第2章 关系模型介绍
caiyi 2021/5/11
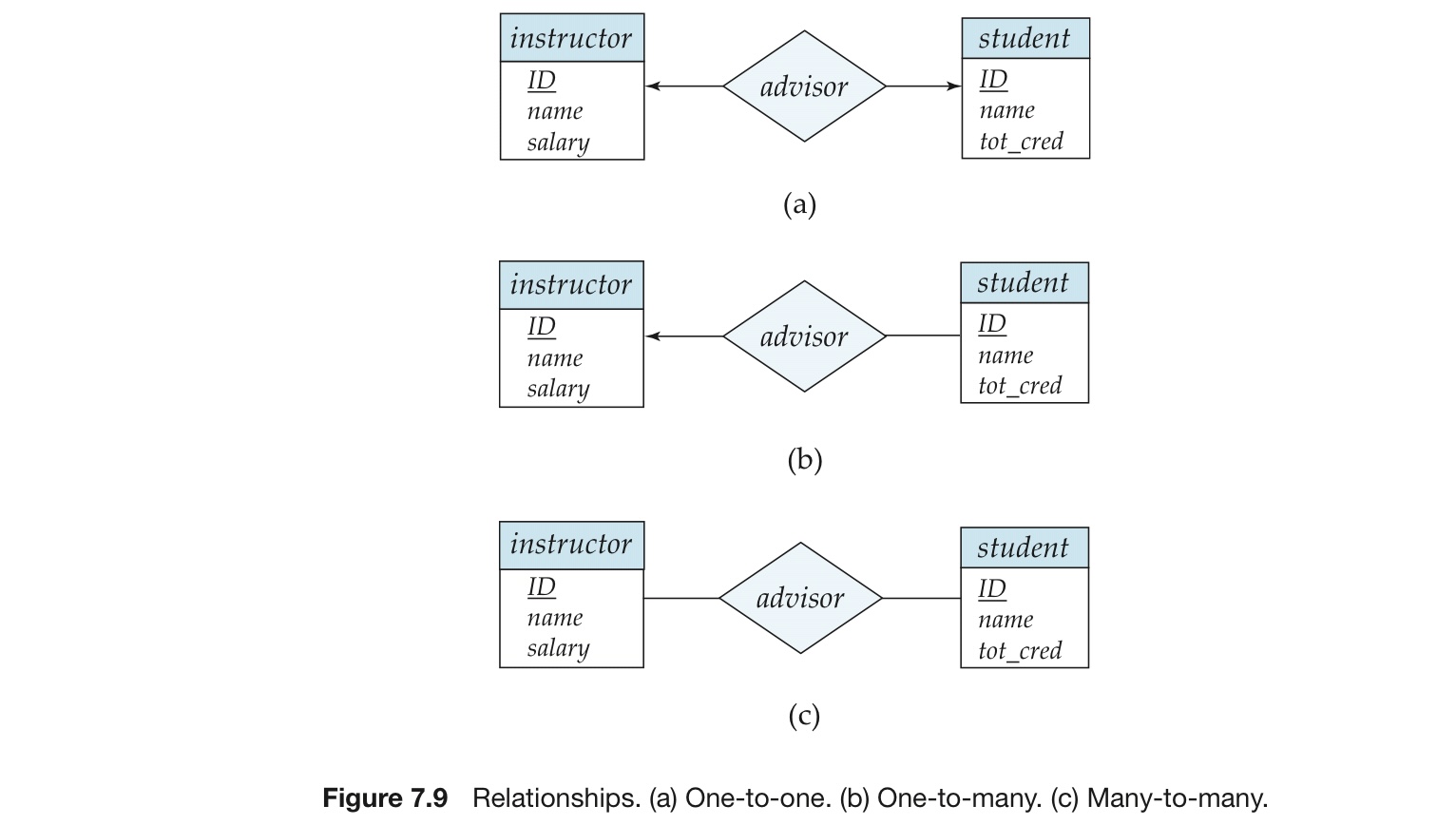
2.1 关系型数据库的结构
关系(relation):表
元组(tuple):行
属性(attribute):列
域(domin):对于关系的每个属性,都存在一个允许取值的集合
关系的所有属性的域都是原子的,被看作是不可再分的单元
关系模式(relation schema):对于关系结构的抽象描述,由属性序列和各属性对应域组成
关系实例(relation instance):一个关系的特定实例
2.2 码
一个关系中没有两个元组在所有属性值上都相等
超码(super key):一个或多个属性的集合,可以唯一标识一个元组
候选码(candidate key) :最小超码,不包括无关紧要的属性
主码(primary key):用来在一个关系中区分不同元组的候选码
外码(primay key):一个关系模式r1可能在它的属性中包括另一个关系模式r2的主码,r1称为外码依赖的参照关系,r2称为外码依赖的被参照关系
参照性关系(referential integrity constraint):要求在参照关系中任意元组在特定属性上的取值必然等于被参照关系中某个元素在特定属性上的取值
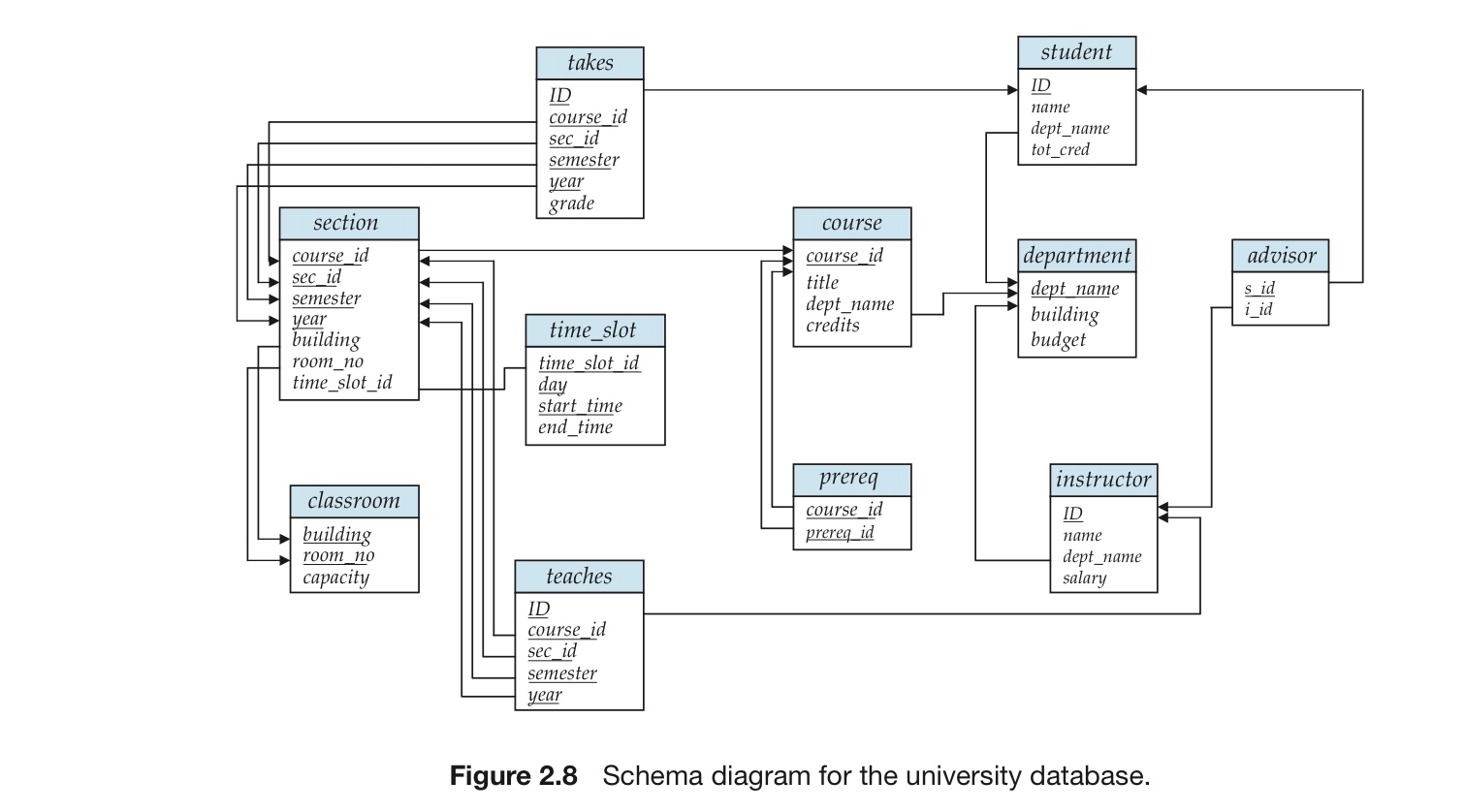
2.3 模式图
每个关系用矩形表示,关系名字显示在矩形上方,矩形内列出各种属性
主码属性用下划线标注,外码依赖用从参照关系的外码属性到被参照关系的主码属性之间的箭头来表示
2.4 关系查询语言
过程化语言:用户指导系统对数据库执行一系列操作以计算出结果,例如关系代数
非过程化语言:只需描述信息不用给出获取信息的具体方法,例如关系演算TRC、域关系演算DRC
2.5 关系运算
基本操作
选择(select) $\sigma$
查询满足给定条件的元组(从行的角度)

投影(project) $\Pi$
选出若干属性列组成新的关系(从列的角度)
投影之后会取消重复的行

并(union) $\cup$
先并再去重
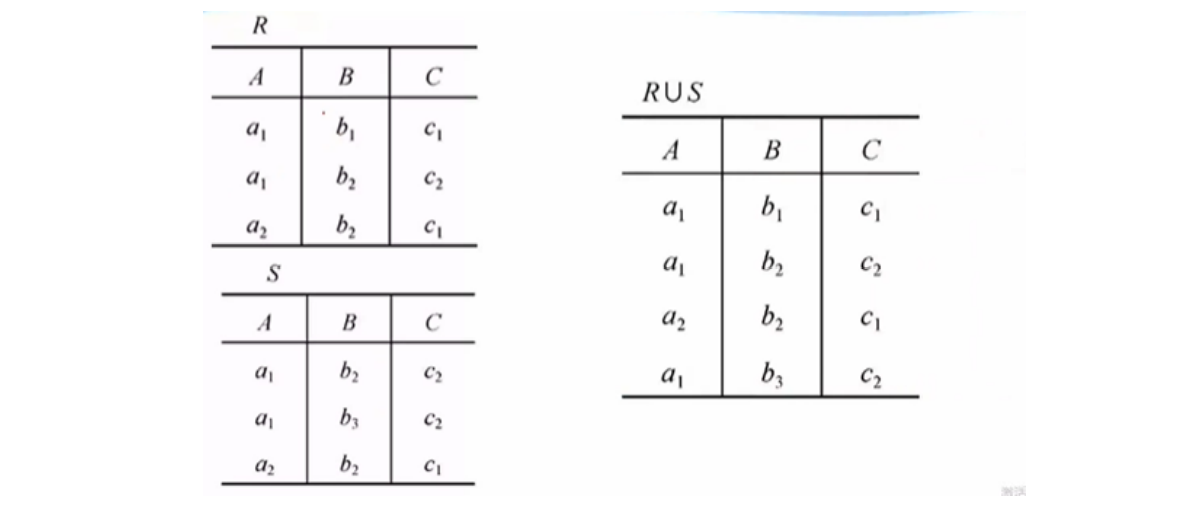
交(set intersection) $\cap$
两个表都有的元组

差(set difference) $-$
R有但S没有的关系元组

笛卡尔积(Cartesian product) $×$

自然连接(natural join) $\bowtie$
从两个关系的笛卡尔积中,基于两个关系模式中都出现的属性上的相等性进行选择,最后去掉重复的列

除(division) $÷$
保留R中满足S的,而且R中列要去掉S的列

改名(rename) $\rho$
$\rho _{x(A1,A2,…An)}(E)$
返回表达式E的结果,并赋给它名字x,同时将各属性更名为A1,A2,…An
例子:找出大学里的最高工资

赋值(assignment) $←$

对于关系代数查询而言,赋值必须是赋给一个临时关系变量,对永久关系的赋值形成了对数据库的修改。
注意:赋值运算不能增强关系代数的表达能力,但是可以使复杂查询的表达变得简单
扩展的关系运算
广义投影 (Generalized Projection)

聚集 (Aggregate Functions) $\mathcal{G}$

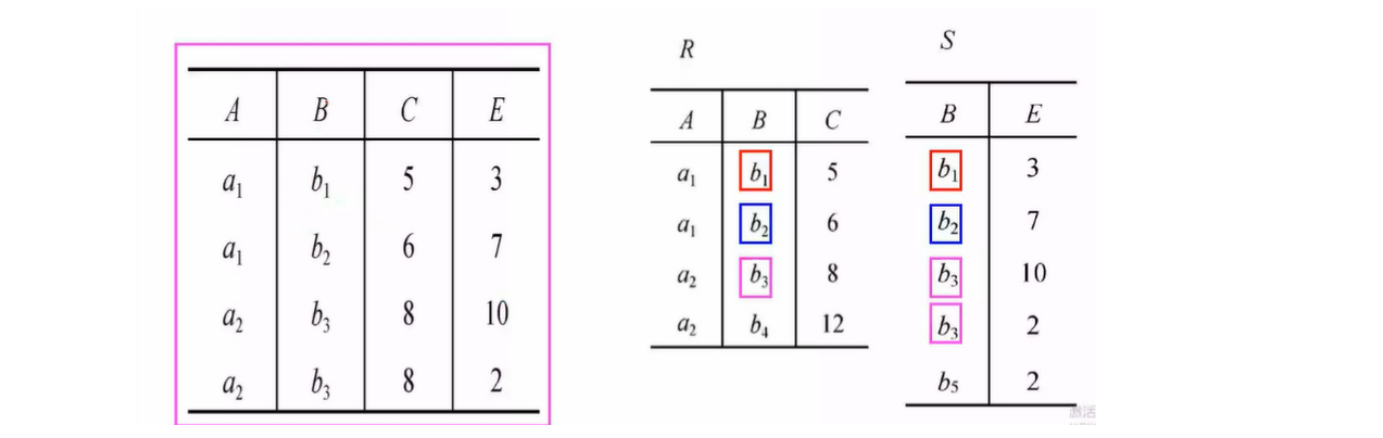
内连接/外连接
内连接(Inner Join):两个关系做自然连接时,连接的结果时满足条件的元组保留下来,不满足条件的元组被舍弃了
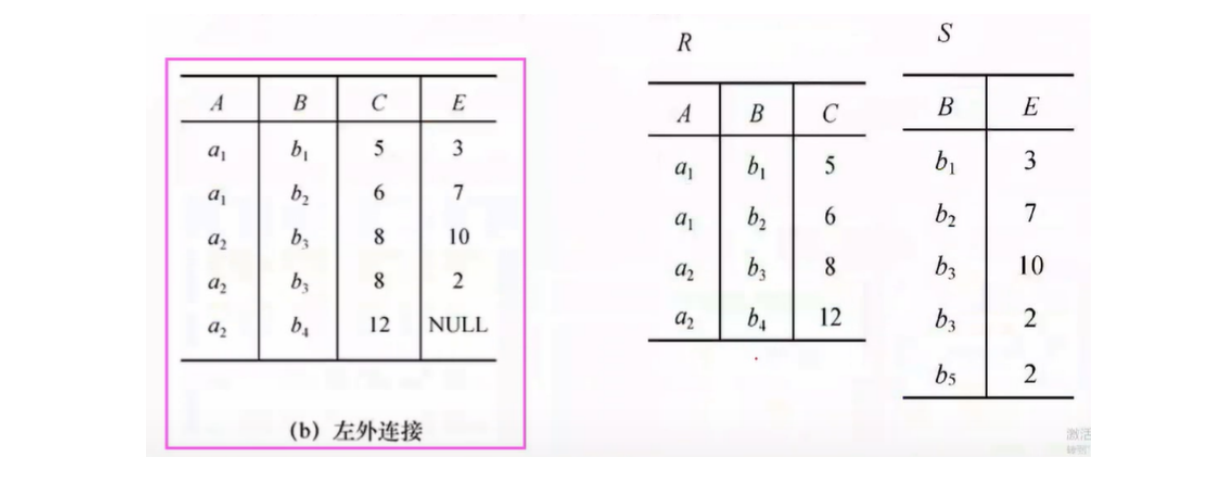
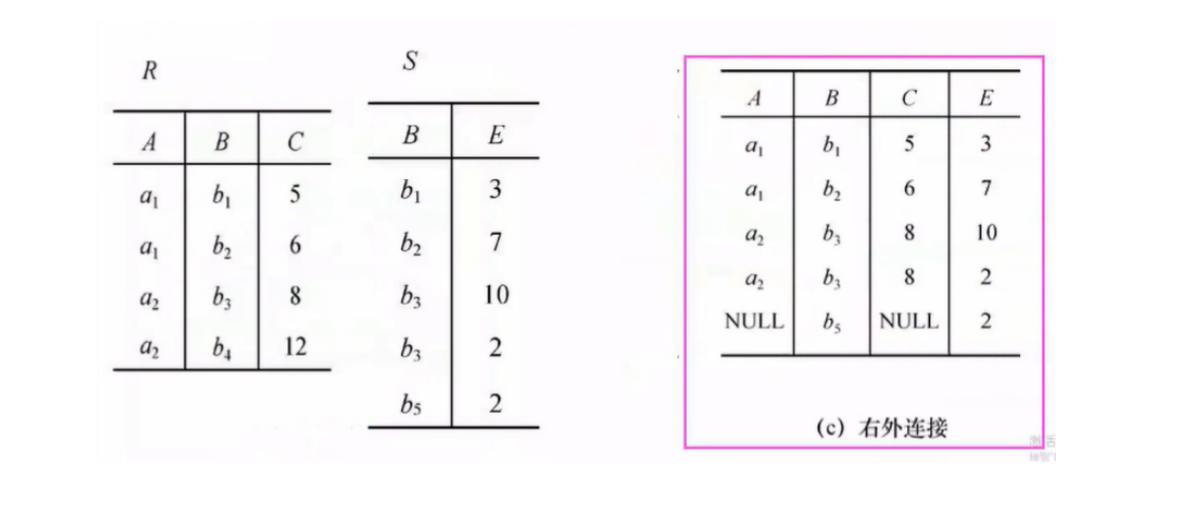
外连接(Outer Join):如果把舍弃的元组也保留再结果关系中,而在其他属性上填null,叫做外连接
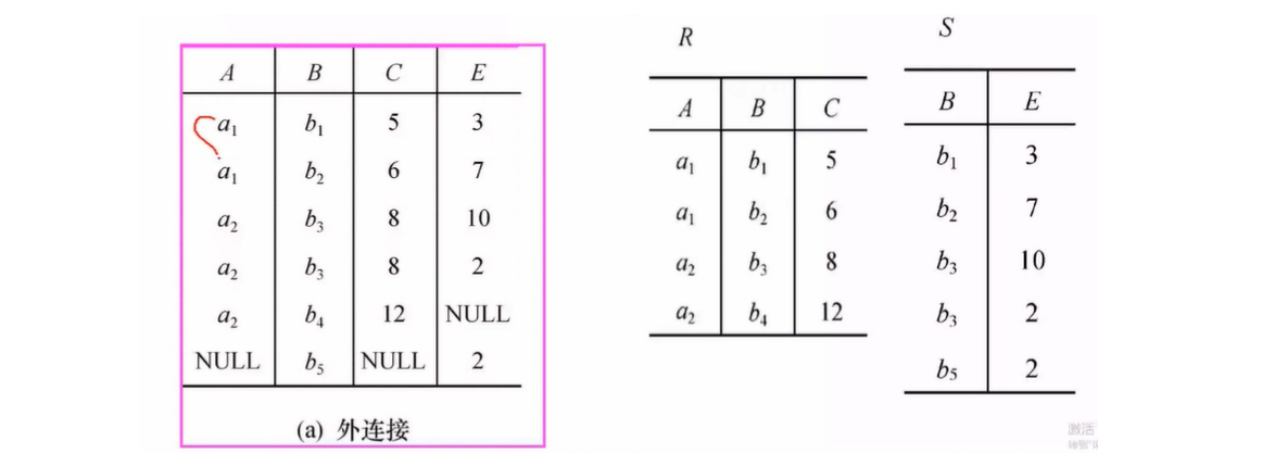
外连接分为左外连接和右外连接
2.6 课堂例题




第7章 数据库设计和E-R模型
2021/5/11
7.1 设计步骤
需求分析
概念结构设计 ER图或者是设计数据字典
逻辑结构设计 把ER图转为逻辑模型
物理结构设计 把逻辑模型转为物理模型
数据库实施 写SQL代码
7.2 实体-联系模型
E-R模型的三个要素:实体集、联系集、属性
实体(entity):在现实世界中存在并且区别于其他对象的事物或对象,
实体集(entity set):相同类型即具有相同性质的实体集合,例如大学所有教师的集合instructor
联系(relationship):指多个实体间相互关联
联系集(relationship set):相同类型联系的集合
多元联系集:相同的实体集可能会参与到多个联系集中

实体属性:实体集中每个成员所拥有的描述性性质
描述性属性:例如考虑instructor和student之间的联系集advisor,可以将属性date与该联系关联

E-R模型中的属性可以按照如下的属性类型来进行划分:
**简单/复合属性**(simple/composite):简单属性不能划分为更小的部分
**单值/多值属性**(single/multivalued):一个学生只能有一个student_id,但可以有多个tele_number
**派生属性**(derived):这类属性的值可以从别的相关属性或实体派生出来

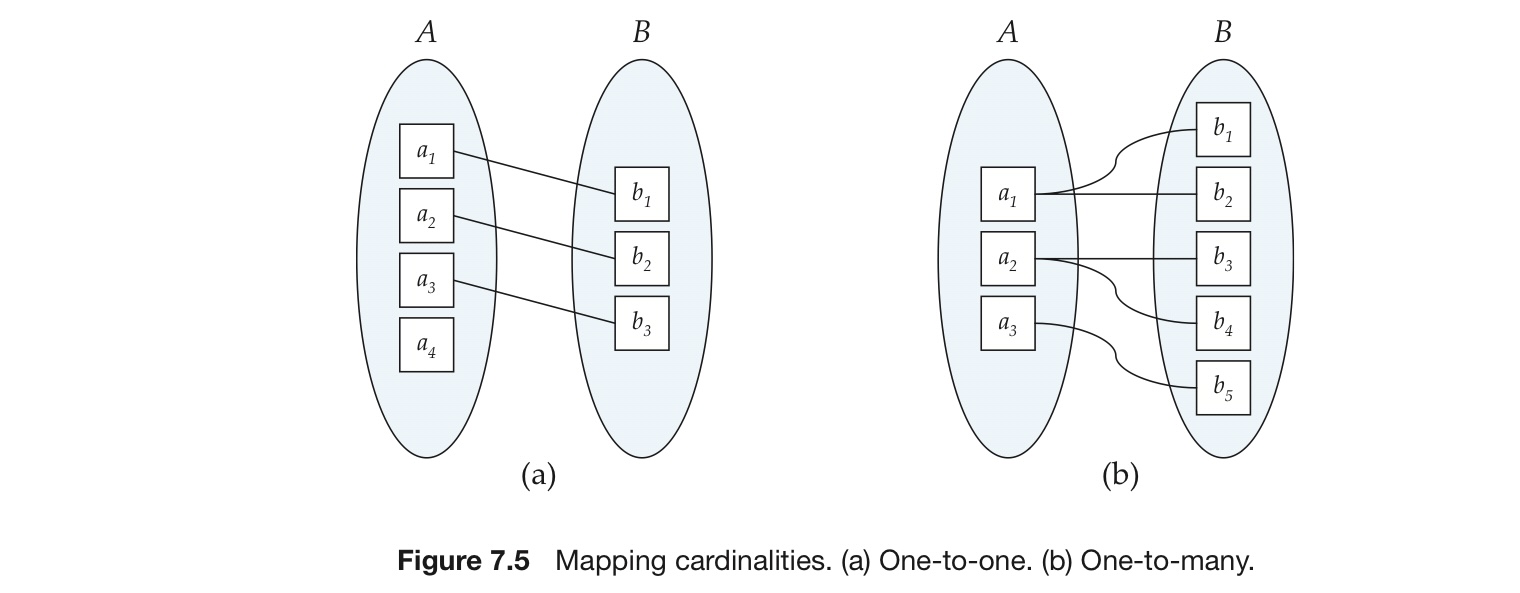
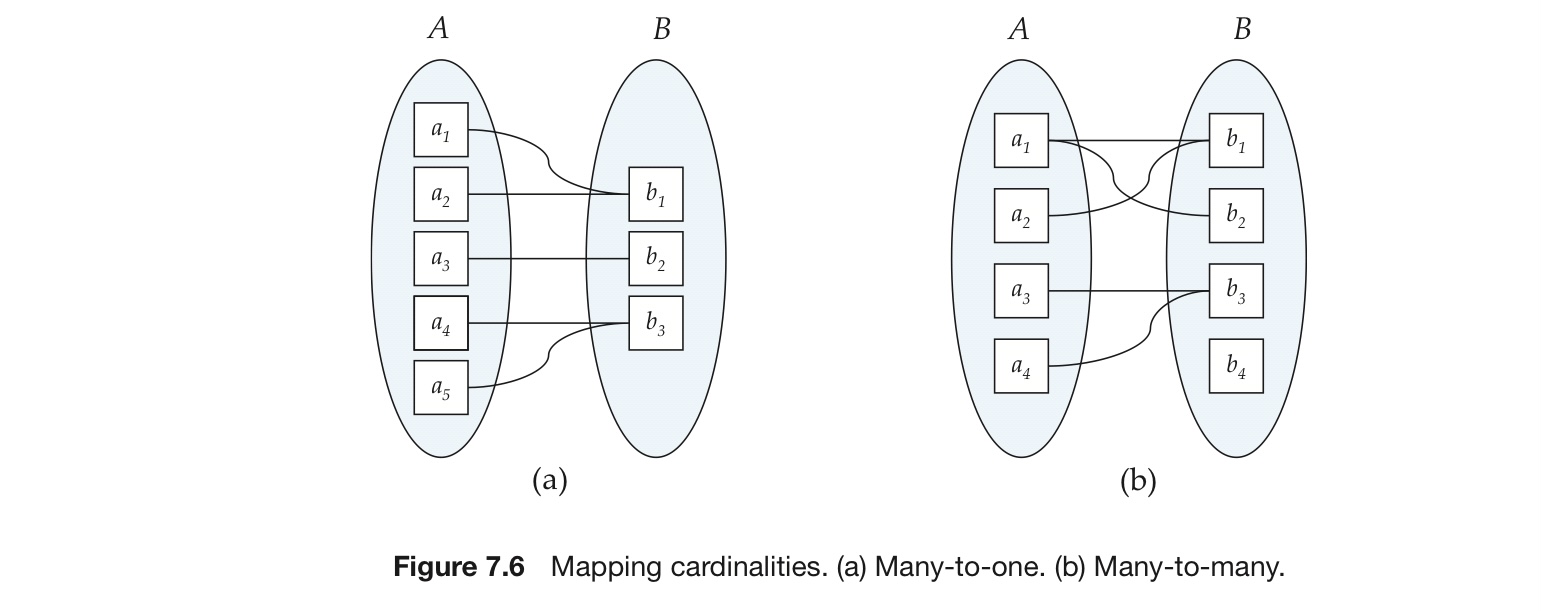
映射基数(mapping cardinality):表示一个实体通过联系集可以相关联的实体的个数
one-to-one:就任总统(总统,国家)
one-to-many:分班情况(班级,学生)
many-to-one:就医(病人,医生)
many-to-many:选课(学生,课程)
参与约束
全部参与:实体集E中的每个实体都参与到联系集R的至少一个联系中
部分参与:实体集E中只有部分实体参与到R的联系中
例如:在图7.5(a)中,B在联系集是全部参与,A是部分参与
例如:每个student都要联系至少一个instructor,但是一个instructor不是一定要指导一个学生
联系集的主码结构依赖于联系集的映射函数:
以instructor和student的联系集advisor举例
one-to-one:由instructor和student两个候选码中的任意一个作为主码
one-to-many:advisor的主码是student的主码
many-to-one:advisor的主码是instructor的主码
many-to-many:advisor的主码由instructor和student的并集组成
7.3 E-R图构建
基本结构
菱形:联系集
矩形:集的属性
线段:将实体集连接到联系集
虚线:将联系集属性连接到联系集
双线:显示实体在联系集中的参与度
双菱形:代表连接到弱实体集的标志性联系集
映射基数
用双线表示
用箭头表示
用线段上的l…h标注,l表示最小的映射基数,h表示最大的映射基数
复杂的属性
复合属性有name,address,street
其中street的子属性包括street_number, street_name, apt_number
多重属性有{phone_number}
派生属性age()

角色
实体的角色有时不止有一个
在菱形和矩形间的连线上进行标注表示角色

弱实体集
弱实体集(week entity set):实体集的所有属性都不足以形成主码
强实体集(strong entity set):具有主码的实体集
标识性联系(identifying):弱实体集必须与另一个称作标识或属主实体集的实体集关联才能有意义
注意:强实体与弱实体的标识性联系联系只能是1:1或1:N,弱实体参与联系时应该是全部参与
分辨符(discriminator):区分弱实体集中的实体的方法
弱实体集的主码由标识实体集的主码加上该弱实体集的分辨符构成
弱实体集在E-R图中的表示:
分辨符号用<u>虚线下划线</u>标明,而不是实线 关联强弱实体集的联系集用<u>双菱形</u>表示 弱实体与联系集之间画成<u>双线边</u>,联系集画<u>指向强实体集的箭头</u>.PNG)
大学中的E-R图举例
.PNG)
7.4 E-R图转化为关系模型
具有简单属性的强实体集的表示
指一对多中的多的实体集,强实体集的主码就是生成的模式的主码
比如:图7-15 student( ID, name, tot_cred )
具有复杂属性的强实体集的表示
如果是复合属性,将该属性用它的子属性们替代了
例如:图7-11 instructor( ID, first_name, middle_initial, last_name, street_number, street_name,apt_number, city, state, zip_code, date_of_birth )
如果是多值属性,新构建一个关系,包含这个多值属性,和它对应所在的实体集或联系集的主码
例如:图7-11 instructor_phone( ID, phone_number )
弱实体集的表示
主码由所依赖的强实体集的主码和弱实体集的分辨符组成
例如:图7-15 section( course_id, sec_id, semester, year )
级联删除:如果一个course实体被删除,那么所有与它相关联的section实体也被删除
联系集的表示
多对多的二元联系:该联系集属性自成一个关系,主码是参与实体集的主码的并集
一对多的二元联系:联系集的属性归到多的一方,少的一方的主码也要加到多的一方
一对一的二元联系:联系集的属性归到任意一方,另一方的主码也要加进去
边上没有箭头的N元联系集:主码是所有实体集主码的并集
边上有一个箭头的N元联系集:主码为不在箭头侧的实体集的主码

模式的冗余
一般连接弱实体集与其所依赖的强实体集的联系集的模式是冗余的,在E-R图中省略
模式的合并
多对一的联系集的和多的那一方可以合并,主码是多的那一方的主码,少的一方的主码也要加到多的一方

7.5 E-R设计问题
一个对象不能同时作为实体和属性
一个实体集不能与另一个实体集的属性相关联,只能实体与实体相关联
7.6 扩展的E-R属性
特化(specialization):在实体集内部进行分组的过程
每个特化的实体都包括实体集的所有属性以及附加属性
一个实体集可以根据多个可区分的特征进行特化,某个特定实体集可能同时属于多个特化集
在E-R图中,特化用从特化实体指向另一方的空心箭头表示,成为ISA关系
重叠特化(overlapping specialization):一个实体属于多个特化实体集,分开使用两个箭头
不相交特化(disjoin specialization):至多属于一个特化实体集,使用一个箭头
概化(generalization):高层实体集与一个或多个底层实体集间的包含关系
高层与低层实体集可以分别称作超类(superclass)和子类(subclass)
在E-R图中对概化和特化的表示不作区分,区别在于出发点和总体目标
特化从单一的实体集出发,通过创建不同的低层实体集,来强调同一实体集中不同实体间的差异性
概化是在这些实体集的共性的基础上,将它们综合成一个高层实体集,强调相似性

属性继承(attribute inheritance)
低层实体集继承高层实体集的属性
低层实体集继承高层实体集所参与的联系集
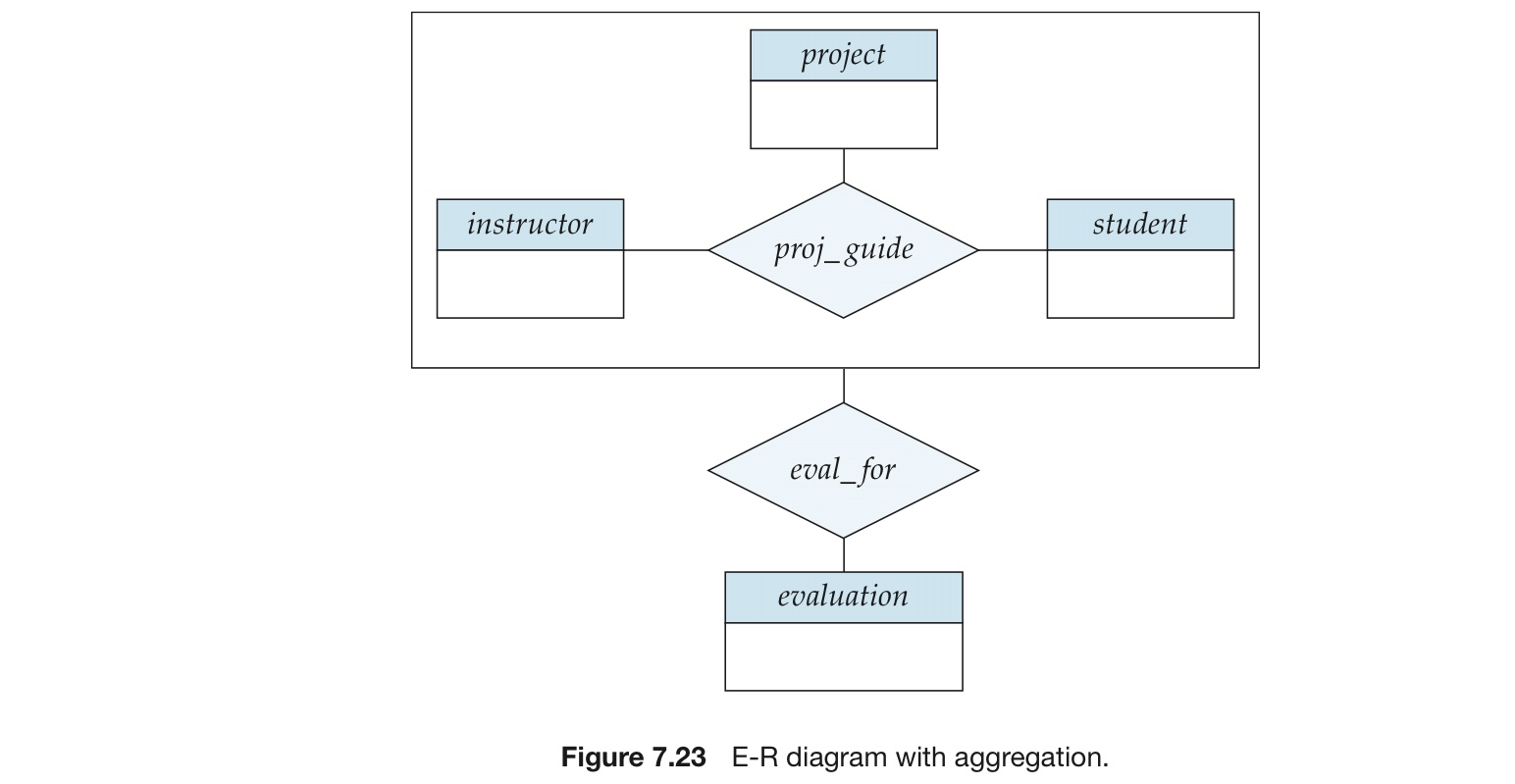
聚集(agrregation):是一种抽象,将联系视为高级实体
例如:我们将联系集 proj_guide(instructor, student, project) 看成一个高级实体集,可以像对任何其他实体集一样来处理,就可以在proj_guide和evaluation之间创建一个二元联系eval_for
概化上的约束
不相交(disjoint):一个实体至多属于一个低层实体集
重叠(overlapping):同一个实体可以同时属于一个概化中的多个低层实体集,比如某些雇员可以参加到多个工作组当中,因此是重叠的
全部概化(total generalization):每个高层实体必须属于一个低层实体集
部分概化(partial generalization):允许一些高层实体不属于任何低层实体集
.PNG)
转化为关系模式
概化的表示
为高层实体集创建一个模式,为每个低层实体集创建一个模式
person( ID, name, street, city )
employee( ID, salary )
student( ID, tot_cred )
如果概化是不相交且完全的,即如果不存在同时属于两个同级的低层实体集的实体,且如果高层实体集的任何实体也都是某个低层实体集的成员,可以不需要为高层实体集创建模式
employee( ID, name, street, city, salary )
student( ID, name, street, city, tot_cred )
聚集的表示
第8章 关系数据库设计
8.1 为什么要引入范式
数据冗余
比如姓名重复出现浪费空间
更新异常
更新后造成数据不一致,比如班主任换名字,每个学生对应的每行都得换
插入异常
应该插入的无法被插入
删除异常
不该删除的被删除了
所以我们引入一个规范的方法判断一个关系模式是否应该分解
8.2 概念
8.2.1 符号表示法
用希腊字符 $\alpha$、$\beta$ 等表示属性集,用小写罗马字母后括住大写字母 $r(R)$ 指关系模式
当属性集是一个超码时用K表示,超码属于特殊的关系模式
8.2.2 码的概念
超码 (super key):能推出所有属性的属性集,唯一能够标识整条元组的属性集。R的子集K是 r(R) 的超码的条件是:在关系 r(R) 的任意合法实例中,对于r的实例中的所有元组对t1和t2总满足,若t1 != t2,则t1[K] != t2[K]
候选码:可以推出所有的属性,但是他的任意一个真子集无法退出所有的属性,候选码是最小的超码
主码:从候选码中任意挑一个作为主码
主属性:包含在任意一个候选码中的属性,如下题的ABCDE
非主属性:不包含在任意一个候选码中的属性,如下题的G
码:把主码、候选码简称为码
全码:如果所有属性都是码,成为全码
求候选码的步骤:
step1:只出现在左边的一定是候选码
step2:只出现在右边的一定不是候选码
step3:左右都出现的不一定
step4:左右都不出现的一定是候选码
step5:求确定的候选码的闭包(closure,指由他可以推出来的所有属性),如果可以推出全部,那么当前确定的就是候选码。否则就把每个可能的码,放进当前确定的候选码里面进行求闭包
例题:
####8.2.3 函数依赖 (function dependency)

最小函数依赖集:即F中的每个依赖,都不可以被其他依赖推出
step1:把右边的元素拆分成单个的
step2:除去当前元素,求它的闭包,把集合里面所有元素一一排查
step3:左边最小化(通过遮住元素来看能不能推出其他元素),比如BCD,遮住B看能不能推出B,再遮住C/D

8.3 范式
1NF:原子性,不可分割
2NF:不存在非主属性对码的部分函数依赖
3NF:不存在非主属性对码的传递函数依赖,全码一定是3NF
BCNF:主属性和非主属性都不存在对码的部分函数依赖和传递函数依赖
4NF:关系模式R属于第三范式,且消除了非主属性对候选键以外属性的多值依赖。
BCNF 消除了所有基于函数依赖能够发现的冗余,具有函数依赖集F的关系模式R属于BCNF的条件是,对F+中所有形如 $\alpha \rightarrow \beta$ 的函数依赖下面至少有一项成立:$\alpha \rightarrow \beta$ 是平凡的函数依赖,或 $\alpha$ 是模式 R 的一个超码
范式判断:
求候选键,和主属性/非主属性
非键属性是否部分依赖于候选键
部份依赖是指如果候选码是AB非键C,如果在F中找到A→C或者B→C,就是部分依赖
如果是:1NF
如果否:往下走
非键属性是否传递依赖于候选键
如果是:2NF
如果否:往下走
所有依赖项的左边是否全为候选键
如果是:BCNF
如果不是:3NF
8.4 函数依赖理论
8.4.1 函数依赖集的闭包
逻辑蕴含(logically imply):如果函数依赖集 F 能推出函数依赖 f ,则称 f 被 F 逻辑蕴含。
函数依赖集的闭包(closure):令F为一个函数依赖集,F的闭包是被F逻辑蕴含的所有函数依赖的集合,记作F+
8.4.2 Armstrong公理

8.4.3 属性集的闭包 (Attribute Closure)

8.4.4 正则覆盖 (Cononical Coverage)

8.4.5 无损分解(lossless decompositon)

判断无损分解:
当且仅当只被分解为两个关系时:

当分解为多个关系时:


####8.4.6 保持依赖
判断是否保持依赖:对于关系模式R(U,F),设R1(U1, F1), R2(U1,F2), … Rn(Un, Fn)是R的分解,若F的闭包等于$F1\cup F2\cup …\cup Fn$ 的闭包,则称该分解是保持函数依赖

8.5 范式分解算法
模式分解的要求:
- 无损连接性:具有无损连接性的分解不一定能够保持函数依赖
- 保持函数依赖:保持函数依赖的分解不一定具有无损连接性
模式分解步骤:
求候选码
求3NF分解
求最小函数依赖集
把最小函数依赖集箭头前后的元素写在一起作为一个Ri
求BCNF分解
INPUT 关系模式R以及函数依赖集F,初始化 P={R}
若P中的所有关系模式S都是BCNF,则转步骤(4)
若P中有一个模式S不是BCNF,则S中必能找到一个函数依赖X→Y,X不是S的候选码,且Y不属于X(根据BCNF的定义)
设S1 = XY,S2 = S-Y,分解后的{S1, S2}代替S,转步骤(2)
END


第十章 存储和文件结构
10.1存储设备基础
(属性、排序、效率、在整个体系架构里的位置)
高速缓冲存储器>主存储器>快闪存储器>磁盘>光盘>磁带
10.2 磁盘部分的概念
(11章12章会涉及)
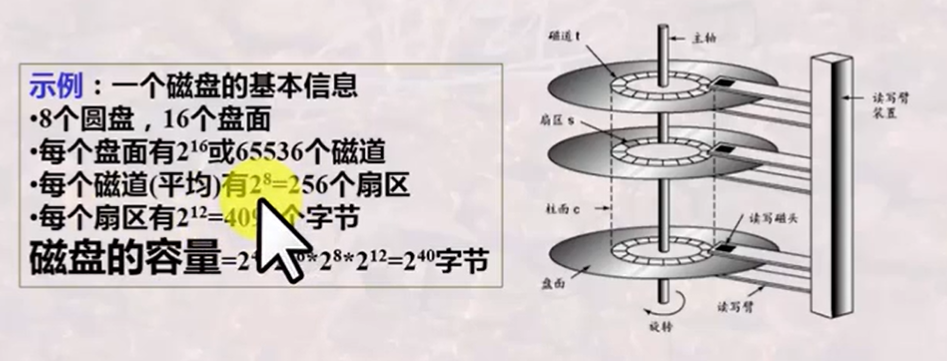
扇区section 磁道track 读写头 read-write head
磁盘臂 disk arm 柱面 cylinder
扇区是从磁盘读出和写入信息的最小单位
RAID:独立磁盘冗余阵列
作用:通过冗余提高可靠性(奇偶校验),通过并行提高性能
磁盘性能的度量:访问时间,寻道时间,平均寻道时间,数据传输率,平均故障时间

10.5 文件组织
定长记录:
变长记录:分槽的页结构
10.6 文件中记录的组织
堆文件组织 顺序文件组织 散列文件组织
第十一章 索引与散列
11.1 基本概念
顺序索引
散列索引




:star:11.2 顺序索引
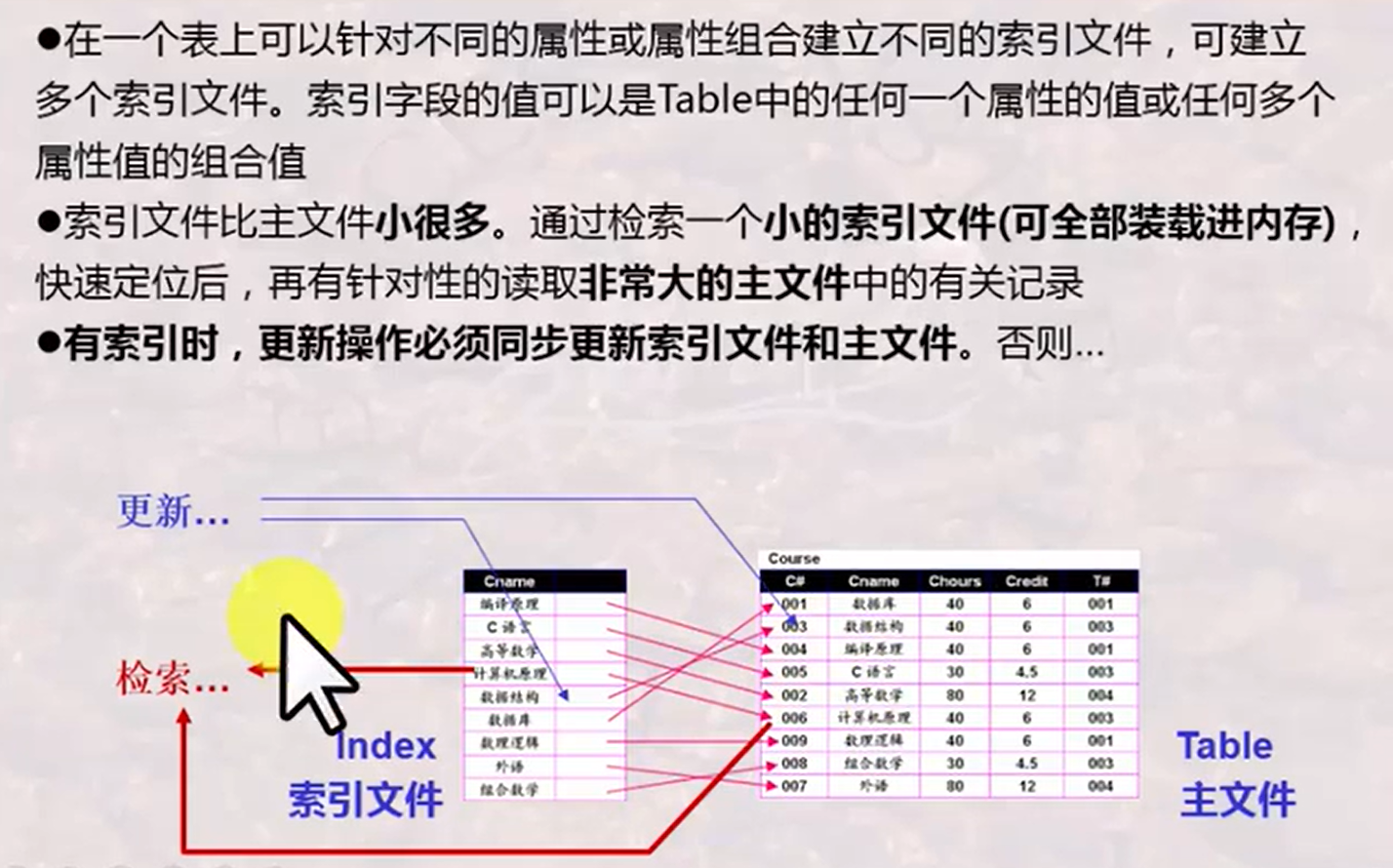
主索引和辅助索引 primary index/secondary index
又叫聚集索引和非聚集索引 clustering index/nonclusering index
包含记录的文件按照某个搜索码指定的顺序排序,该搜索码对应的索引成为聚集索引
搜索码指定的顺序与文件中记录的物理顺序不同的索引成为非聚集索引



稠密索引和稀疏索引 dense index/sparse index
稠密索引:文件中每个搜索码值都有一个索引项
稀疏索引:只为搜索码的某些值建立索引项,只有索引是聚集索引(当关系按照搜索码排列顺序存储时)才能使用稀疏索引



11.3也是重点 b+树 基本组成 结构 在查询里面的作用 怎么插入删除节点 (考察重点)::star:




插入节点



11.4 不过多考察
hash部分跳过
第12章 查询处理
首先了解基本概念 为什么要做查询处理 实际上是对应怎么去磁盘取数据
12.1 概述
代价取决于两个因素:执行的算法、数据库目录中的统计信息估计成本
12.2 查询代价 Query Cost
查询处理的代价包括:磁盘存取,执行一个查询所需要的CPU时间,在并行/分布式数据库系统中的通信代价
用传送磁盘块数以及搜索磁盘次数来度量查询计划的代价:
假设瓷盘子系统传输一个块的数据平均消耗t_T秒,磁盘平均访问时间(磁盘搜索时间+旋转延迟)为t_S秒,则一次传输b个块,以及执行S次磁盘搜索的操作将消耗(bt_T+St_S)秒。
其中t_T和t_S必须针对所使用的磁盘系统来计算
通果把读磁盘块和写磁盘块区分开,可以进一步细化磁盘存取代价的估算。
本书给出的代价没有包括将操作最终写回磁盘的代价,当需要时需要单独考虑。
本书所考虑的算法代价依赖于主存中缓冲区的大小
最好的情形是所有的数据都可以读入到缓冲区中,不必再访问磁盘
最坏的情形是假定缓冲区只能容纳数目不多的块——大约每隔关系一块
在代价估算时,通常假定最坏的情形
12.3 选择运算
表格有点问题: a3 a5要加一个传输 寻道时间
在b+树去做index,查到叶子节点,就是树的高度
后面算法的比较不过多涉及
复合查询有一些概念就好
12.4排序
外部归并排序 有个概念就好
12.5 join
是重点 主要考察的是前几种
第13章 查询优化
主要考察前面几节
13.1 概述

13.2 关系表达式的转换
等价转换的规则
13.3 根据统计信息做估计 (不特别明确的考察但是大家要有概念)
有时候带有比较大的误差 不明确考察但是要有概念
后面跳过
第14章 事务 transaction
14.1 概念
构成单一逻辑工作单元的操作集合称作事务
事务是访问并可能更新各种数据项的一个执行单元
事务调度 schedule:一组事务的基本步(读写、锁解锁)的一种执行顺序称为对这组事务的一个调度
ACID property:
原子性 atomicity
隔离性 isolation
持久性 durability
一致性 consistency
14.4 生命周期
活动的 active:初始状态
部分提交的 partially committed:最后一条语句执行后
失败的 failed:发现正常的执行不能继续后
中止的 aborted:事务回滚并且数据库已恢复到事务开始执行前的状态后
提交的 committed:成功完成后
14.6 可串化
冲突可串化 conflict serializability
当i,j是不同事务在相同的数据项上的操作,并且其中至少有一个是write指令,则IJ是冲突的
冲突等价 conflict equivalent:如果调度S可以经过一系列非冲突指令交换转换成S‘,我们称S与S’是冲突等价的
冲突可串行化 conflict serializability:如果调度S与一个串行调度冲突等价,则称调度S是冲突可串行化的
满足冲突可串行性,一定满足可串行性,反之不然
优先图 precedence graph (前驱图)
每个事务是一个节点,每个有冲突的操作是一条边,如果没有环就是冲突可串行化的


14.7以后都是概念为后面做准备
14.8 不考察14.9 14.10也
第15章 并发控制
15.1 加锁协议
共享的shared S
排他的 exclusive X
可以让多个事务读取一个数据项但是限制同时只能有一个事务进行写操作
相容函数 compatibility function
封锁协议 locking protocol:规定事务何时对数据项们进行加锁、解锁,限制了可能的调度数目



两阶段封锁协议 two-phase locking protocol
要求每个事务分成两个阶段提出加锁和解锁的申请
1.增长阶段 growing phase 事务可以获得锁,不能释放锁
2.缩减阶段 shrinking pahse 事务可以释放锁,不能获得新锁
保证了冲突可串行化
严格两阶段封锁协议:所有排他锁必须在事务提交后方可释放
强两阶段封锁协议:要求事务提交之前不得释放任何锁

15.2 死锁处理
1.通过对加锁请求进行排序或要求同时获得所有的锁来保证不会发生循环等待
2.每当等待有可能导致死锁,进行事务回滚而不是等待加锁
15.3 多粒度
怎么在并发调度里面加锁
死锁的概念
两个阶段的加锁协议(必考)
锁的实现看一看就好
graphbase协议不考了
死锁处理知道概念就好
等待图
15.4 时间戳



第16章 恢复系统
16.1 概念
恢复算法是出现故障时确保数据库一致性、事务原子性和持久性的技术
故障分类
transaction failure,system crash,disk failure
存储器
volatile storage
nonvolatile storage
stable storage
16.3 恢复与原子性
使用数据库的两种方法
deferred database modification 延迟的数据库修改
immediate database modification 立即的数据库修改











undo/redo



16.4 肯定要重点考察
16.5 之后涉及到buffer情况 修正 了解就行 不做重点考察的内容
这一章比较简单