一般是一个集合,每个变异算子代表了一类缺陷
每用一个变异算子,就生成一个变异体mutant,一次只改变一个地方(可以是变量交换,可以是改变符号)
一阶变异:Only one change
高阶变异:More than one changes

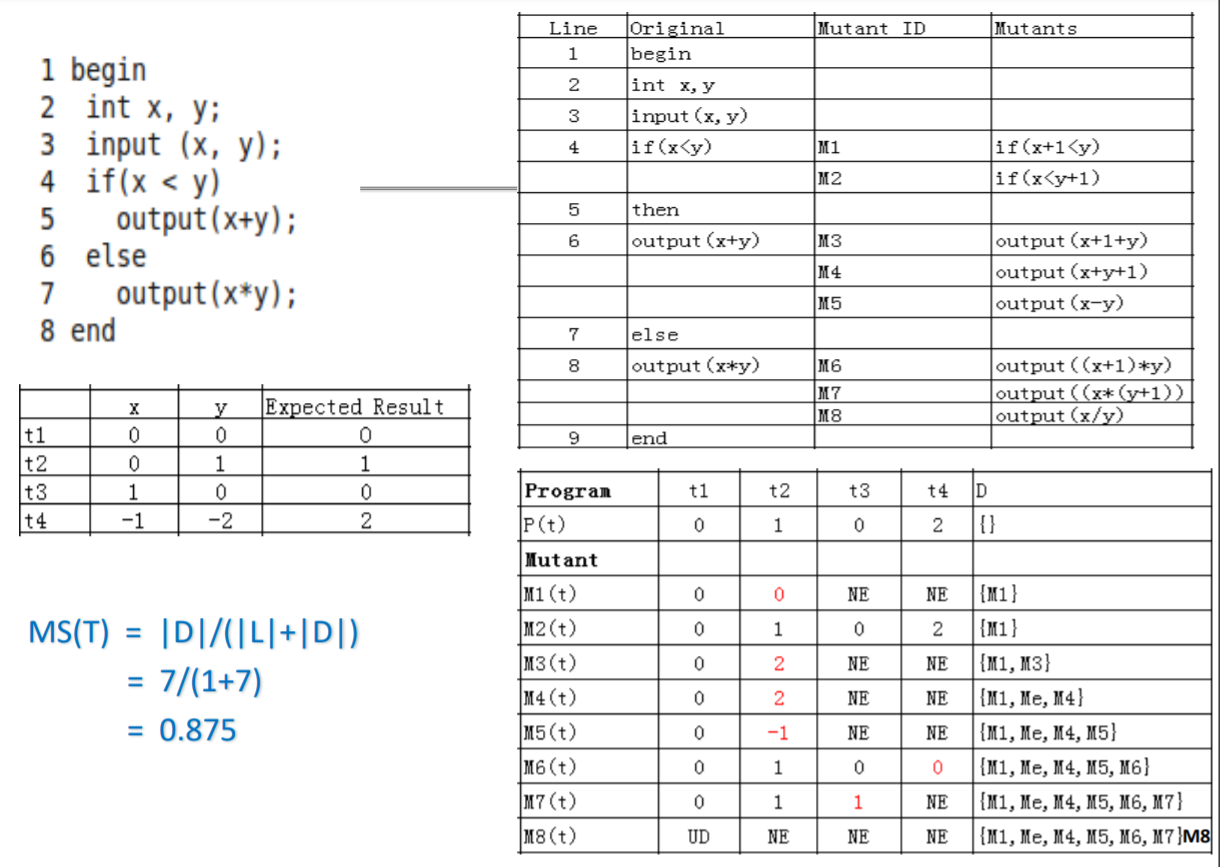
变异得分:
客观的数量指标
计算方法:被杀死的变异体 / (被杀死的变异体+存活的变异体)
分母剔除了等价变异体,就是运行结果跟以前完全一样的
NE表示只要前面有一个不一样,后面就不用算了
基于变异的测试生成
rip模型
可达性:测试导致错误语句被到达(在变异中——变异语句)
感染:测试导致错误的语句导致错误的状态
传播:不正确的状态传播到不正确的输出
RIP 模型导致突变覆盖的两种变体(强杀和弱杀)
Mutation Coverage (MC变异覆盖) :杀死所有的变异体,运行出来结果全都不一样,要满足rip模型
基于强变异覆盖
强杀:生成用例是通过输出结果来判断变异体是不是被杀死,有可观测的结果,要求非常高

基于弱变异覆盖
弱杀:只用满足可达性和感染性就行了, 不需要满足传播性了,条件放宽了

等价变异体
也可以通过约束求解表达式来分析
源代码的等价,然而前面的语句是“minVal = A” 替换,我们得到:“(B < A) != (B < A)”,因此没有输入可以杀死这个突变体

exercise
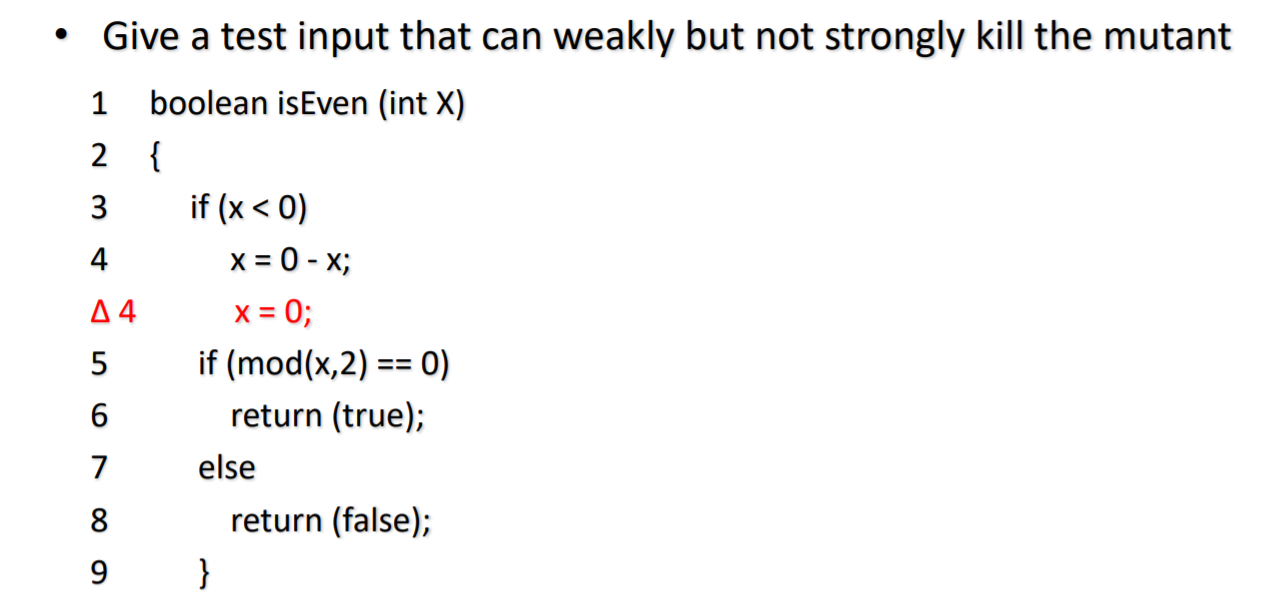

变异算子设计
程序每一句话都可以构造出一个变异算子,问题是构造这个变异算子有没有价值
如果专门为杀死由一组变异算子 O = {o1, o2, …} 创建的突变体而创建的测试也以非常高的概率杀死由所有剩余变异算子创建的突变体,则 O 定义了一组有效的变异算子
插入一元运算符和修改一元和二元运算符都有效
等价变异体的判定问题
三、代码接口测试
1. 概述
通过单元测试的代码单元,逐渐聚集在一起,集成测试
方法和方法之间调用,类与类之间的交互,只要设计到交互,几乎都是集成测试
单元测试的主要对象是代码,集成测试的主要对象是接口
集成测试可以发现的缺陷:方法调用不正确、参数不对
集成策略:怎样把通过单元测试的代码单元组装成一个软件系统,分层集成,自底向上,自顶向下。依据是代码之间的使用关系(可以通过类图找出使用关系),系统的体系结构
2. 集成测试技术

集成策略,重点放在web api的接口测试,但是集成测试不只有web测试
接口测试重要是因为前端设备很多,接口变成了前端共享的东西
测试工具比较好用的是postman
3. 集成测试用例生成
2.1 控制流
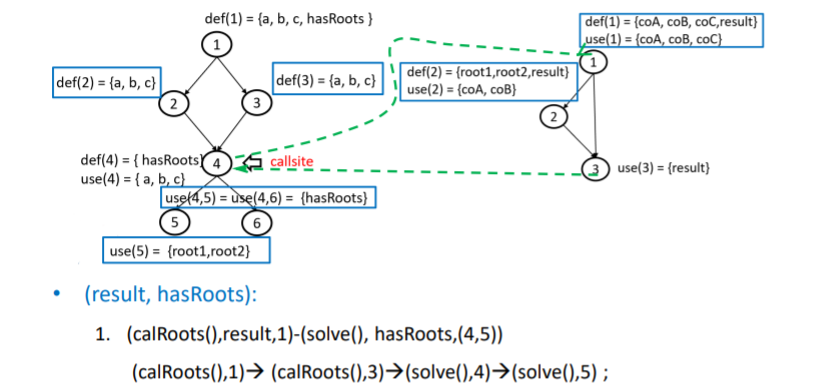
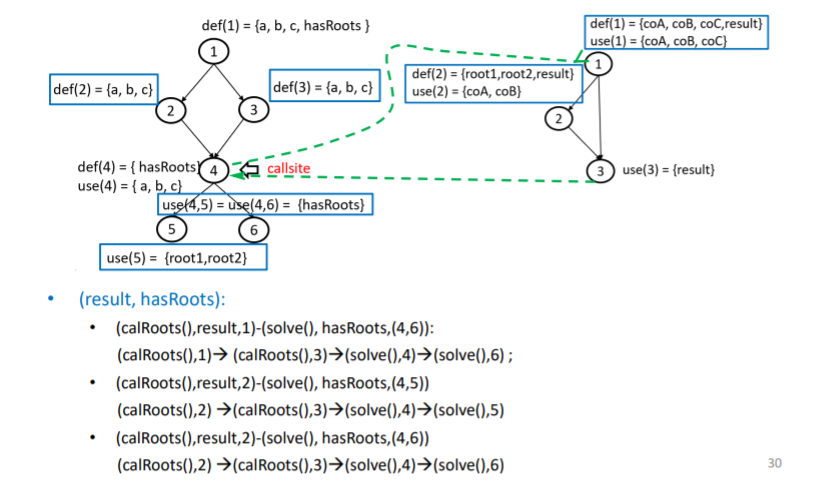
不再是以前的基路径,而是 **MM-path(Message-Method path消息方法路径)**:定义单元之间的控制转移的路径
下图是A执行到4调用了B方法,B执行到2调用了C方法
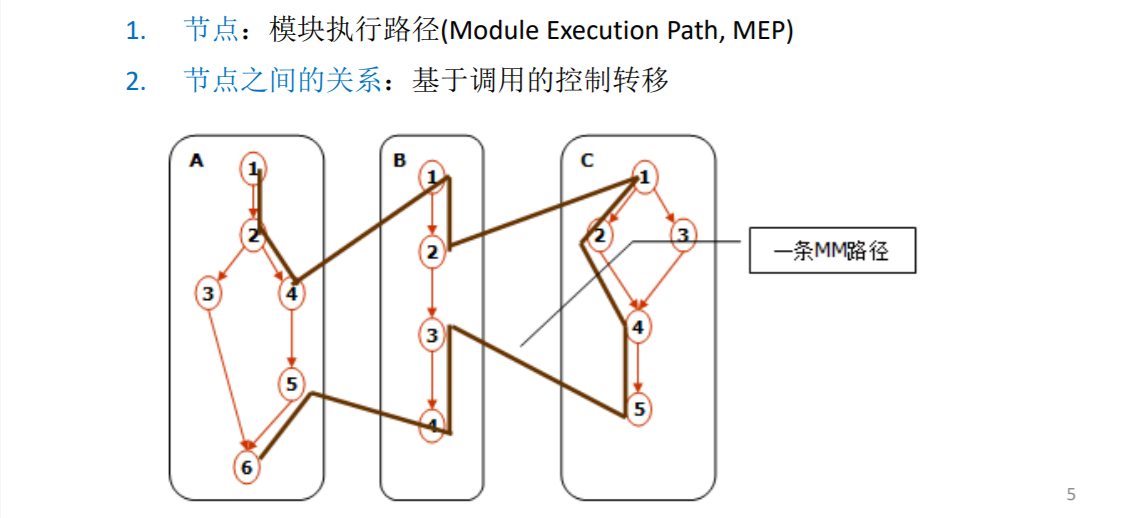
模块执行路径


找出模块执行路径:
1.找到每个单元的源节点和汇节点
2.排列组合,写出路径

红色路径的模块执行序列
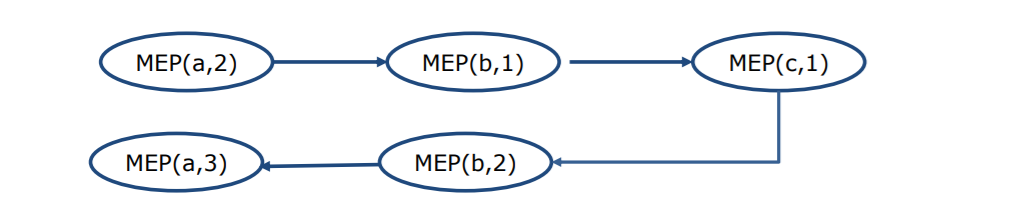
2.2 数据流
面向交互的数据流测试
源于编译原理,通过分析变量的定义和使用信息,对程序进行测试
揭示通过控制流测试难以发现的缺陷,发现继承缺陷或多态缺陷
相对于基于控制流的测试用例而言,包含了设计交互的变量的定义使用信息
对基本数据流的概念进行扩展
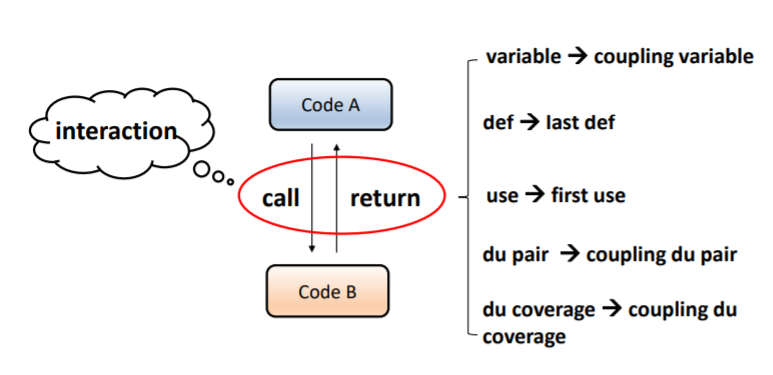
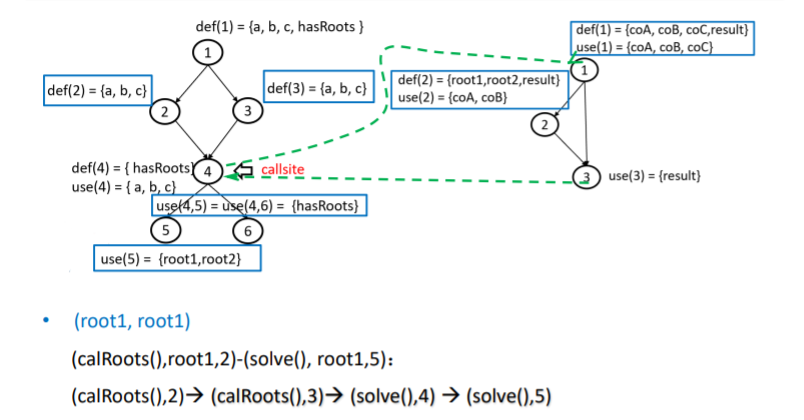
耦合变量:使用了相同的内存单元
实参和形参是最常见的耦合变量,也有其他的耦合变量比如非局部变量
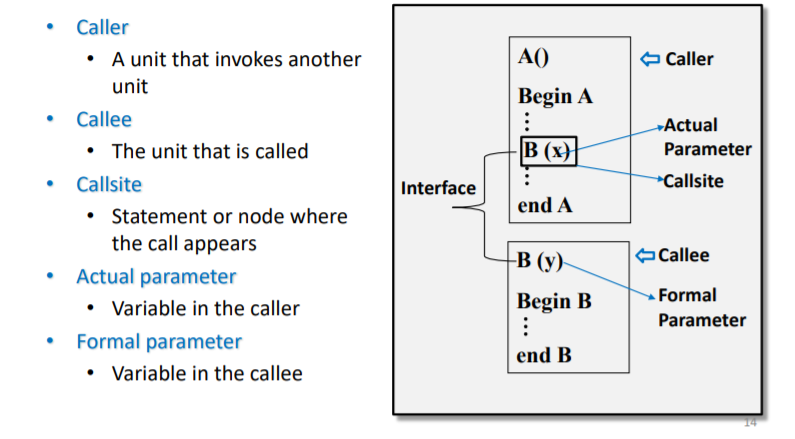
last-defination:实参在发生调用之前和从调用返回的定义
first-uses:发生调用之后和返回调用的定义
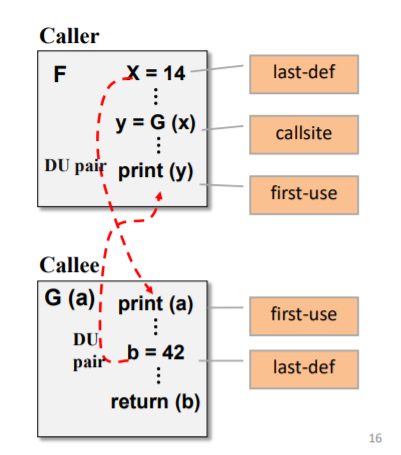
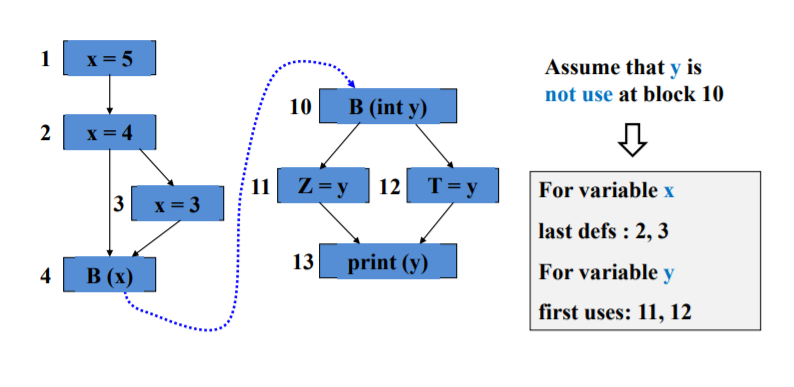
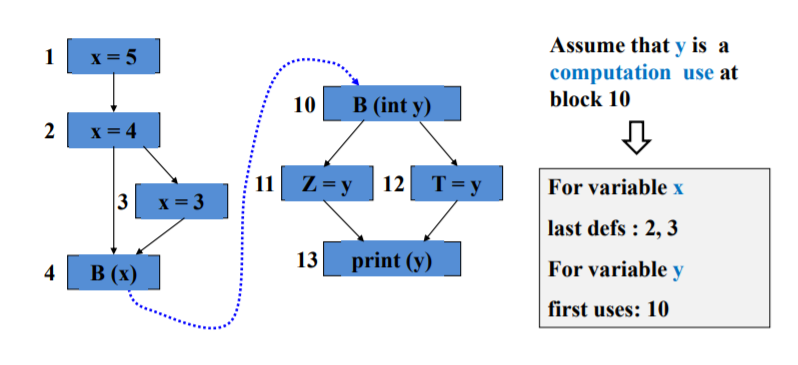
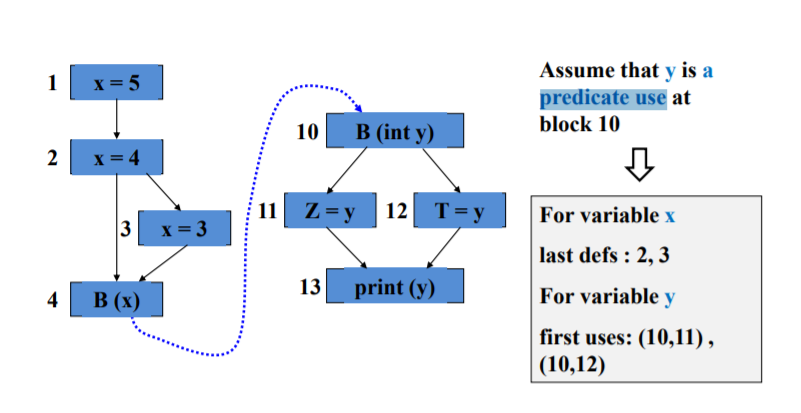
耦合定义使用对
耦合变量的最后定义和首次使用构成的
(A,x,Ii)-(B,y,Ij)

分别画出两个函数的数据流图,找到调用和返回的地方
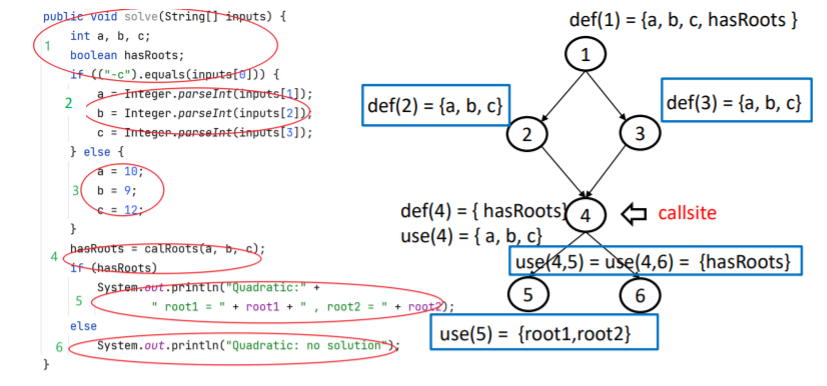
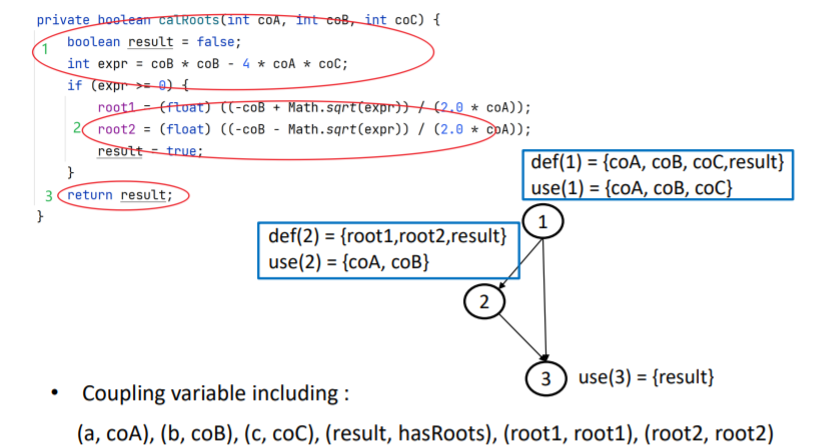
合起来看就找到了耦合定义使用对
注意调用和返回的方向是相反的啊!!
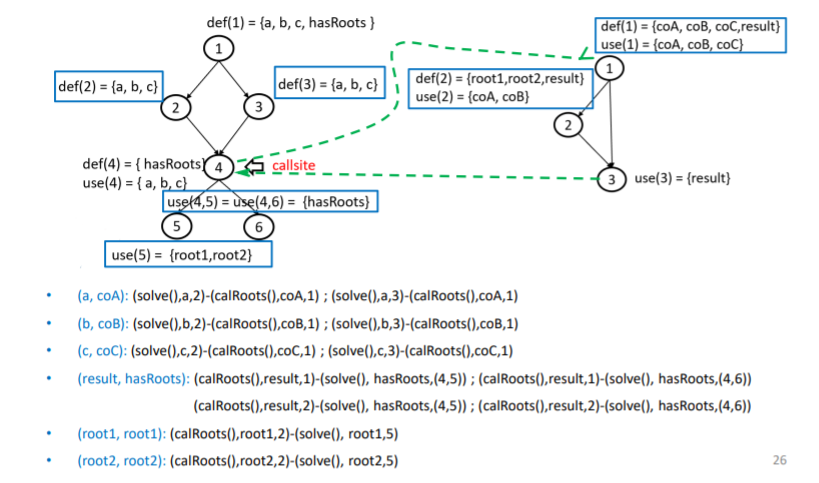
耦合的定义使用路径
全耦合定义覆盖:every last def to at least one first use
全耦合使用覆盖: every last def to every first use
全耦合定义使用覆盖:every simple path from every last def to every first use
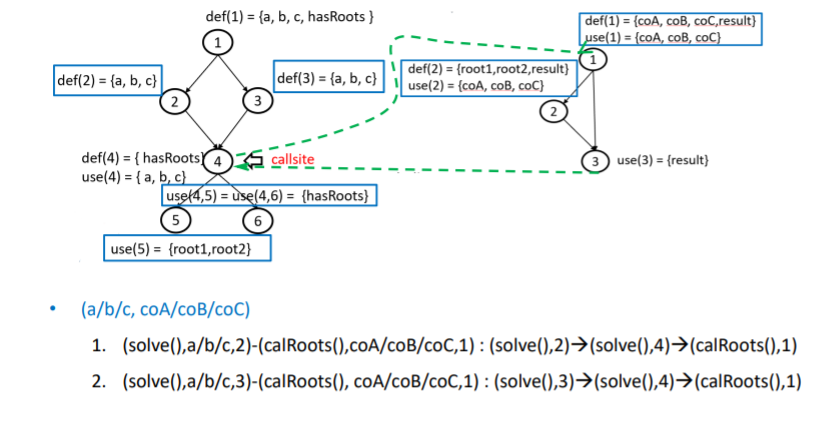

2.3 变异测试
怎么把概念进行扩展,进行交互测试
模拟集成缺陷,作为变异算子
Five Integration Mutation Operators





四、系统测试

1. 系统测试技术
测试级别最高的一种测试活动,是将已经集成好的软件系统,作为整个基于计算机系统的一个元素,与计算机硬件、外设、某些支持软件、数据和人员等其它系统元素结合在一起, 在实际运行(使用)环境下,对计算机系统进行一系列的组装测试和确认测试
系统测试的对象不仅包括软件,还包括系统软件所依赖的硬件、外部设备和各类接口,其目的在于通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方以及系统各个部分是否可以协调工作。
系统测试分为两大类别:功能测试和非功能测试
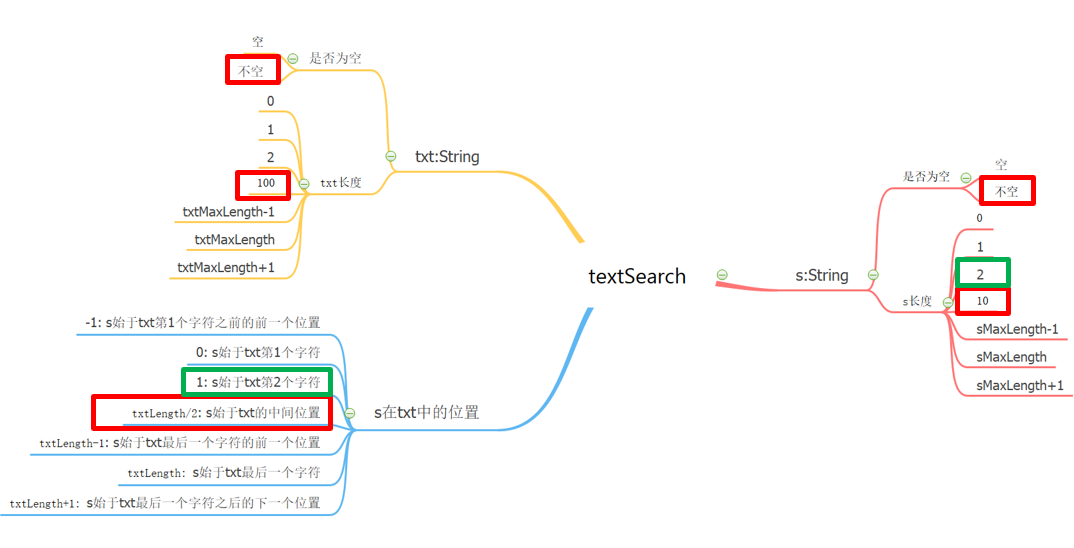
2. 输入域划分

基于等价类思想
问题:无法穷举输入空间
为了有效约简测试工作量,会对输入域进行划分,每个输入域取一个值的方法
2.1 什么是输入域
待测对象所有可能输入的集合,输入域通常具备无限性,所有输入变量的笛卡尔积的集合

一般采用以预期结果相等的输入作为一个划分块
划分的结果满足:完备性、独特性
2.2 输入域建模
识别可能影响待测对象功能的各个输入参数,并对其进行划分的过程:
- 识别待测因素:形参、输出
- 识别待测特征:待测因素的进一步细化
- 对每个待测特征进行输入域划分

一些策略:
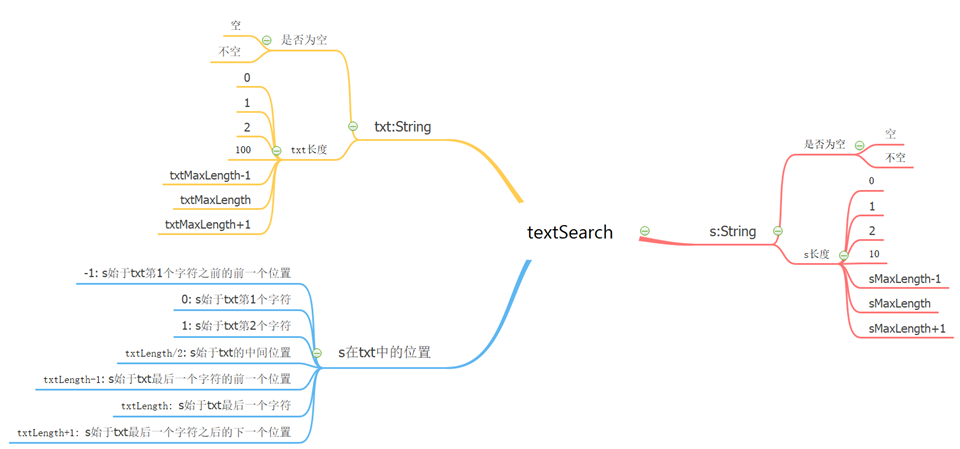
- 边界值:若输入域是数值区间 (a,b):需要包含介于a, b之间的正常情况,a,b,比a稍微小一点,比a稍微大一点,比b稍微小一点,比b稍微大一点
- 包括有效值、无效值和特殊值
举例:


对待测特征的输入域进行划分
2.3 输入域组合策略
组合待测试特征
全组合值覆盖 ACoC
划分块的枚举测试,要求测试输入必须覆盖各个待测特征划分结果的笛卡尔积
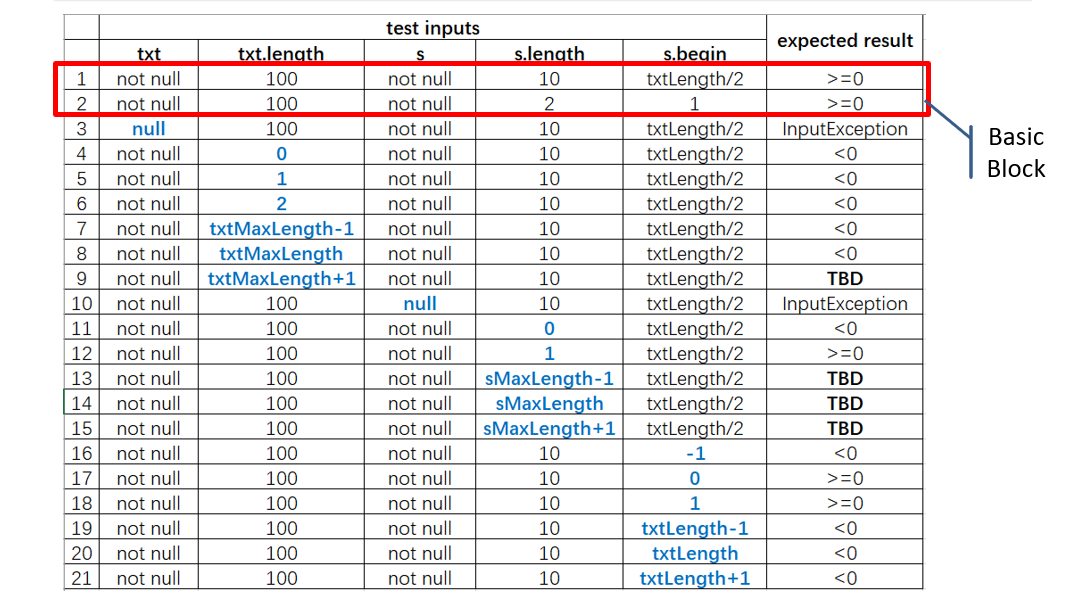
上面题:2 * 7 * 7 * 2 * 7 = 1372
前21个测试用例
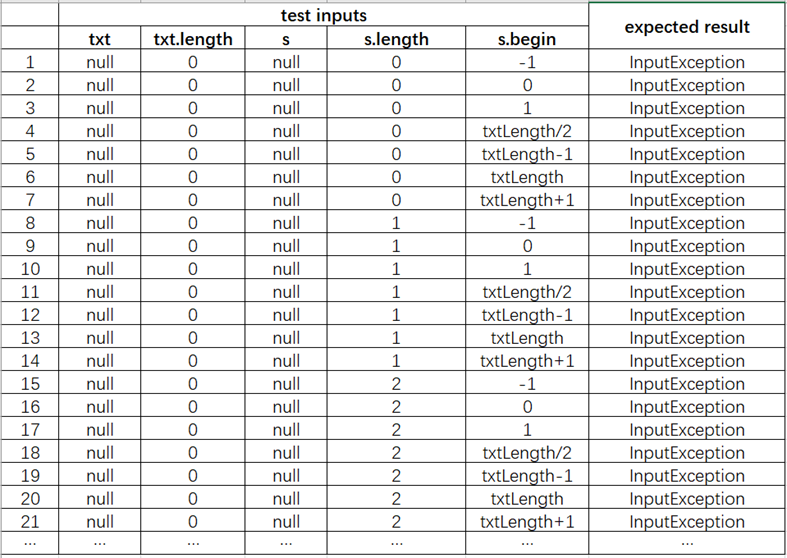
分析不可行产生的原因,如果是因为待测因素/待测特征识别不合适而产生的,需要对输入域的模型进行调整。通过替代产生矛盾的划分块,得到可行的组合策略,是我们常用的方法
单值覆盖 ECC
覆盖度最低,每个待测特征的每个划分块只被输入一次,并没有考虑要测试的语义含义
上一题:Max{2,7,7,2,7} = 7
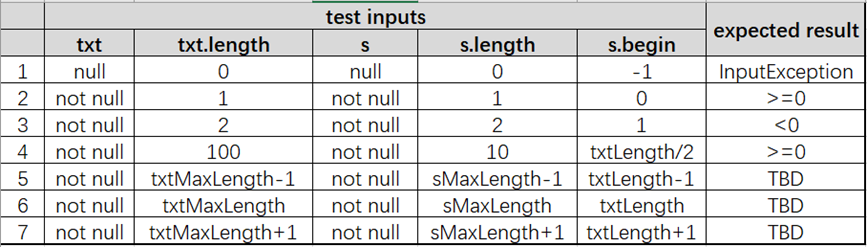
TBD:to be defined 需求不明确,没有定义最大长度,也没有说明超出最大长度,系统如何响应,可以认为是一个缺陷,需求缺陷
全对偶 PWC
P=第一大*第二大 = 7 * 7
考虑两两不同待测特征输入域元素之间的关系入手,要求测试输入集合必须覆盖不同待测特征输入元素之间的对关系,是最简单的不同待测特征输入元素之间的关系的覆盖策略

满足全对偶覆盖的表格法:

全对偶覆盖计算题

全T值覆盖 TWC
是全对偶覆盖的一个天然扩展,要求测试输入集合必须覆盖不同待测特征输入元素之间的t值关系,t可以是任意整数
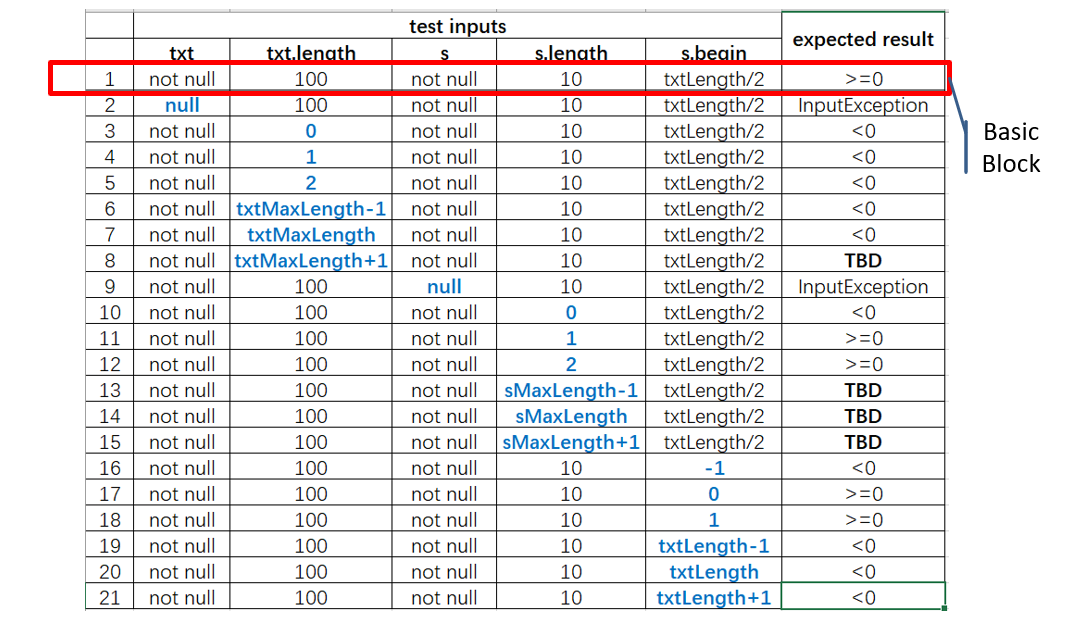
基本值覆盖 BCC
在实践中最常用的一种数据组合策略,基本值的含义是根据系统功能上下文,某个待测特征的所有输入域划分取值中,使用频率最高的取值
要求在给定基本值的前提下,测试用例需要覆盖以下两种情况:
- 需要包含一个所有待测特征取基本值的测试用例
- 其余测试用例需要满足针对每一个被测特征,依次使用其非基本值取代基本值,其余被测特征仍取基本值,直到所有待测特征的所有非基本值都被覆盖位置
多基本值覆盖 MBC
某个或某些待测特征有多个基本值
2. W method
测试用例设计自动化是软件测试技术发展的必然方向
找到表示需求的形式,是可以被计算机识别的——自动机
w method
基于有限状态机的测试生成算法,从揭示缺陷的立场出发设计的测试生成算法,以免由于到目前为止,我们讲解的都是基于覆盖的测试用例生成,给大家造成误解
以有限状态机作为计算测试用例的输入,可以获得运行在被测系统上的测试输入序列,测试时,使用这些计算出来的测试输入序列,驱动被测系统执行,运行结果符合有限状态机输出定义的,测试通过
有限状态机FSM:
- 系统功能需求
- 可视化系统设计方案
缺陷模式
- 输出结果不对
- 转移缺陷,控制逻辑不正确
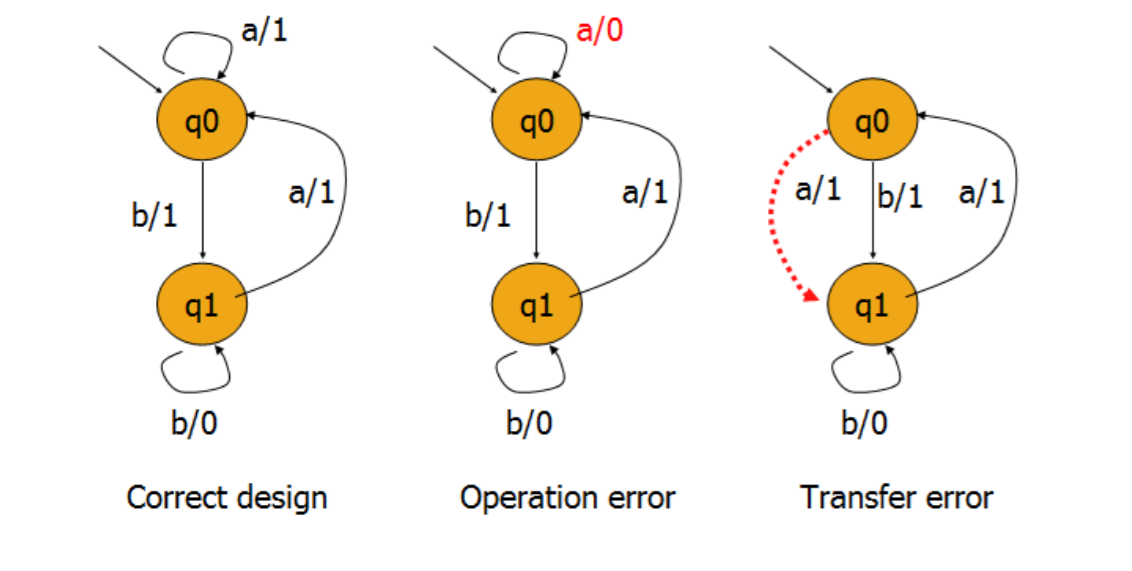
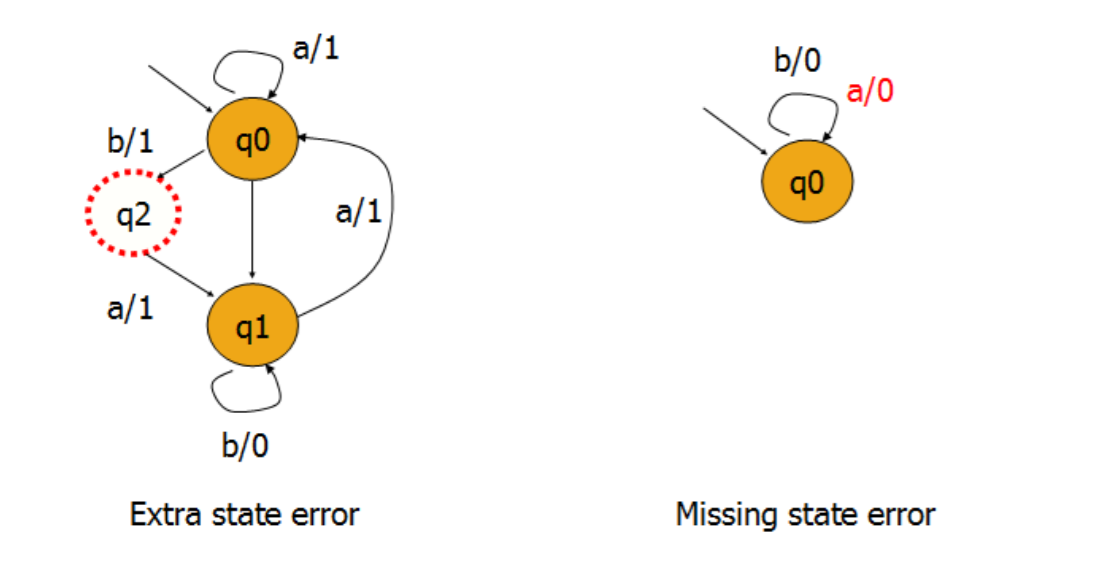
- 额外状态
- 状态缺失
算法核心
通过计算能够区分有限状态机中任意一对状态的特征字符串集合W,达到识别上述四类缺陷模式的目标
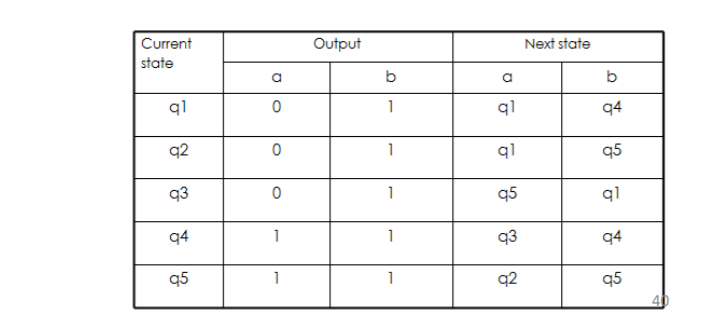
有限状态机的数学描述

举个例子
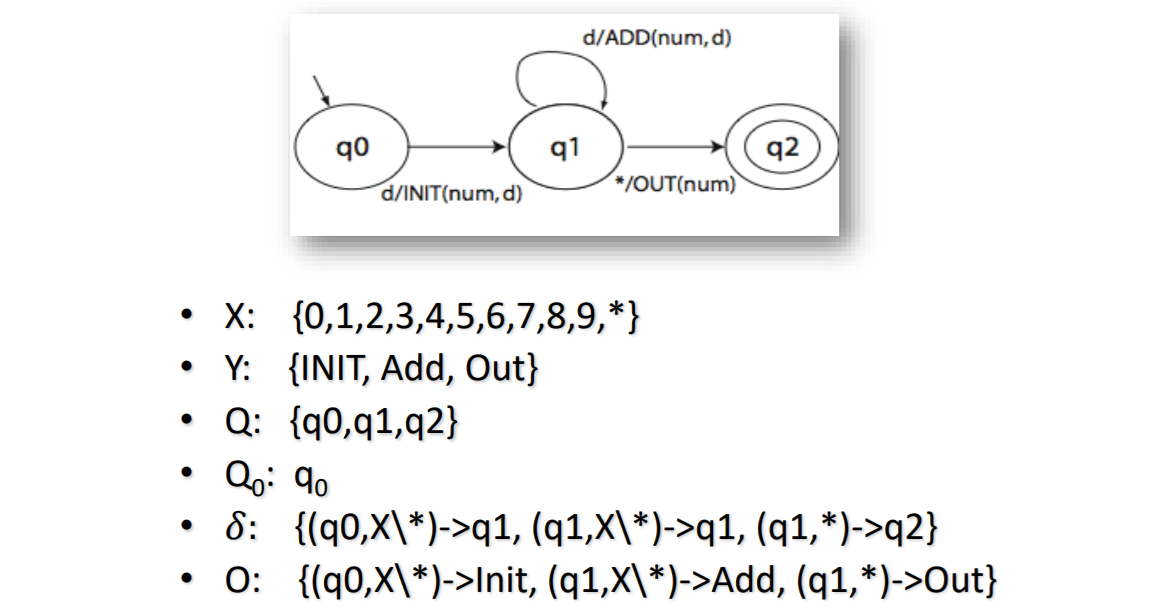
需要满足的条件:
- 完备性、最小性、连通性、 确定性
- 只有一个确定的初始状态
- 可以通过重置复位到初始状态
- 待测代码和状态机具有的相同输入字母表
算法描述

- 输入是设计模型的有限状态机M,输出是运行在代码上的测试用例集合,该代码是依据M编写实现的。w一般取设计模型有限状态机的状态数
- 利用k等价表计算特征输入集合W(main)
- 构造M的测试树,基于测试树计算迁移测试集合
- 。。。
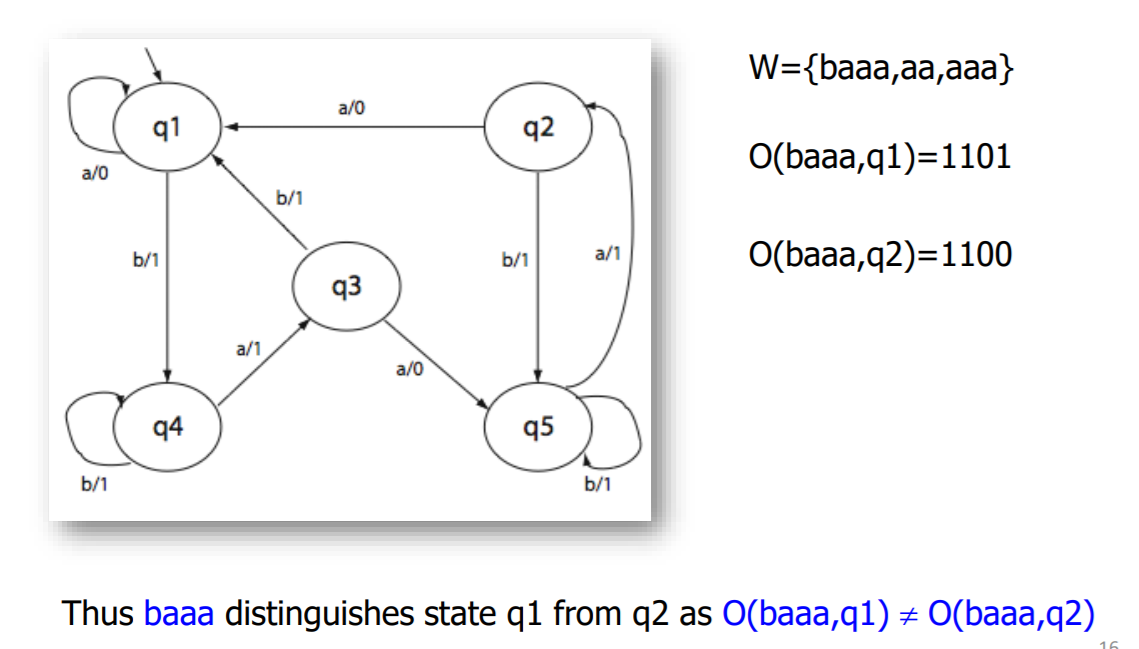
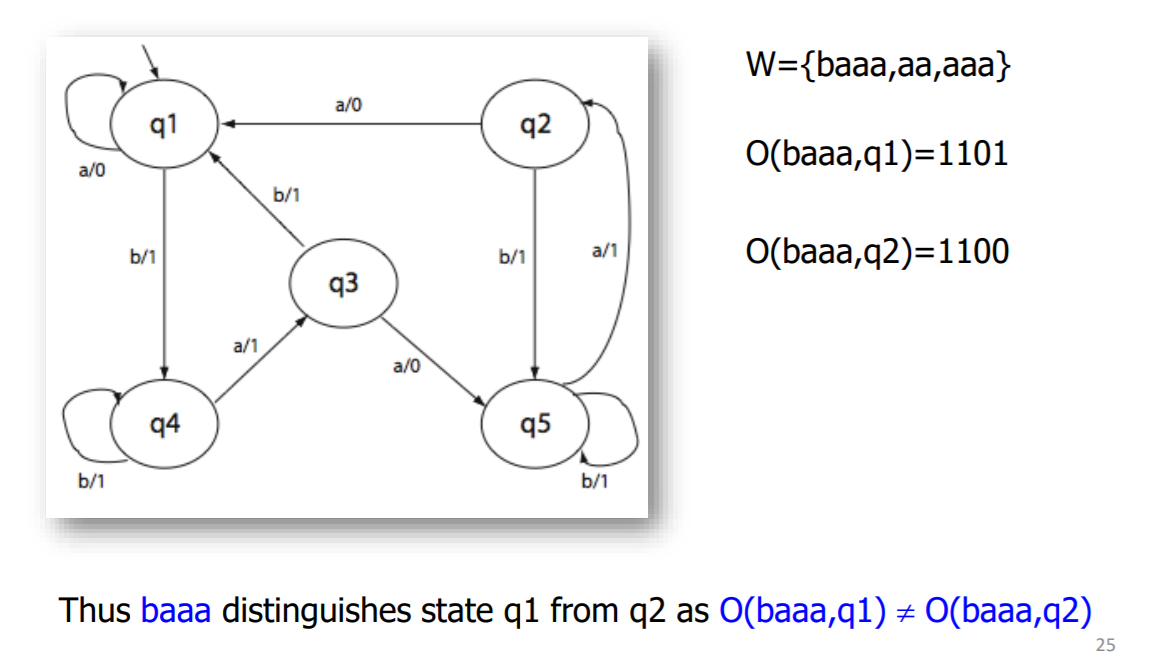
等价划分表
对于q1到q5形成的十对状态的任意一对,在W中总能找到一对输入序列,使得他们输出不同
比如下面输入baaa,q1和q2输出不同,表示可以从观察端区分q1 q2
How to construct a k-equivalence partition?
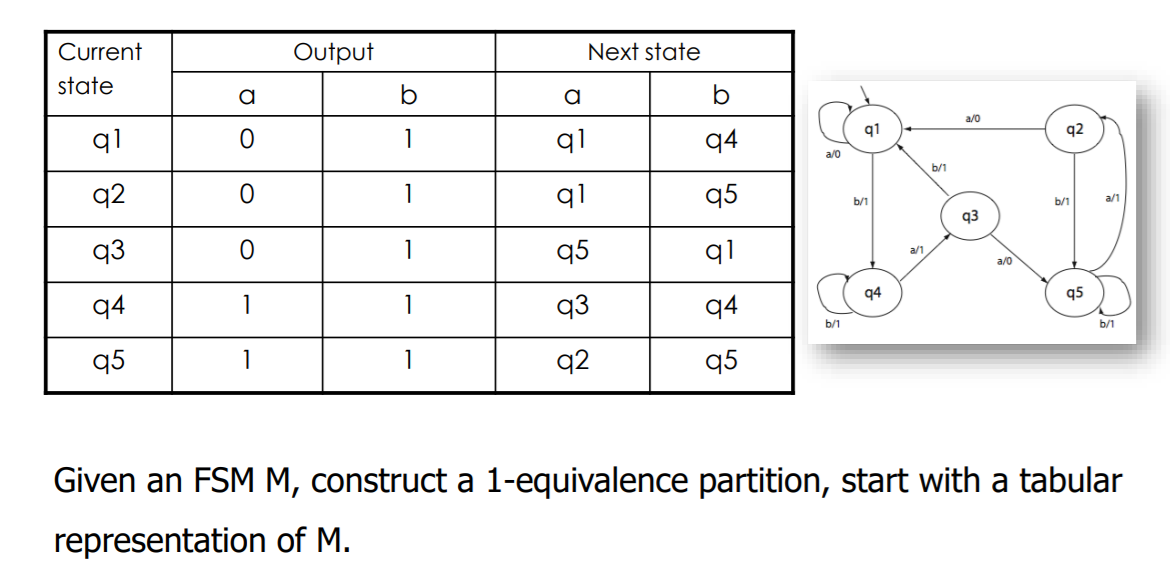
1等价划分
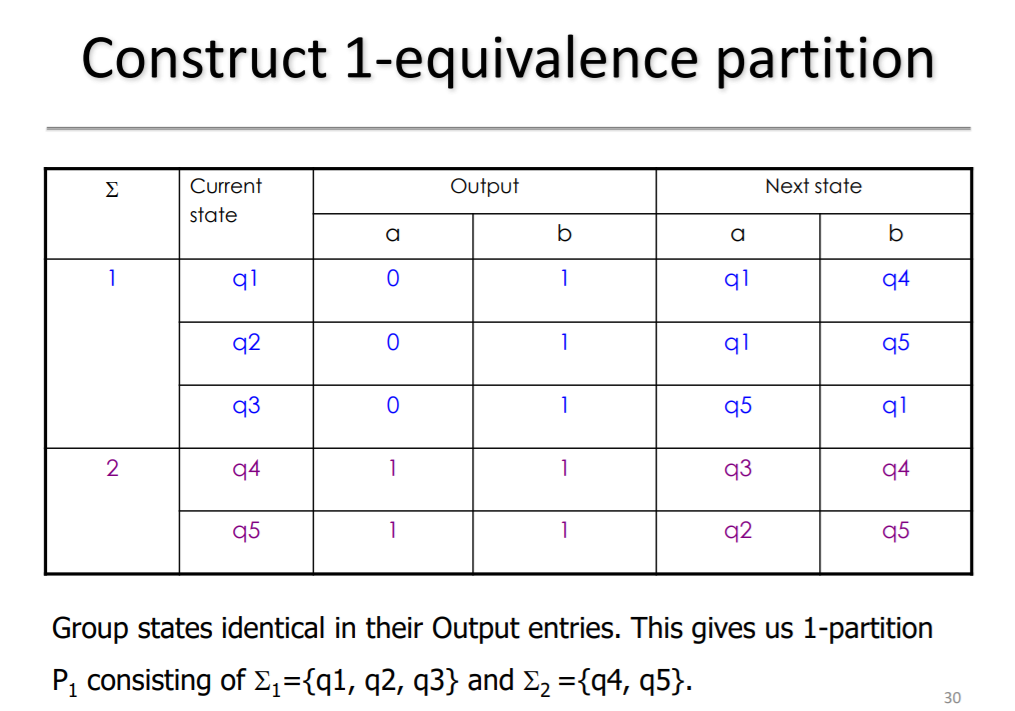
在计算2等价划分时,先重写1等价划分表,去掉output这一栏,更新next state两栏,方法是在后面加后缀,后缀就是前面1等价划分的组别号
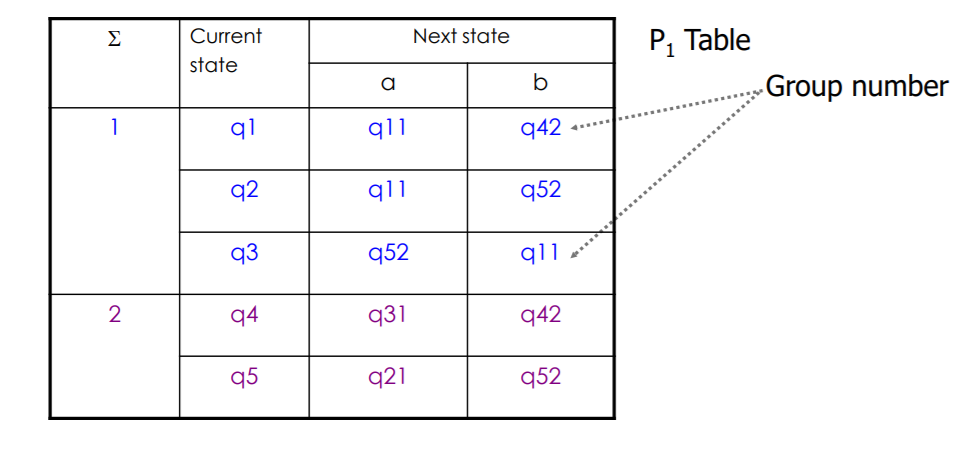
2等价划分,后继状态值参见后缀值
记住划分之后要更新后缀!把后缀为2的更新为3
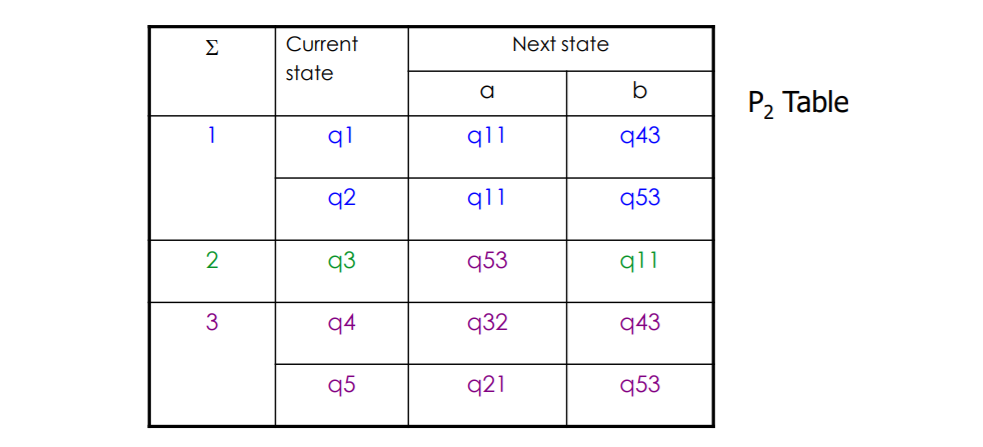
3等价划分,更新后缀
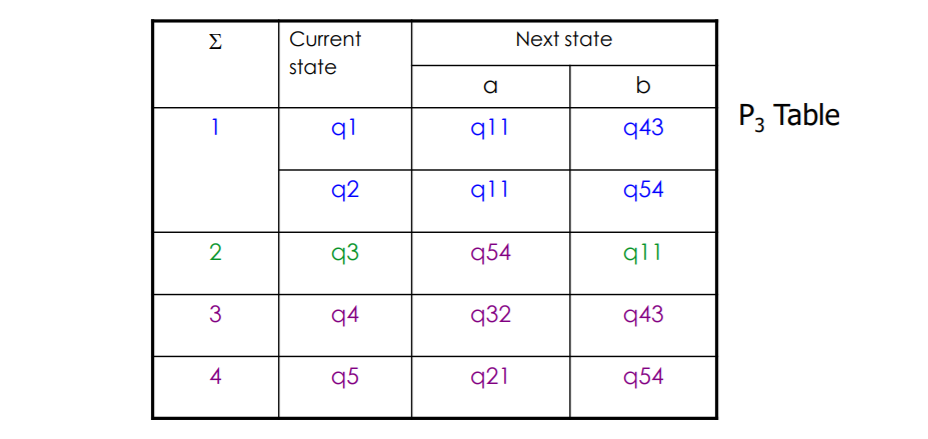
4等价划分,状态集合Q中的所有状态都归属于不同的等价集合,此时计算结束
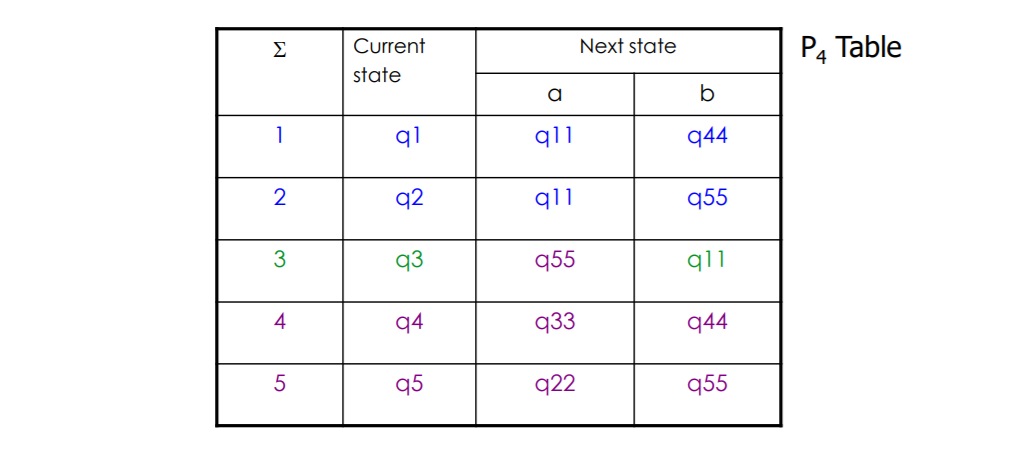
计算特征输入
以q1和q2举例
令他们区分开的输入就是b,b就是计算出来的q1 q2特征输入序列的第一个输入
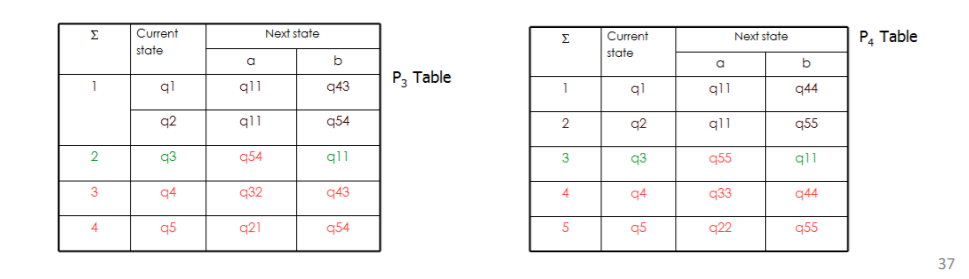
q1 输入 b 跳到了 q4,q2 输入 b 跳到了 q5(观察第一个前缀)因此下一轮分析 q4 q5分开的时候
令他们两个区分开的输入a b都行,这里取a,第二个输入就是a
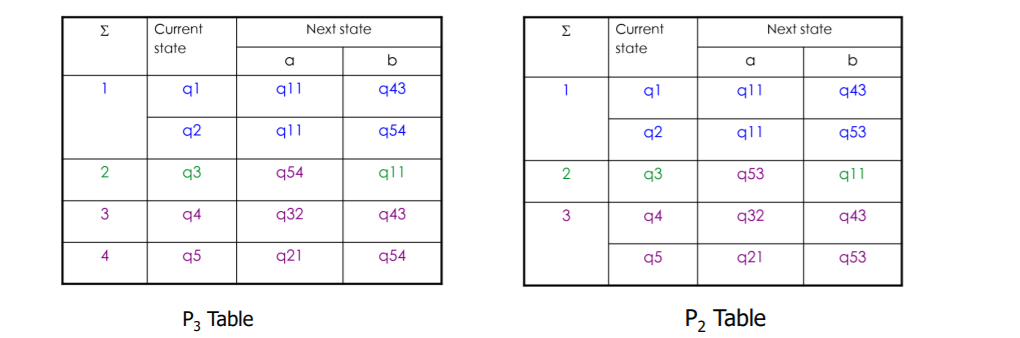
q4 输入 a 跳到了 q3,q5 输入 a 跳到了 q2,因此下一轮分析 q2 q3分开的时候
令他们两个区分开的输入a b都行,这里还是取a,第三个输入就是a
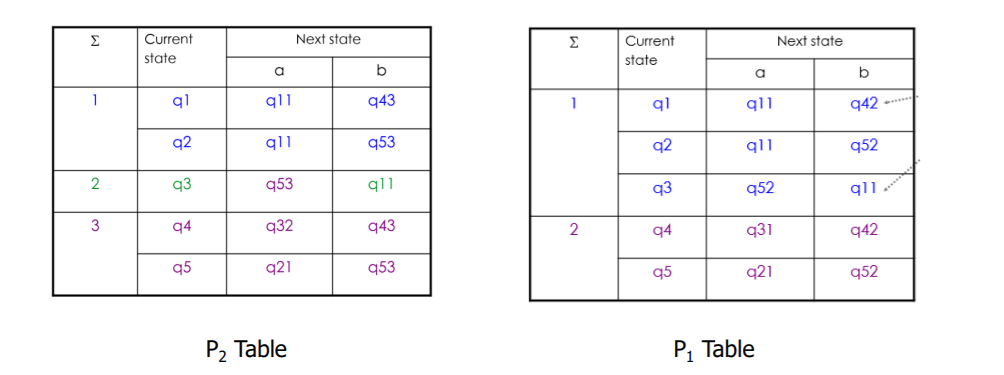
下一轮分析q1 q5,等价划分表为原始表和1等价划分表
令他们两个区分开的输入是a,第四个输入是a
==因此 (q1,q2) 特征字符串就是baaa==
按照上面的方法算出另外九对,然后去重之后就是w
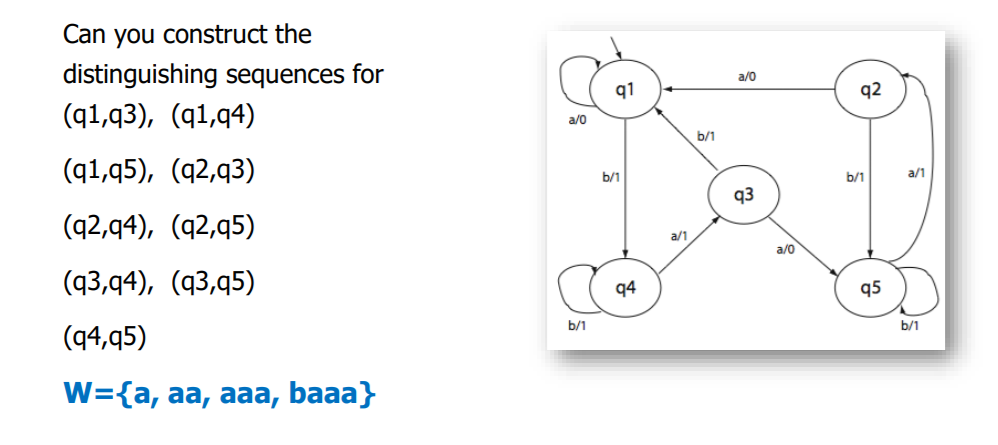
构造M测试树
以初始状态为根,为了计算可以保证测试输入具有可达性和感染性的迁移覆盖集合P
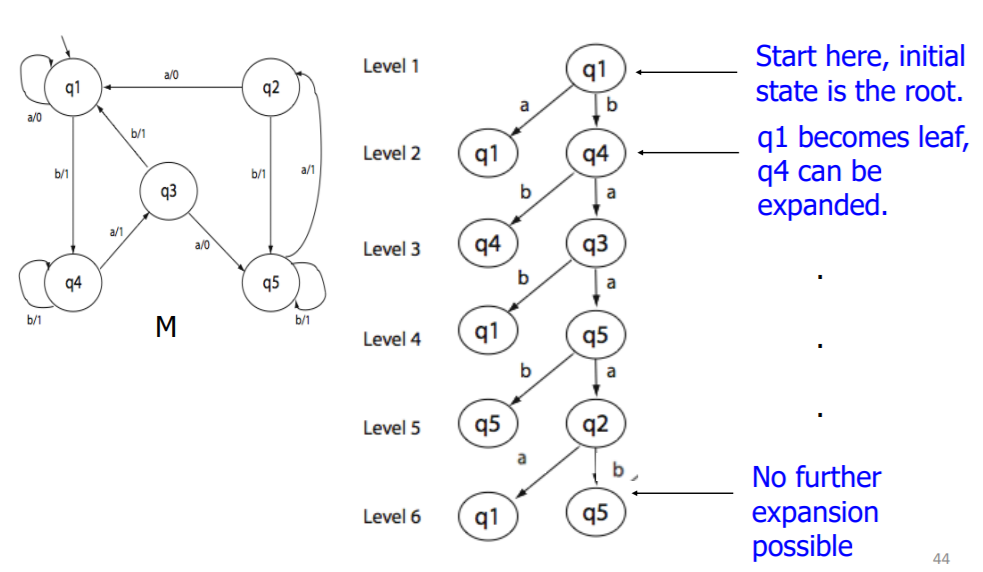
计算迁移覆盖集合P
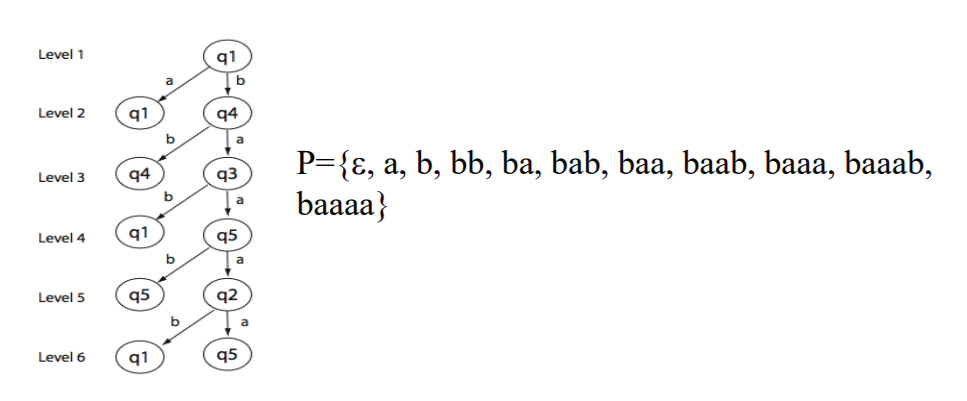
输入集合Z
该集合的目的是检测额外状态缺陷和缺失状态缺陷